








 超级会员免费看
超级会员免费看


 本文介绍了使用Python和Keras在OpenAI Gym环境中实现深度Q-Learning的过程,探讨了深度Q-Learning的原理、挑战,以及如何通过目标网络和经验回放解决这些问题。通过实现一个能够玩CartPole游戏的智能体,展示了深度强化学习的实际应用。
本文介绍了使用Python和Keras在OpenAI Gym环境中实现深度Q-Learning的过程,探讨了深度Q-Learning的原理、挑战,以及如何通过目标网络和经验回放解决这些问题。通过实现一个能够玩CartPole游戏的智能体,展示了深度强化学习的实际应用。
Introduction
我一直对游戏着迷。 看似无限的选择可以在紧迫的时间线下执行一个动作 - 这是一个惊心动魄的经历。 没有什么比得上它了。
因此,当我读到DeepMind想出的令人难以置信的算法(如AlphaGo和AlphaStar)时,我被迷住了。 我想学习如何在自己的机器上制作这些系统。 这使我进入深度强化学习的世界(Deep RL)。
即使您不参与游戏,Deep RL也很重要。 只需查看目前使用Deep RL进行研究的各种功能:
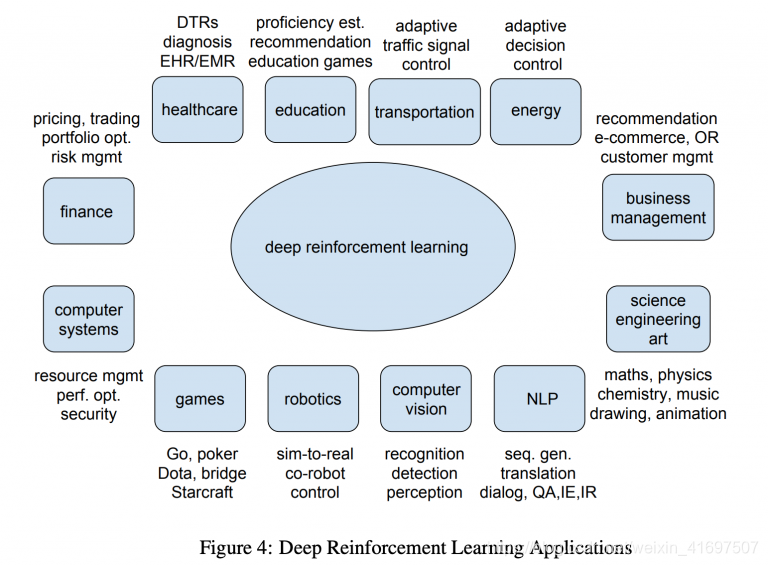
适合行业的应用程序呢? 好吧,这里有两个最常被引用的Deep RL用例:
- 谷歌的Cloud AutoML
- Facebook的Horizon Platform
Deep RL的范围是IMMENSE。 这是进入这一领域并从中创造事业的好时机。
在本文中,我的目标是帮助您迈出深度强化学习的第一步。 我们将使用RL中最流行的算法之一深度Q学习来了解RL的深度。 锦上添花? 我们将使用Python在一个很棒的案例研究中实现我们所有的学习。
Table of Contents
- The Road to Q-Learning
- Why ‘Deep’ Q-Learning?

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











