






DeepFool: a simple and accurate method to fool deep neural networks
1.引言
作者首先定义了对抗攻击的范式和模型的鲁棒性。
通常,对与一个给定的模型,能够改变分类器
k
^
(
x
)
\hat{k}(x)
k^(x) 的分类结果的最小对抗扰动
r
r
r 定义如下
Δ
(
x
;
k
^
)
:
=
min
r
∥
r
∥
2
subject to
k
^
(
k
+
r
)
≠
k
^
(
x
)
\Delta(x;\hat{k}):=\min_r\|r\|_2\;\;\text{subject to}\; \hat{k}(k+r) \not=\hat{k}(x)
Δ(x;k^):=rmin∥r∥2subject tok^(k+r)=k^(x)
其中
x
x
x 是图片,
k
^
(
x
)
\hat{k}(x)
k^(x) 是预测的标签,
Δ
(
x
;
k
^
)
\Delta(x;\hat{k})
Δ(x;k^) 是分类器
k
^
\hat{k}
k^ 在
x
x
x 处的鲁棒性。分类器
k
^
\hat{k}
k^ 的鲁棒性定义为
ρ
a
d
v
(
k
^
)
=
E
x
Δ
(
x
;
k
^
)
∥
x
∥
2
\rho_{adv}(\hat{k})=\mathbb{E}_x\frac{\Delta(x;\hat{k})}{\|x\|_2}
ρadv(k^)=Ex∥x∥2Δ(x;k^)。
作者的贡献可以归结为三点:
-
提出了一种新的计算对抗样本的方法 DeepFool,该方法是基于梯度迭代方法中生成扰动最小的,并且能有较高的攻击准确率。
-
用对抗样本增加训练数据,显著提高模型对对抗扰动的鲁棒性,该部分贡献对抗训练的前期研究。
-
分析了 FGSM 算法来验证分类器的鲁棒性的不合理性,并提出该算法会过分的评估分类器的鲁棒性,并定义了什么是样本鲁棒性,什么是模型的鲁棒性。
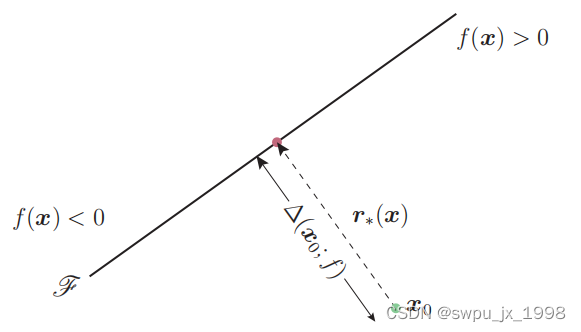
2.DeepFool 实现 - 二分类
首先定义一个二分类器
f
(
x
)
=
w
T
x
+
b
f(x)=w^Tx + b
f(x)=wTx+b, 以及分类超平面
F
=
{
x
:
w
T
x
+
b
=
0
}
\mathcal{F} = \{x:w^Tx+b =0\}
F={x:wTx+b=0}。对于一个样本
x
0
x_0
x0,
f
f
f 在
x
0
x_0
x0 处的鲁棒性
Δ
(
x
0
;
f
)
\Delta(x_0;f)
Δ(x0;f) 则是
x
0
x_0
x0 到超平面的正交投影距离,定义如下:
r
∗
(
x
0
)
:
=
arg min
∥
r
∥
2
subject to
s
i
g
n
(
f
(
x
0
+
r
)
)
≠
s
i
g
n
(
f
(
x
0
)
)
=
−
f
(
x
0
)
∥
w
∥
2
2
w
r_*(x_0) :=\argmin \|r\|_2 \;\; \text{subject to} \; sign(f(x_0+r)) \not= sign(f(x_0))\\ =-\frac{f(x_0)}{\|w\|^2_2}w
r∗(x0):=argmin∥r∥2subject tosign(f(x0+r))=sign(f(x0))=−∥w∥22f(x0)w
其中
w
w
w 是超平面的法向量
如果
f
f
f 是一个可微的函数,那么就可以通过迭代的方式求出
r
∗
r_*
r∗,可以将以上的公式优化为下面的形式
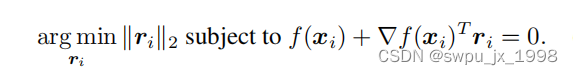
推导过程:
已知
r
i
=
−
f
(
x
i
