






C&W(Carlini & Wagner)
整体思想
首先明确 CW 攻击是 Target Attack (当然也可以是无目标攻击),对攻击样例添加难以察觉的扰动,使模型以高置信度给出一个错误的标签。 该算法将对抗样本当成一个变量(后文有解释),那么现在如果要使得攻击成功就要满足两个条件:(1)对抗样本和对应的干净样本应该差距越小越好;(2)对抗样本应该使得模型分类错,且错的那一类的概率越高越好。
这类问题可以表述为一个约束最小化问题:
m
i
n
i
m
i
z
e
D
(
x
,
x
+
δ
)
;
s
u
c
h
t
h
a
t
C
(
x
+
δ
)
=
t
,
x
+
δ
∈
[
0
,
1
]
n
\rm{minimize} \;\; \it{D(x,x+\delta)} ; \rm{such} \; \rm{that} \it{C}(x+\delta)=t,x+\delta \in [0,1]^n
minimizeD(x,x+δ);suchthatC(x+δ)=t,x+δ∈[0,1]n
目标函数
基于优化:其实就是优化扰动后的图像,使其和原始图像的距离最短(即加入的扰动最小)
由于目标函数一个高度非线性的函数,现有算法很难直接求解上述公式,往往通过将其表述为一个适当的优化公式来解决,而这个优化公式可以通过现有的优化算法来解决。论文定义了新的目标函数
f
f
f , 使得
f
(
x
+
δ
)
≤
0
f(x+\delta)\leq0
f(x+δ)≤0 当且仅当
C
(
x
+
δ
)
=
t
C(x+\delta)=t
C(x+δ)=t 成立,论文提出了七个目标函数
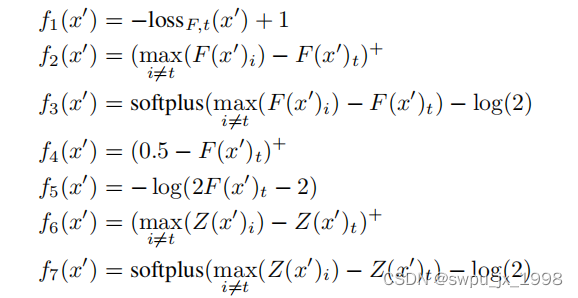
其中:
(1)对目标标签的损失函数进行优化,这个目标函数和 L-BFGS Attack 相类似。f1函数和L-BFGS中的L(.)项都是针对目标模型的真实损失函数,只不过f1中做了一点改变。
(2)对目标标签的置信度进行优化,希望其成为最后预测值。
(3)也是对目标标签的置信度进行优化,形式不同,max函数更换成softplus函数。
(4)也是对目标标签的置信度进行优化,希望其成为最大可能类。
(5)同4。
(6)对目标标签的 logit 值进行优化。同 2.
(7)也对目标标签的 logit 值进行优化,同 3.
(
e
)
+
(e)^+
(e)+ 是
m
a
x
(
e
,
0
)
max(e,0)
max(e,0) 的缩写,
s
u
f
t
p
l
u
s
(
x
)
=
l
o
g
(
1
+
e
x
p
(
x
)
)
,
l
o
s
s
F
,
s
(
x
)
suftplus(x) = log(1+exp(x)), lossF,s(x)
suftplus(x)=log(1+exp(x)),lossF,s(x)是交叉熵损失。
现在可以把原问题表述为:
min
D
(
x
,
x
+
d
e
l
t
a
)
+
c
⋅
f
(
x
+
δ
)
s
t
.
