







 本文探讨了一种增强深度学习网络的方法,通过引入小型检测器识别对抗性扰动。MagNet提出双重防御机制,包括基于重构误差的检测器和自动编码器转换器,以应对动态对手的攻击。研究还讨论了对抗样本分类中的误判原因及解决方案。
本文探讨了一种增强深度学习网络的方法,通过引入小型检测器识别对抗性扰动。MagNet提出双重防御机制,包括基于重构误差的检测器和自动编码器转换器,以应对动态对手的攻击。研究还讨论了对抗样本分类中的误判原因及解决方案。
On Detecting Adversarial Perturbations (6.28)
在这项工作中,我们提出用一个小的“检测器”子网络来增强深度神经网络,该子网络被训练用于二值分类任务,即从包含对抗性扰动的数据中区分真实数据。我们的经验表明,对抗性扰动可以被很好地检测到,即使它们对人类是准难以察觉的。此外,虽然探测器被训练成只检测特定的对手,但它们可以推广到相似和较弱的对手。此外,我们提出了一种对抗性攻击,它欺骗了分类器和检测器,以及一种新的检测器训练程序来抵消这种攻击。
我们通过(相对较小的)子网来增强分类网络,该子网在某一层脱离主网络,并产生一个输出
p
a
d
v
∈
[
0
,
1
]
p_{adv}\in [0,1]
padv∈[0,1],它被解释为输入是对抗样本的概率。我们称这个子网为“对抗检测网络”(或简称“检测器”),并训练它将网络输入分类为常规的示例或由特定对手生成的示例。为此,我们首先像往常一样在常规(非对抗性)数据集上训练分类网络,然后使用我们提出的方法之一为训练集的每个数据点生成对抗性示例。因此,我们获得了一个平衡的、二值分类数据集,其大小是原始数据集的两倍,由原始数据(标签0)和相应的对抗性例子(标签1)组成。因此,我们冻结了分类网络的权值,然后训练了检测器,最小化
p
a
d
v
p_{adv}
padv和其对应标签的交叉熵。对抗检测子网络的细节以及它是如何附加到分类网络的,都是特定于数据集和分类网络的。
动态的对抗与检测
在最坏的情况下,对手可能不仅可以访问分类网络及其梯度,而且还可以访问对手检测器及其梯度2。在这种情况下,对手可能会向网络生成输入,从而欺骗分类器(即,分类错误)和欺骗检测器(即,看起来无害)。
x
x
x 表示输入的图片
x
∈
R
3
×
w
i
d
t
h
×
h
e
i
g
h
t
x \in \mathbb{R}^{3\times width\times height}
x∈R3×width×height,
y
t
r
u
e
(
x
)
y_{true}(x)
ytrue(x) 是真实地标签,
J
c
l
s
(
x
,
y
(
x
)
)
J_{cls}(x,y(x))
Jcls(x,y(x)) 是分类器的损失函数。我们为原始样本生成对应的对抗样本的方法如下
arg min
(
1
−
σ
)
J
c
l
s
(
x
,
y
t
r
u
e
(
x
)
)
+
σ
J
d
e
t
(
x
,
1
)
\argmin (1- \sigma)J_{cls}(x, y_{true}(x)) + \sigma J_{det}(x,1)
argmin(1−σ)Jcls(x,ytrue(x))+σJdet(x,1)
J
d
e
t
(
x
,
1
)
