






自注意力机制,本句单词和本句其他单词的关系
公式
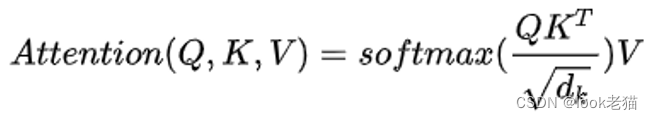
为了简单假定 Q矩阵 K矩阵一样
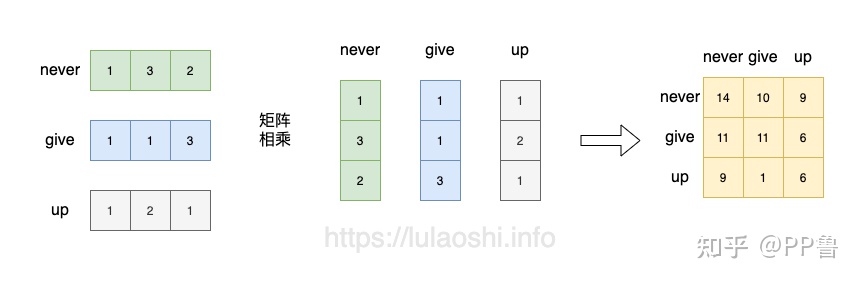
Q K转置 Q*K转置
可以这么理解 Q 与K转置相乘,就是各个向量的内积,再除以内积的QK的模
cos=(ab的内积)/(|a||b|) ,实际是各向量的夹角。
=3*3 K的维度的平方,3个单词。
softmax应用在每行计算方法为/(
+
+
)
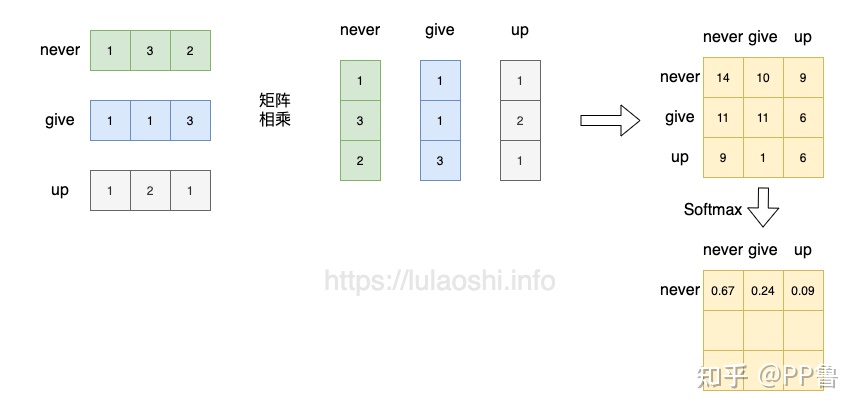
首先变成单位向量,模为1,内积就是夹角的余弦。图中明显,never向量 与 never向量的余弦值为1,向量完全共线。
知乎看到图片觉得不错。但是总觉得有问题。应该执行单位化,不然无法计算出相关性,
我的源码如下:
#-------------------------------------------
import torch
import torch.nn.functional as F
t11=torch.tensor([[1.0,3,2],[1,1,3],[1,2,1]]) #有3个向量
t22=torch.tensor([[1.0,3,2],[1,1,3],[1,2,1]])
t11=F.normalize(t11) #默认dim=1 按行向量单位化
t22=F.normalize(t22)
print(torch.mm(t11 , t22.T)) #mm = matrix multi 矩阵乘法
#------------------------------------------------------------------------
执行结果为:
tensor([[1.0000, 0.8058, 0.9820],
[0.8058, 1.0000, 0.7385],
[0.9820, 0.7385, 1.0000]])
# 红色的1.00 表示 t11 第一个向量与 t22第一个向量完全相关,本质是向量夹角为0,内积为1(都是单位向量)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