)
∥
w
∥
2
2
w
r_i = -\frac{f(x_i)}{\|w\|^2_2}w
ri=−∥w∥22f(xi)w,从几何意义上来说,梯度
∇
f
(
x
i
)
=
w
\nabla f(x_i) = w
∇f(xi)=w,所以有
r
i
=
−
f
(
x
i
)
∥
∇
f
(
x
i
)
∥
2
2
∇
f
(
x
i
)
r_i = \frac{-f(x_i)}{\|\nabla f(x_i)\|_2^2}\nabla f(x_i)
ri=∥∇f(xi)∥22−f(xi)∇f(xi)
又因为
∥
∇
f
(
x
i
)
∥
2
2
=
∇
f
(
x
i
)
⋅
∇
f
(
x
i
)
T
\|\nabla f(x_i)\|_2^2 = \nabla f(x_i) \cdot \nabla f(x_i)^T
∥∇f(xi)∥22=∇f(xi)⋅∇f(xi)T , 移项就有:
∇
f
(
x
i
)
T
r
i
+
f
(
x
i
)
=
0
\nabla f(x_i)^Tr_i + f(x_i) = 0
∇f(xi)Tri+f(xi)=0
通过上面的公式得到二分类求对抗样本的算法如下

3.DeepFool 实现 - 多分类
首先是多分类器定义如下
k
^
(
x
)
=
arg max
k
f
k
(
x
)
\hat{k}(x) = \argmax_k f_k(x)
k^(x)=kargmaxfk(x)
其中
f
k
(
x
)
f_k(x)
fk(x) 是分类器对第
k
k
k 类的预测结果,定义
f
(
x
)
=
W
T
x
+
b
f(x) = \mathbf{W}^T x +b
f(x)=WTx+b, 那么求多分类的扰动
r
r
r 定义如下
arg min
r
∥
r
∥
2
s
.
t
.
∃
k
:
w
k
T
(
x
0
+
r
)
+
b
k
≥
w
k
^
(
x
0
)
T
(
x
0
+
r
)
+
b
k
^
(
x
0
)
\argmin_r \|r\|_2 \\ s.t. \exists k:w_k^T(x_0+r) +b_k \geq w^T_{\hat{k}(x_0)}(x_0+r) + b_{\hat{k}(x_0)}
rargmin∥r∥2s.t.∃k:wkT(x0+r)+bk≥wk^(x0)T(x0+r)+bk^(x0)
为了更好的理解以上优化形式的含义,自己做了一个图示便于理解。如下图所示,左半部分是干净样本的概率向量的输出,预测的类别为
k
^
\hat{k}
k^ , 加入对抗扰动后,预测类别变成了
k
k
k
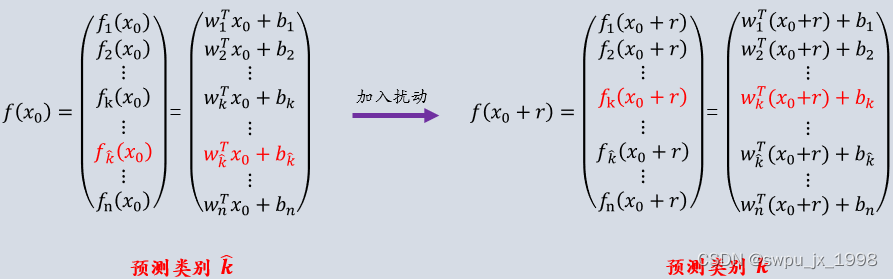
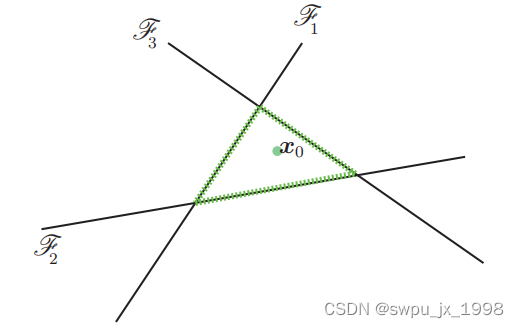
从几何上来解释,上述问题对应于
x
0
x_0
x0 与凸多面体
P
P
P 之间距离的计算,
P
P
P 可以定义如下
P
=
⋂
k
=
1
c
{
x
:
f
k
^
(
x
0
)
(
x
)
≥
f
k
(
x
)
}
P = \bigcap_{k=1}^c\{x:f_{\hat{k}(x_0)}(x) \geq f_k(x)\}
P=k=1⋂c{x:fk^(x0)(x)≥fk(x)}
x
0
x_0
x0 位于
P
P
P 内一点。
如图所示,绿色直线所包含的区域就是
P
P
P
定义
l
^
(
x
0
)
\hat{l}(x_0)
l^(x0) 是距离
P
P
P 最近的超平面,根据距离公式,
l
^
(
x
0
)
\hat{l}(x_0)
l^(x0) 可定义如下
l
^
(
x
0
)
=
arg min
k
≠
k
^
(
x
0
)
∥
f
k
(
x
0
)
−
f
k
^
(
x
0
)
