







引出
机器翻译的变化
以前:基于人工统计的规则来翻译 -> 现在:用机器学习来学习出统计的规则来翻译
之前的机器翻译的缺点:
- 计算速度慢
- 语义不通问题
- 语法错误问题
解决语法问题
例如:翻译“今晚的课程有意思”
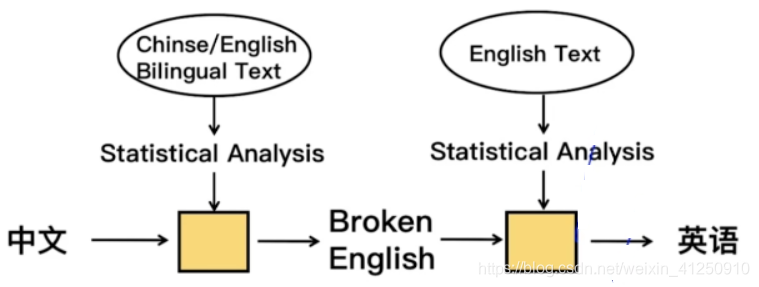
首先,先分词为“今晚/的/课程/有意思”,对应词典里面的对应翻译为“Tonight of the course interesting”,即Broken English。
然后,将所有单词进行排列组合,罗列出所有可能性,然后选出最适合的句子。使用一些模型(或者叫选择器),例如LM(language model语言模型),可以计算出每个句子最优的概率,选择概率最高的句子。
致命的缺点:计算量太大了,单词少可以,单词多了,再阶乘,我的天呐!即,算法复杂度太高。
我们尝试把两个步骤(即两个黄色方框):Translation model + Language model 合二为一 即:Decoding A lgorthm 典型:Viterbi Algorthm(维特比算法),后续会详细讲解。

NLP设计的应用场景:
- 机器翻译
- 问答系统
- 情感分析
- 自动提取摘要
- 聊天机器人
- 信息抽取
自然语言处理技术的四个维度:
声音->Morpholgy单词->Syntax句子结构->Semantic语义
设计技术算法:
Morpholgy单词:分词,词性标注,NER(命名实体识别)
Syntax句子结构:句法分析,依存分析
Semantic语义:机器学习

对现有的NLP问题的一个比较好的总结。

















 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