x
+
δ
∈
[
0
,
1
]
n
\min D(x,x+delta) + c\cdot f(x+\delta)\\ st. \; x+\delta \in [0,1]^n
minD(x,x+delta)+c⋅f(x+δ)st.x+δ∈[0,1]n
其中
c
>
0
c > 0
c>0 是一个惩罚因子,用于权衡目标和约束的重要性,有点像正则化,论文通过二分查找法来选择合适的 c。
盒约束
为了确保生成有效的图片,对于像素点的扰动 δ \delta δ 存在着约束 0 ≤ x + δ ≤ 1 0\leq x+\delta \leq 1 0≤x+δ≤1 ,在优化问题中,这个被称为 “盒约束”。该论文研究了三种不同方法来解决这个问题:
- Projected gradient descent 梯度投影
思想:在每次迭代中,执行一个单步标准梯度下降后,将所有坐标约束到[0,1] 的范围内
缺点:它将剪辑后的图片作为下一次迭代的输入,这样每次传入下一步的都不是真实像素值。
Clipped gradient descent梯度截断
思想:将盒约束整合到目标函数中,即目标函数从 f ( x + δ ) f(x+\delta) f(x+δ)转化为 f ( m i n ( m a x ( x + δ , 0 ) , 1 ) ) f(min(max(x+\delta,0),1)) f(min(max(x+δ,0),1))。
缺点:只对目标函数进行了约束,可能已经出现了x超过阈值的情况,这种情况下,梯度始终为0,以至于即使x应该去减少,从梯度方面也无法检测到。(我是这样理解的,如果某次优化后,x意外的大于了1,那么在以后的运算中,对应的点由于max-min约束,梯度始终为0,然后就想减小也减小不了了)
Change of variables引入新变量
思想:引入一个新的变量 ω,将上述优化 δ 的问题转化为优化 ω,通过定义:
δ i = 1 / 2 ( t a n h ( ω ) + 1 ) − x i \delta_i=1/2(tanh(\omega)+1)-x_i δi=1/2(tanh(ω)+1)−xi
因为 − 1 ≤ t a n h ( ω ) ≤ 1 -1\leq tanh(\omega)\leq 1 −1≤tanh(ω)≤1 ,所以 0 ≤ x i + δ i ≤ 1 0\leq x_i + \delta_i \leq 1 0≤xi+δi≤1 是成立的,这样的转化允许我们使用其他不支持盒约束的算法进行优化,论文尝试了三种求解方法:标准梯度下降法、动量梯度下降法以及 Adam 算法,并且发现这三种算法都得到相同质量的解,然而 Adam 算法的收敛速度最快。
这里将 ω \omega ω 变量用来代替原来的样本,主要就是将样本映射到 tanh 空间,可以在 ( − ∞ , + ∞ ) (-\infin,+\infin) (−∞,+∞) 中进行变换,有利于优化。原文中,作者用 ω = a r c t a n ( 2 x − 1 ) \omega = arctan(2x-1) ω=arctan(2x−1)
def train_adv_cw(
model: nn.Module, adv_examples: torch.Tensor, adv_target: int = 3, iteration: int = 5000, lr: float = 0.01, c:float = 1
):
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def create_single_adv(model: nn.Module, adv_examples: torch.Tensor, adv_target: int = 3, iteration: int = 5000, lr: float = 0.01, c:float = 1):