J_{det}(x,1)
Jdet(x,1) 是检测器的损失 1 表示为对抗样本。
x
x
x 的迭代生成方法如下
x
0
a
d
v
=
x
;
x
n
+
1
a
d
v
=
C
l
i
p
x
ϵ
{
x
n
a
d
v
+
α
[
(
1
−
σ
)
s
g
n
(
∇
x
J
c
l
s
(
x
n
a
d
v
)
,
y
t
r
u
e
(
x
)
)
+
σ
s
g
n
(
∇
x
J
d
e
t
(
x
a
d
v
n
,
1
)
)
]
}
x^{adv}_0 = x;\\ x^{adv}_{n+1} = Clip^\epsilon_x \{x^{adv}_n + \alpha [(1-\sigma)\rm{sgn}\it{(\nabla_xJ_{cls}(x^{adv}_n), y_{true}(x))} + \sigma \rm{sgn}\it{(\nabla_xJ_{det}(x^{adv_n},\rm{1}))}]\}
x0adv=x;xn+1adv=Clipxϵ{xnadv+α[(1−σ)sgn(∇xJcls(xnadv),ytrue(x))+σsgn(∇xJdet(xadvn,1))]}
动态对抗训练 (6.29)
一种加固探测器对抗动态对手的方法。基于Goodfell等人(2015)提出的方法,我们不是预先计算敌对实例的数据集,而是为每个小批量实时计算敌对实例,并让对手以0.5的概率修改每个数据点。请注意,一个动态的对手在每次遇到一个数据点时都会以不同的方式修改一个数据点,因为它依赖于检测器的梯度,并且检测器会随时间而变化。我们将这种方法扩展到动态对手,使用动态对手的参数 σ \sigma σ 是从 [ 0 , 1 ] [0,1] [0,1]中随机选择一致的,在训练过程中生成对抗的数据点。通过以这种方式训练检测器,我们隐式地训练它来抵抗各种 σ \sigma σ 值的动态对手。原则上,这种方法对 σ > 0 \sigma >0 σ>0 有振荡和遗忘的风险,因为检测器和对手都相互适应(即没有固定的数据分布)。然而,在实践中,我们发现这种方法可以稳定地收敛,而不需要仔细地调整超参数。模型结构如下图所示
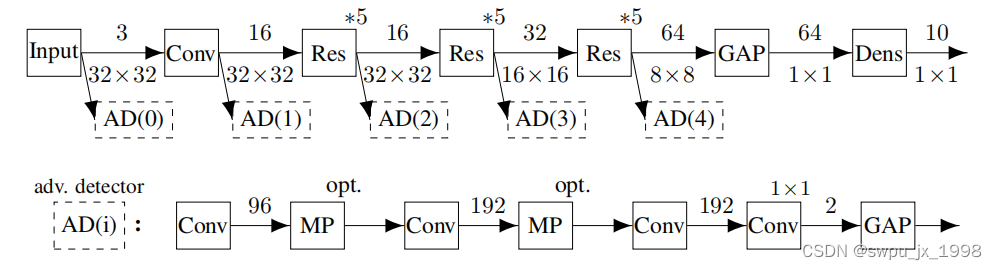
用于分类的 ResNet 箭头上面的数字表示特征的数量,箭头下面的数字表示图片的大小。Conv 为卷积层,Res∗5表示He等人(2016)引入的 5个残差块序列,GAP表示全局平均池化层,Dens为全连通层。分层卷积降低了空间分辨率,残差捷径上的特征映射数增加了1x1的卷积。所有的卷积层都有3x3个接受域,然后是批处理归一化和整正的线性单位。探测器网络的拓扑结构,它被附加到其中的一个AD(i)位置。MP表示最大池化,并且是可选的:对于AD(3),将跳过第二个池化层,而对于AD(4),则将跳过两个池化层。
MagNet: a Two-Pronged Defense against Adversarial Examples (7.01)
论文提出了 MagNet,一个保护神经网络分类器的框架。MagNet 既不修改受保护的分类器,也不需要了解生成对抗性示例的过程。MagNet包括一个或多个独立的检测器网络和一个重整器网络。检测器网络通过近似正常例子的流形来区分正常例子和对抗例子。由于它们假设没有生成对抗性例子的特定过程,所以它们可以很好地推广。重整器网络将敌对例子向正常例子的流形移动,这对小扰动的敌对例子进行正确分类是有效的。
