 Q、K、V与Transformer多头注意力解析,
Q、K、V与Transformer多头注意力解析,





 本文介绍了Transformer中的Q、K、V概念,它们在自注意力机制中的作用以及多头注意力的原理。通过线性变换生成查询、关键和数值向量,多头注意力通过组合多个head增强模型的理解能力。
本文介绍了Transformer中的Q、K、V概念,它们在自注意力机制中的作用以及多头注意力的原理。通过线性变换生成查询、关键和数值向量,多头注意力通过组合多个head增强模型的理解能力。
目录
Transformer大行其道,在众多领域取得了不可忽视的成就。如今大火的语言大模型LLM也都是基于Transformer,但是Transformer中的Q、K、V和多头注意力到底是什么呢?这里简单做个学习记录,进行再一次认识和掌握。
一.什么是Q、K、V
Transformer中的Q、K和V是指在自注意力机制(self-attention mechanism)中使用的三个输入表示向量。
Q表示查询向量,K表示关键向量,V表示数值向量。这三个向量是通过线性变换从原始输入向量(通常是词嵌入表示)得到的。
在自注意力机制中,以查询向量Q为基础,通过计算查询向量与所有关键向量K之间的相似度,得到一个权重分布,用于加权求和关联的数值向量V。
Q、K、V概念来源于检索系统,其中Q为Query、K为Key、V为Value。可以简单理解为Q与K进行相似度匹配,匹配后取得的结果就是V。举个例子我们在某宝上搜索东西,输入的搜索关键词就是Q,商品对应的描述就是K,Q与K匹配成功后搜索出来的商品就是V。
Transformer中,注意力的核心公式是
![]()
,那Q、K、V是怎么来的呢?这里其实是通过对输入矩阵X进行线性变换得到的,用公式可以简单写成以下:
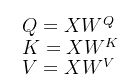
用图片直观表示为:
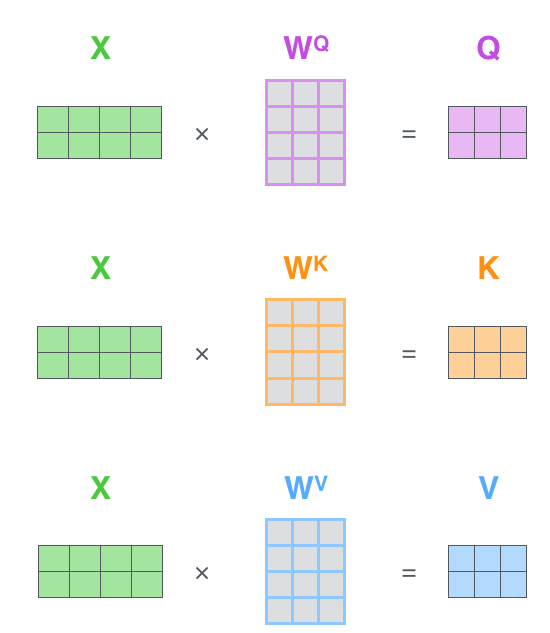
其中![]() 、
、![]() 、
、![]() 是三个可训练的参数矩阵,输入矩阵X分别与三个矩阵参数进行相乘,相当于进行一次线性变换,得到了Q、K、V。
是三个可训练的参数矩阵,输入矩阵X分别与三个矩阵参数进行相乘,相当于进行一次线性变换,得到了Q、K、V。
然后使用Q、K、V计算注意力矩阵,公式如下:
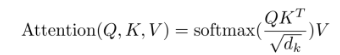
论文中给出的图如下:
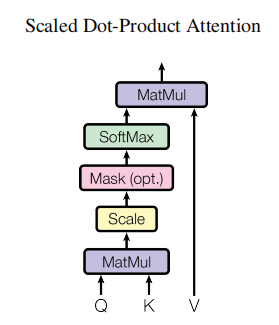
Q和![]() 经过MatMul,生成了相似度矩阵。对相似度矩阵每个元素除以
经过MatMul,生成了相似度矩阵。对相似度矩阵每个元素除以![]() ,
,![]() 为
为![]() 的维度大小。这个除法被称为Scale。当
的维度大小。这个除法被称为Scale。当![]() 很大时,
很大时,![]() 的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。然后经过SoftMax,最后与V做一个MatMul操作得到结果。
的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。然后经过SoftMax,最后与V做一个MatMul操作得到结果。
二.Mutil-Head Self-Attention
上文理解了Q、K、V及其它们的由来,那多头注意力是什么呢?
Transformer论文中给出的多头注意力公式如下:
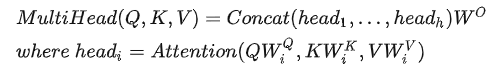
从公式可以看出,多头注意力就是将多个head进行Concat然后与![]()
相乘。其中每个head是由
![]()
与Q、K、V做Attention操作得到。论文给出的图如下:
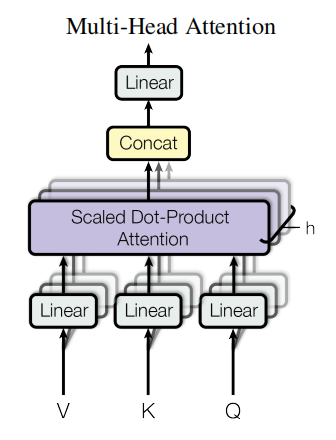
Q、K、V经过Linear然后经过h个Self-Attention,得到h个输出,其中h指的是注意力的头数。h个输出进行Concat然后过Linear得到最终结果。