(
x
0
)
∥
∥
w
k
−
w
k
^
(
x
0
)
∥
2
\hat{l}(x_0) = \argmin_{k\not=\hat{k}(x_0)} \frac{\|f_k(x_0)-f_{\hat{k}(x_0)}(x_0)\|}{\|w_k - w_{\hat{k}(x_0)}\|_2}
l^(x0)=k=k^(x0)argmin∥wk−wk^(x0)∥2∥fk(x0)−fk^(x0)(x0)∥
那么最小的扰动
r
∗
(
x
0
)
r_*(x_0)
r∗(x0) 就是
x
0
x_0
x0 投影到超平面
l
^
(
x
0
)
\hat{l}(x_0)
l^(x0) 的距离,即
r
∗
(
x
0
)
=
∥
f
l
^
(
x
0
)
(
x
0
)
−
f
k
^
(
x
0
)
(
x
0
)
∥
∥
w
l
^
(
x
0
)
−
w
k
^
(
x
0
)
∥
2
(
w
l
^
(
x
0
)
−
w
k
^
(
x
0
)
)
r_*(x_0) = \frac{\|f_{\hat{l}(x_0)}(x_0)-f_{\hat{k}(x_0)}(x_0)\|}{\|w_{\hat{l}(x_0)} - w_{\hat{k}(x_0)}\|_2}(w_{\hat{l}(x_0)} - w_{\hat{k}(x_0)})
r∗(x0)=∥wl^(x0)−wk^(x0)∥2∥fl^(x0)(x0)−fk^(x0)(x0)∥(wl^(x0)−wk^(x0))
对与现实中常用到的分类器往往是非线性的,在这样的非线性的凸区域
P
P
P 内,作者选择一个线性的凸区域
P
~
\tilde{P}
P~ 作为替代,每一次迭代过程中的
P
~
i
\tilde{P}_i
P~i 定义如下
P
~
i
=
⋂
k
=
1
c
{
x
:
f
k
(
x
i
)
−
f
k
^
(
x
0
)
(
x
i
)
+
∇
f
k
(
x
i
)
T
x
−
∇
f
k
^
(
x
0
)
(
x
i
)
T
x
≤
0
}
\tilde{P}_i = \bigcap_{k=1}^c \{x:f_k(x_i)-f_{\hat{k}(x_0)}(x_i)+\nabla f_k(x_i)^Tx - \nabla f_{\hat{k}(x_0)}(x_i)^Tx \leq 0\}
P~i=k=1⋂c{x:fk(xi)−fk^(x0)(xi)+∇fk(xi)Tx−∇fk^(x0)(xi)Tx≤0}
最终,多分类的DeepFool生成对抗样本的算法流程如下:

以上算法是在二范数下进行计算的,如果要扩展到
p
p
p 范数下,只需要修改 10 行和11行公式
l
^
=
arg min
∣
f
k
′
∣
∥
w
k
′
∥
q
r
i
=
∣
f
l
^
′
∣
∥
w
l
^
′
∥
q
q
∣
w
l
^
′
∣
q
−
1
⊙
s
i
g
n
(
w
l
^
′
)
\hat{l} = \argmin \frac{|f^{\prime}_k|}{\|w_k^{\prime}\|_q}\\ r_i = \frac{|f_{\hat{l}}^{\prime}|}{\|w_{\hat{l}}^{\prime}\|_q^q}|w_{\hat{l}}^{\prime}|^{q-1} \odot sign(w_{\hat{l}}^{\prime})
l^=argmin∥wk′∥q∣fk′∣ri=∥wl^′∥qq∣fl^′∣∣wl^′∣q−1⊙sign(wl^′)
其中
q
=
p
p
−
1
q = \frac{p}{p-1}
q=p−1p

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