Causes of mis-classification and solutions
(1) 对抗样本远离分类任务的流形边界。例如,该任务是手写的数字分类,而对抗样本是一个不包含数字的图像,但分类器不能选择拒绝这个例子,并被迫输出一个类标签。
(2) 对抗样本接近流形的边界。如果分类器在对抗样本附近对流形的推广较差,那么就会发生错误分类。
为了解决第一个问题,MagNet 使用 detector 检测一个样本与正常的区别,通过学习一个函数
f
:
X
→
{
0
,
1
}
f:\mathbb{X} \rightarrow \{0,1\}
f:X→{0,1}, 其中
X
\mathbb{X}
X 是所有样本的集合。
f
(
x
)
f(x)
f(x) 尝试检测一个测试样本
x
x
x 和流形空间的距离。如果超过一个阈值,就拒绝
x
x
x。
为了解决第二个问题,MagNet 使用 reformer 转化对抗样本。MagNet 训练一个自动编码器,以学习数据的近似流形。给定一个接近流形边界的对抗样本
x
x
x,自动编码器在数据流形上输出一个接近
x
x
x 的样本
y
y
y来替代
x
x
x。
Sign definition
S
\mathbb{S}
S: 样本空间的所有样本集合
C
t
\mathbb{C}_t
Ct: 样本分类标签集合
N
t
=
{
x
∣
x
∈
S
\mathbb{N}_t = \{x | x \in \mathbb{S}
Nt={x∣x∈S and
x
x
x occurs naturally with regard to the classification task
t
}
t \}
t} 正常样本集合
定义1. 分类任务
t
t
t 定义为一个函数
f
t
:
f
t
→
C
t
f_t: \mathbb{f}_t \rightarrow \mathbb{C}_t
ft:ft→Ct。
定义2. 分类任务
t
t
t 的 ground-truth 分类器代表了真实的样本判断,用函数
g
t
:
S
→
C
t
∪
{
⊥
}
g_t:\mathbb{S}\rightarrow\mathbb{C}_t \cup \{\bot\}
gt:S→Ct∪{⊥},其中
⊥
\bot
⊥ 代表不符合分类任务
t
t
t 的样本空间的数据
x
x
x 的判断。
定义3. 对抗样本
x
x
x 对于分类任务
t
t
t 和一个分类器
f
t
f_t
ft 满足两个条件:1)
f
t
(
x
)
≠
g
t
(
x
)
f_t(x) \not= g_t(x)
ft(x)=gt(x); 2)
x
∈
S
\
N
t
x \in \mathbb{S} \backslash \mathbb{N}_t
x∈S\Nt
定义4.
f
t
f_t
ft 的防御对抗样本定义为一个函数
d
f
t
:
S
→
C
t
∪
{
⊥
}
d_{f_t}:\mathbb{S}\rightarrow\mathbb{C}_t\cup\{\bot\}
dft:S→Ct∪{⊥}。
定义5.
