







注意力机制的本质思想:
source:我 是 中国人
target: I am Chinese
如果翻译单词I时,则Query为I,source中的 “我” “是” “中国人”都是K,而V代表每个source中输出的context vector,如果为RNN模型的话就是对应的状态向量;即key与value相同
QKV是分别是embeding*Wq,Wk,Wv
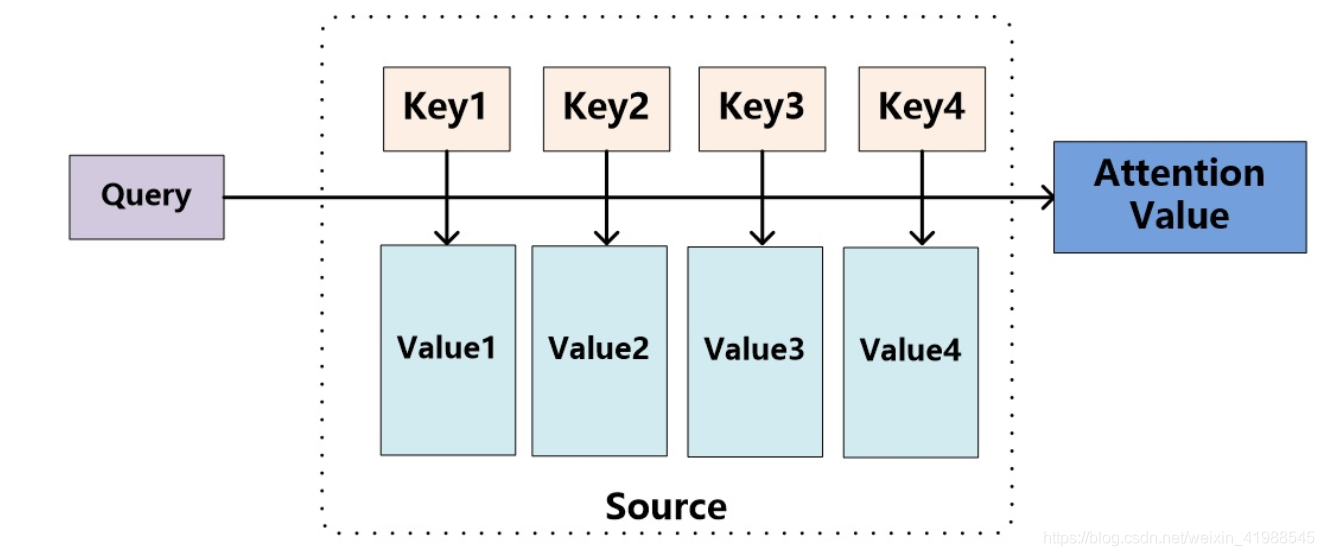
将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。即可以将其本质思想改写为如下公式:
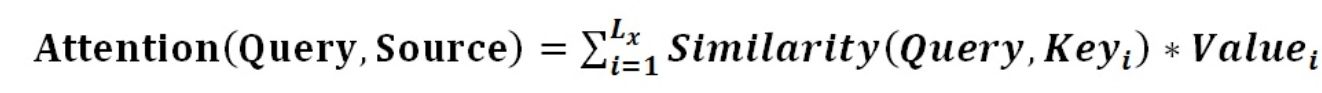
Lx代表source长度
上文所举的机器翻译的例子里,因为在计算Attention的过程中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。
Attention的计算过程:
如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:
第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为下图展示的三个阶段。
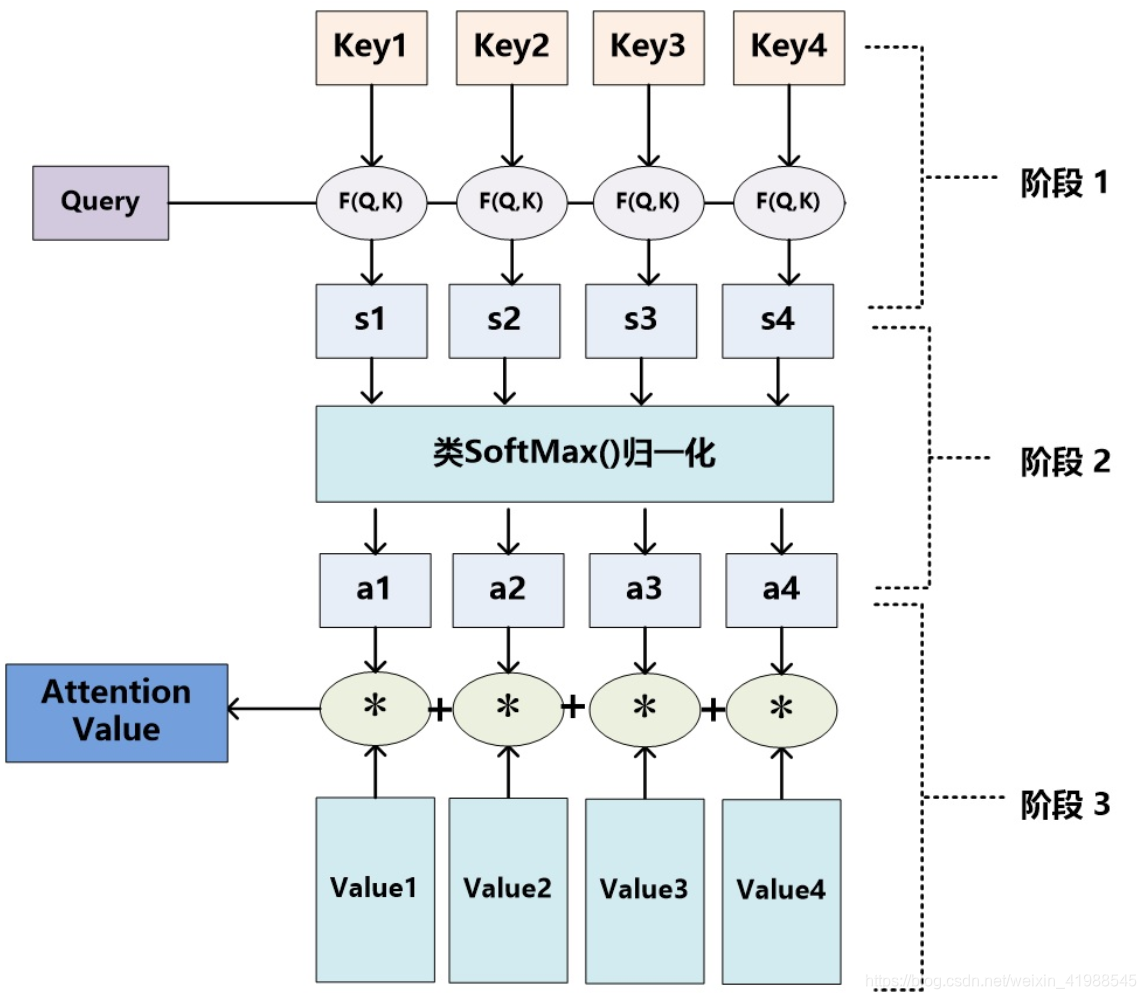
第一个阶段,可以引入不同的函数和计算机制,根据Query和某个 ,计算两者的相似性或者相关性
,计算两者的相似性或者相关性
最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

