







 本文详细介绍了线性判别分析(LDA)的原理,包括二类LDA和多类LDA的理论,以及LDA的算法流程。LDA是一种监督学习的降维技术,目标是使得类内方差最小,类间方差最大,常用于模式识别领域。文章还提及LDA对数据的正态性和独立性的假设及其在实际应用中的鲁棒性。
本文详细介绍了线性判别分析(LDA)的原理,包括二类LDA和多类LDA的理论,以及LDA的算法流程。LDA是一种监督学习的降维技术,目标是使得类内方差最小,类间方差最大,常用于模式识别领域。文章还提及LDA对数据的正态性和独立性的假设及其在实际应用中的鲁棒性。
在主成分分析(PCA)原理总结中,对降维算法PCA做了总结。这里我们就对另外一种经典的降维方法线性判别分析(Linear Discriminant Analysis, 以下简称LDA)做一个总结。LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用,因此我们有必要了解下它的算法原理。
思想:
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据 分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。

上图中国提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,我们的数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
二类LDA原理
现在我们回到LDA的原理上,我们在第一节说讲到了LDA希望投影后希望同一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大,但是这只是一个感官的度量。现在我们首先从比较简单的二类LDA入手,严谨的分析LDA的原理。
二类分类数据集:![]()
其中xi为m维列向量,我们定义两类为C1和C2,即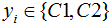 ,对应的样本集个数分别为
,对应的样本集个数分别为![]() 和
和![]() 。
。
根据上一节的LDA的优化目标函
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5249
5249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