d
f
t
d_{f_t}
dft 是否做出正确的判断依据两个使用条件:1)
x
x
x 是一个正常样本,
d
f
t
(
x
)
=
g
t
(
x
)
d_{f_t}(x) = g_t(x)
dft(x)=gt(x); 2)
x
x
x 是一个对抗样本,要么
d
f
t
d_{f_t}
dft 决定
x
x
x 是对抗样本,要么
d
f
t
d_{f_t}
dft 和
g
t
g_t
gt 达成一致的分类即
x
∈
S
\
N
t
x \in \mathbb{S} \backslash \mathbb{N}_t
x∈S\Nt 并且
d
f
t
(
x
)
=
⊥
d_{f_t}(x) = \bot
dft(x)=⊥ 或者
d
f
t
=
g
t
(
x
)
d_{f_t} = g_t(x)
dft=gt(x)。
Design (7.02)
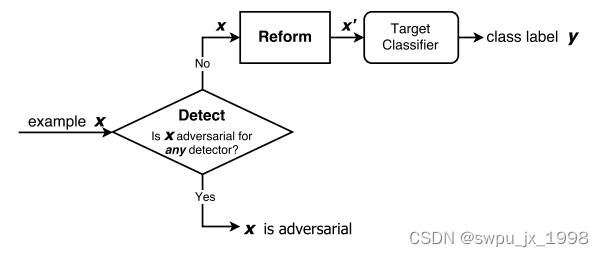
MagNet 的工作流程如上图所示。MagNet 包括一个或多个 detector。如果任意一个 detector 认为
x
x
x 是对抗样本,那么
x
x
x 就被认为是对抗样本。如果
x
x
x不被认为是对抗样本,MagNet 在将其输入目标分类器之前会进行 reform。
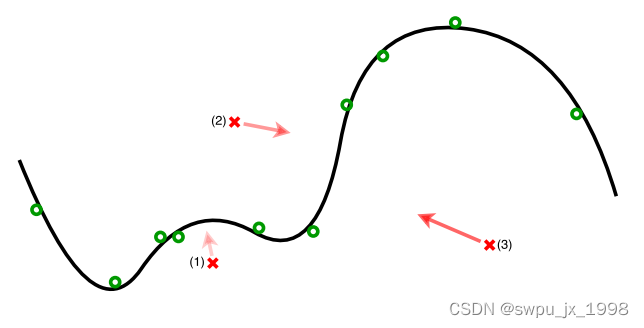
detector 和 reformer 如何在二维样本空间中工作的呢。我们用一条曲线来表示正常样本的流形,并分别用绿点和红叉来表示正常样本和对抗样本。我们用箭头来描述通过自动编码器进行的转换。detector 测量重构误差,并拒绝具有较大重构误差的样本(例如图中的红叉(3)),reformer 在流形附近找到一个接近输入样本的例子(例如图中的交叉(1))。
Detector
基于重构误差的检测器。MagNet的检测器只对正常样本建模,不需要使用到对抗样本,因此比较容易推广,并估计了测试样本与正常样本流形边界之间的距离。MagNet 使用一个自动编码器作为检测器,并使用重构误差来估计输入和流形之间的距离。一个自动编码器
a
e
ae
ae 包括两部分:一个编码器
e
:
S
→
H
e:\mathbb{S}\rightarrow\mathbb{H}
e:S→H 和一个解码器
d
:
H
→
S
d:\mathbb{H}\rightarrow\mathbb{S}
d:H→S , 其中
S
\mathbb{S}
S 是输入的样本空间,
H
\mathbb{H}
H 是隐藏表示空间。MagNet 训练自动编码器来最小化在训练集上的损失函数,其中损失函数通常是均方误差:
L
(
X
t
r
a
i
n
)
=
1
∣
X
t
r
a
i
n
∣
∑
x
∈
X
t
r
a
i
n
∥
x
−
a
e
(
x
)
∥
2
L(\mathbb{X}_{train}) = \frac{1}{|\mathbb{X}_{train}|}\sum_{x\in\mathbb{X}_{train}}\|x-ae(x)\|_2
L(Xtrain)=∣Xtrain∣1x∈Xtrain∑∥x−ae(x)∥2
在一个测试样本
x
x
x 上的重构误差为
E
(
x
)
=
∥
x
−
a
e
(
x
)
∥
p
E(x) = \|x-ae(x)\|_p
E(x)=∥x−ae(x)∥p
基于概率散度的探测器。基于重构误差的检测器可以有效地检测重构误差较大的对抗样本。然而,对于重构误差较小的对抗样本,其效果较差。为了克服这个问题,MagNet 利用了目标分类器。
大多数神经网络分类器在最后一层实现了 softmax 函数
s
o
f
t
m
a
x
(
l
)
i
=
e
x
p
(
l
i
)
∑
j
=
1
n
e
x
p
(
l
j
)
\rm{softmax}(\mathbf{\it{l}})_i = \frac{exp(\it{l}_i)}{\sum^{\it{n}}_{\it{j}=1}exp(\it{l}_j)}