这一步的计算方法通常有以下四种:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样
第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:
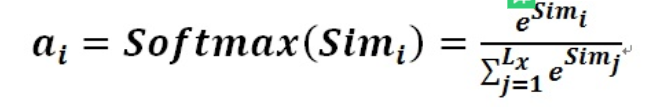
第二阶段的计算结果 即为
即为 对应的权重系数,然后进行加权求和即可得到Attention数值:
对应的权重系数,然后进行加权求和即可得到Attention数值:
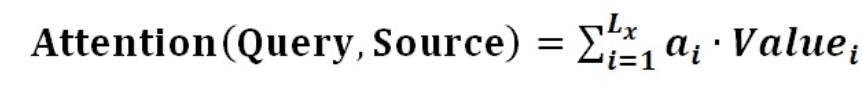
而V代表每个source中输出的context vector
论文:Attention is all you need

Multi-Head Attention
只对QKV进行一次权重操作是不够的,所以需要进行多次

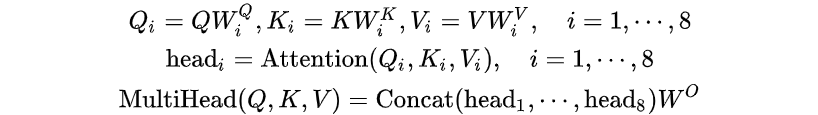


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









