




 本文介绍了一种结合变分自动编码器(VAE)与U-Net网络的方法,用于图像中物体姿态的转换。该方法能够从少量样本中提取物体的形状信息并生成不同姿态下的图像。
本文介绍了一种结合变分自动编码器(VAE)与U-Net网络的方法,用于图像中物体姿态的转换。该方法能够从少量样本中提取物体的形状信息并生成不同姿态下的图像。
嘿嘿,各位看官,看了快一个月的ReID,今天给大家伙儿换换口味,欢迎新人GAN家族。。。。。
言归正传,深度生成网络在图片生成模型中有着很重要的作用。然而由于空间信息的丢失,往往都是通过图片来直接生成图片,而不是他们的固有的形状和外观。在这篇文章中作者使用了一个conditional unet网络进行形状指导下的图片生成,他的输出对外观进行自动编码。这个方法的优点是不需要同一个物体的不同照片而能够接见不同物体的不同表现对这个进行生成。以上这些可能讲的不是特别像人话,下面对比下图,我用简单的语言给大家讲讲。

大家看这张图,最左侧一列是不同场景下下的人像,假如这时候我们希望对其中的一个人进行不同场景不同姿态的图像生成,那么这必定是一个及其困难的问题,因为我们只有这个人的极少的图片,那么本文解决的就是这个问题,首先从不同图像中提取出y,这个代表姿态的东西,然后利用一个图片和一张姿态特征图作为一个pair,然后本文提出的框架将图片按照姿态图的模式转换到目标图。
方法及推导
假设x是数据集X中的一个object,我们希望连接形状y以及表现z对于图片的影响。尽管y精确地语义可能会有不同,但是我们认为y代表了集合信息,位置信息,形状信息以及姿态信息,而z表示一些内在的因素。如果y和z包括了图片所有的变化量,那么对于生成图片唯一的影响就是噪声了,那么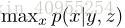 这个函数可以理解为一个图片生成器。
这个函数可以理解为一个图片生成器。
1、基于隐形形状和表现的变分自动编码器(VAE)
如果y和z都是隐形变量,一个流行的学习生成器的方式就是VAE。我们要去最大化关于x的最大似然函数并且区分开隐形变量y和z。为了避免积分的困难,有人引入了先验概率去获得相应的积分下限通过jensen散度:
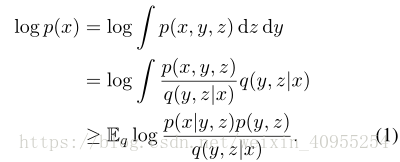
方程中包含了先验概率p(y,z),他在VAE中被认为是标准的正态分布。有这个联合分布,我们就没法保证变量y和z是独立的。那样的话上述要求他们两分开的目的就没法达到。所以我们需要添加额外的信息来对y和z进行划分。
2、基于z的条件VAE
再上一个章节我们发现了有两个隐形变量的VAE不适合用来学习y和z之间的margin。相反我们认为我们有一个对于y的估计函数y_=e(x)。例如,e可以通过提取边缘或者自动估计身体关节位置来提供关于shape y的信息。所以现在函数变成了从输入以及y对z进行最大似然估计:
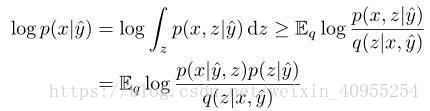
与方程1对比,我们可以发现方程二决定于条件先验概率p(z/y_)。这个分布是可以通过训练数据以及来获得y和z之间的潜在关系。比如,一个跳跃的人穿tshirt的可能性要大于穿厚夹克的可能性。
我们将p(x/y_,z)定义为参数化的拉普拉斯方程,将q(z/x,y_)定义为高斯分布,这两个分布的参数通过两个函数F和G来实现,这两个模型可以端到端训练,并且损失函数定义如下:
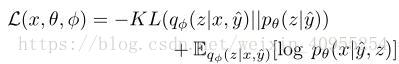
/3、关于生成器函数G
上街所说,生成器G是用来估计p(x/y_,z)的参数的。我们可以看得更加长远一点,这个分布有着连续的标准分布并且G是关于y_的确定函数,所以这个模型可以被视为是一个图片的生成器模型,于是用 L(x,θ) = kx − G θ (ˆ y,z)k 1 去替换损失函数中的第二个部分,所以损失函数就变成:
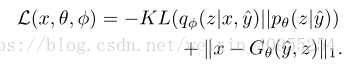
大家都知道,像素级的描述函数并不能很好地描述模型的质量,所以文章中引入了另外一种表示方法,目标函数变化如下;
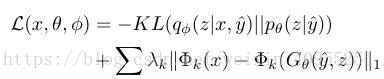
Φ在我们的例子中是一个vgg19的模型,用来计算precepture的相似性, λ k ,k 是超参数,控制不同层对于最终损失函数的影响。
这时候如果我们忘掉z,那么G这个模型就是在一个输入图片和姿态的情况下,生成相应的图片。这里有个很重要的点,我们最后所获得的y_我们希望他既有输入图片的一些固定变现,又与输入的相应姿态表现出一致性。所以y_与输入图片的大小是一致的。例如通过对一个人的关键点的描述可以判断出一个人的状态。我们需要目标图片y_的关键点来对x进行估计。
参考上述理由,u-net的框架会是本问题中最合适的解决方案,利用skip来将信息直接从输入传输到输出。然而在我们的例子中y和z同时对最后的G有影响。下面我们来讨论讨论关于z的话题。
上文说道,Z是从高斯分布q(z|x,y)中进行采样的,这个分布的参数通过模型f来获得。他的优化状态就是对下述的两个进行平衡:1)需要将x中的信息尽可能编入z,这样生成图片中一些原图的固有属性才能保持。同时需要最小化q(z|x,y_)以及p(z|y_)之间的散度距离。
G中Unet的设计已经保证了空间信息的保留,然而z中收集的是关于形状的信息,这个在上一个步骤中并没有涉及。因此一个优化完成的F必须对形状拥有不变性。所以将F的结果输出到G的bottle neck处对模型有益。模型如下:
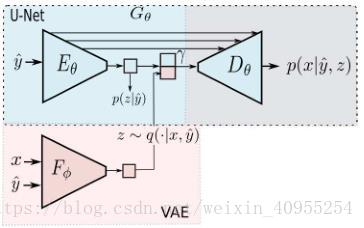
在生成模型G部分我们分成了一个编码器一个解码器,然后再bottleneck处我们将VAE的输出结果与G模型的左半部分联合在一起,然后D从这个联合特征图中生成图像。
总结:
刚开始看,这部分的理解有点坑坑洼洼的,不过多看点就好了,这篇文章其实就是利用VAE与U-NET集合,然后通过输入图片以及姿态图来进行任意图像的姿态转换。下面放出一些行人以及物品通过这个网络之后的生产图对比。大家感受感受

到这里,卡卡绊绊的就算写完了,虽然讲的不太顺,但是我觉着我还是学习了不少东西的,我是多多,欢迎大家交流指正
学术交流可以关注我的公众号,后台留言,粉丝不多,看到必回。卑微小钱在线祈求



















 827
827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