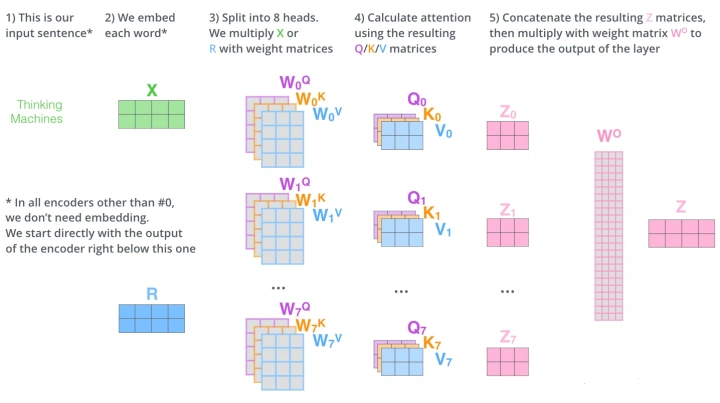
那么就得到了多组Q、K、V,每一组就是一个head。
下面引用B站作者霹雳吧啦Wz的内容进行讲解。
先做个铺垫如下图
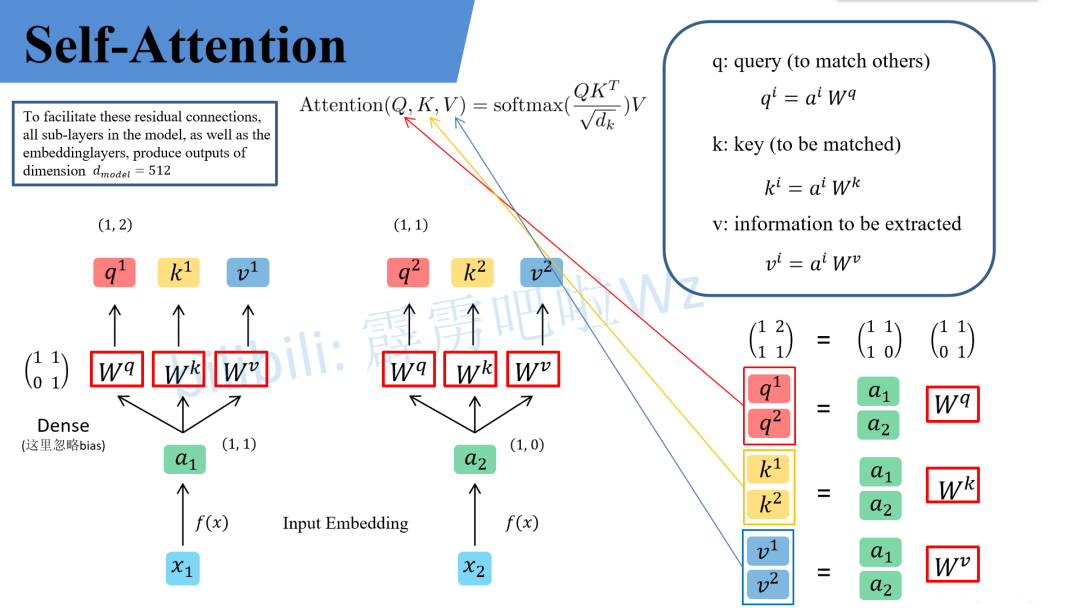