softmax(l)i=∑j=1nexp(lj)exp(li)
f
(
x
)
f(x)
f(x) 代表模型对
x
x
x 的预测,
a
e
(
x
)
ae(x)
ae(x) 是自动编码器的输出,如果
x
x
x 是正常样本,因为
a
e
(
x
)
ae(x)
ae(x) 与
x
x
x 非常相似,那么
f
(
x
)
f(x)
f(x) 与
f
(
a
e
(
x
)
)
f(ae(x))
f(ae(x)) 也应该是非常相似的。相反,如果
x
′
x^{\prime}
x′ 是一个对抗样本,即使
a
e
(
x
′
)
ae(x^\prime)
ae(x′) 与
x
′
x^\prime
x′ 相差比较小,
f
(
x
′
)
f(x^\prime)
f(x′) 和
f
(
a
e
(
x
′
)
)
f(ae(x^\prime))
f(ae(x′)) 也会差别较大。这表明
f
(
x
′
)
f(x^\prime)
f(x′) 和
f
(
a
e
(
x
′
)
)
f(ae(x^\prime))
f(ae(x′)) 之间的散度反映出了
x
′
x^\prime
x′ 与正常样本之间的差异。MagNet 使用 Jensen-Shannon 散度来度量
J
S
D
(
P
∥
Q
)
=
1
2
D
K
L
(
P
∥
M
)
+
1
2
D
K
L
(
Q
∥
M
)
D
K
L
(
P
∥
Q
)
=
∑
i
P
(
i
)
log
P
(
i
)
Q
(
i
)
M
=
1
2
(
P
+
Q
)
JSD(P\|Q) = \frac{1}{2}D_{KL}(P\|M) + \frac{1}{2}D_{KL}(Q\|M)\\ D_{KL}(P\|Q) = \sum_i P(i)\log \frac{P(i)}{Q(i)}\\ M = \frac{1}{2} (P + Q)
JSD(P∥Q)=21DKL(P∥M)+21DKL(Q∥M)DKL(P∥Q)=i∑P(i)logQ(i)P(i)M=21(P+Q)
Reformer
转换器的作用是将对抗输入转换为正常的输入,用函数表示 r : S → N t r:\mathbb{S}\rightarrow \mathbb{N}_t r:S→Nt。理想的转换器满足下面两个条件:
- 不应该改变正常样本的分类结果
- 应该有效地改变对抗样本,使重建的样本接近于正常样本。
基于噪声的转换器。一个初始转化器是一个向输入数据添加随机噪声的函数。如果使用高斯噪声,我们得到以下在转换器
r
(
x
)
=
c
l
i
p
(
x
+
ϵ
⋅
y
)
r(x) = clip(x + \epsilon\cdot y)
r(x)=clip(x+ϵ⋅y)
其中
y
∽
N
(
y
;
0
,
I
)
y\backsim\mathcal{N}(y;0,I)
y∽N(y;0,I) 是均值为零和单位协方差矩阵的正态分布,
ϵ
\epsilon
ϵ 对噪声进行缩放,
c
l
i
p
clip
clip 是一个函数,它将其输入向量的每个元素裁剪到有效范围内。这种基于噪声的重整器的一个缺点是它没有正常样本的分布。因此,它随机而盲目地改变正常的和对抗的样本,但我们理想的转换器应该很少改变正常的样本,而应该把对抗样本转向正常的样本。
基于自动编码的转换器。MagNet建议使用自动编码器作为转换器。MagNet训练自动编码器使训练集上的重构误差最小化,并确保它在验证集上具有很好的推广性。然后,当给定一个正常样本,它来自与训练样本相同的数据生成过程,自动编码器被期望输出一个非常相似的样本。但是当给出一个对抗样本时,自动编码器被期望输出一个接近对抗样本的样本,并且更接近正常样本的流形。这样,MagNet在保持正常例分类精度不变的同时,提高了对抗样本的分类精度。

















 2629
2629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