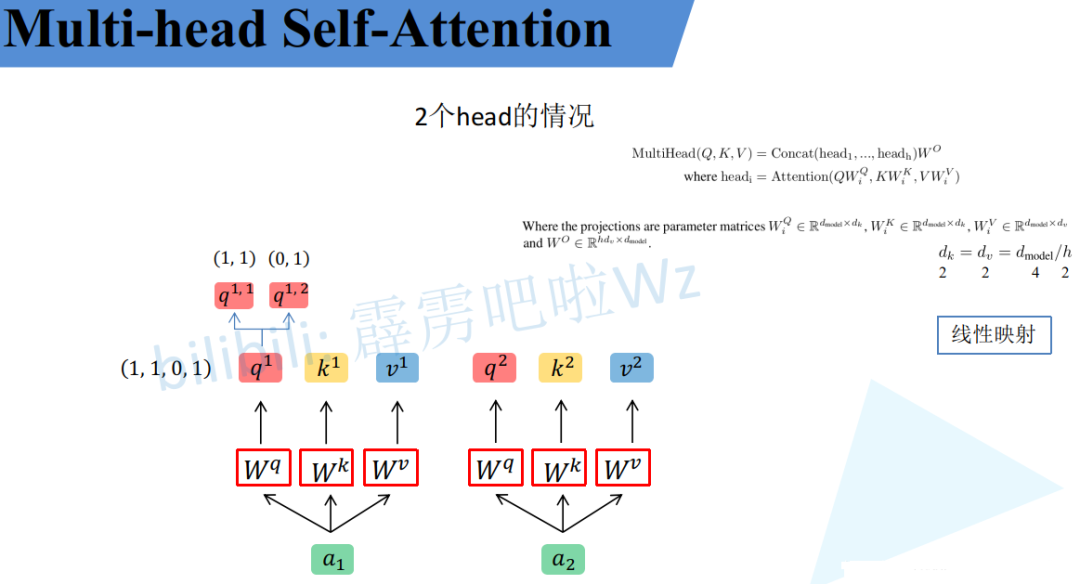

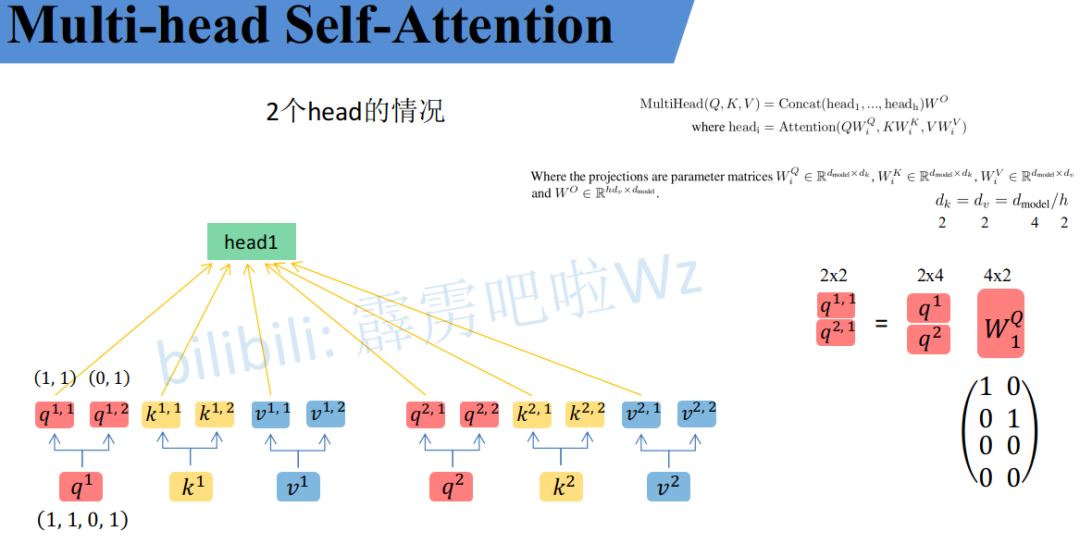
同理也会得到不同输入的2个head中的head2。如下图
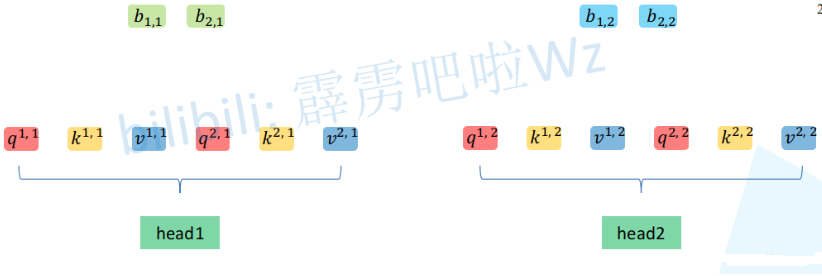
左侧是x1、x2输入的head1,右侧是x1、x2输入的head2,b是偏置。
致此,就得到了每个
![]()
对应的
![]()
参数。接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。
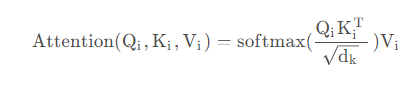
接着将每个head得到的结果进行concat拼接,接着将拼接后的结果通过
![]()
(可学习的参数)进行融合。
从上可以看出,每个head关注的子空间不一定是一样的,那么这个多头的机制能够联合来自不同head部分学习到的信息,这就使得模型具有更强的认识能力。
更多的头数意味着更强大的模型能力,比如LLM大模型Baichuan-13B中的head数目是40,而Baichuan-7B中的head数目是32。



















 2165
2165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