box_max = 1
box_min = 0
box_mul = (box_max - box_min)/2
box_plus = (box_min + box_max)/2
modifier = torch.zeros_like(adv_examples, requires_grad=True)
l2dist_list = []
loss2_list = []
loss_list = []
model.eval()
for i in range(iteration):
new_example = torch.tanh(adv_examples + modifier)*box_mul + box_plus
l2dist = torch.sum(torch.square(new_example - adv_examples))
output = model(new_example)
#设定攻击目标
onehot = torch.zeros_like(output)
onehot[:, adv_target] = 1
others = torch.max((1-onehot)*output, dim=1).values
real = torch.sum(output*onehot, dim=1)
loss2 = torch.sum(torch.maximum(torch.zeros_like(others) - 0.01, others - real))
loss = l2dist + c*loss2
l2dist_list.append(l2dist)
loss2_list.append(loss2)
loss_list.append(loss)
if modifier.grad is not None:
modifier.grad.zero_()
loss.backward()
modifier = (modifier - modifier.grad*lr).detach()
modifier.requires_grad = True
def plot_loss(loss, loss_name):
plt.figure()
plt.plot([i for i in range(len(loss))], [i.detach().numpy() for i in loss])
# plt.yticks(np.arange(1,50,0.5))
plt.xlabel('iteration times')
plt.ylabel(loss_name)
plt.show()
plot_loss(l2dist_list, 'l2 distance loss')
plot_loss(loss2_list, 'category loss')
plot_loss(loss_list, 'all loss')
new_img = torch.tanh(adv_examples + modifier) * box_mul + box_plus
return new_img
adv_list = []
for i in adv_examples:
adv_list.append(create_single_adv(model,i,adv_target,iteration,lr))
return torch.Tensor(adv_list)
l2dist
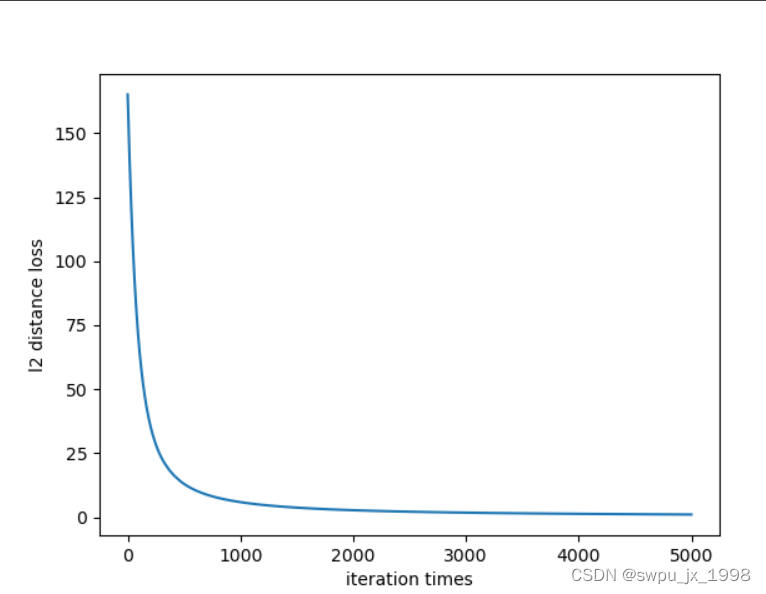
loss2
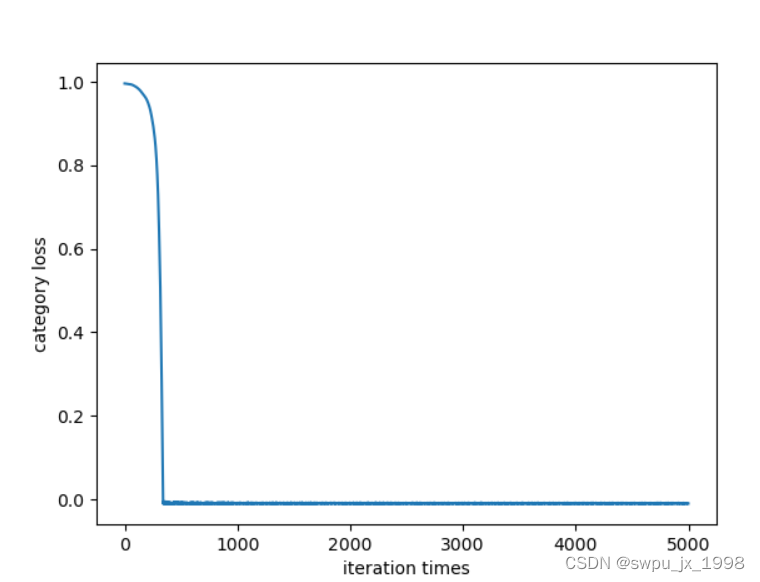
loss
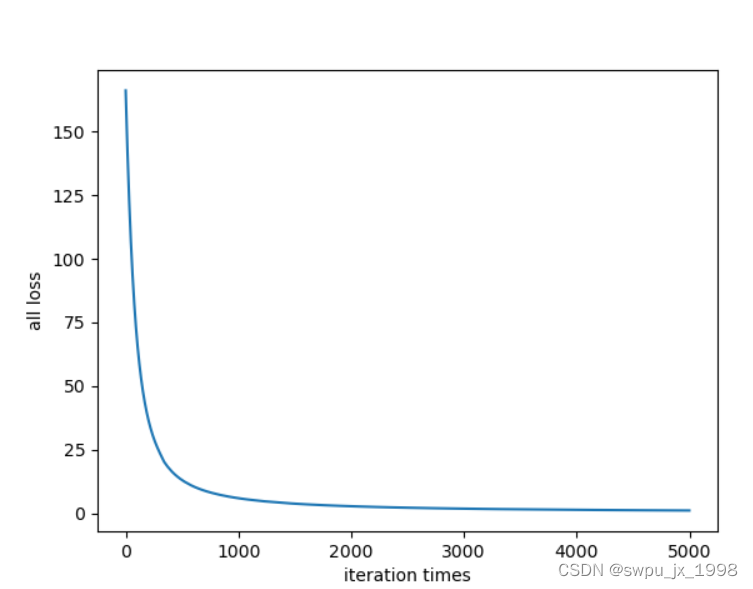
原图:预测为 5
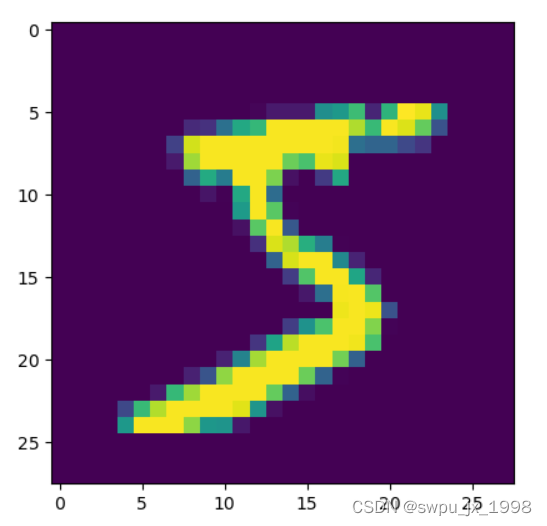
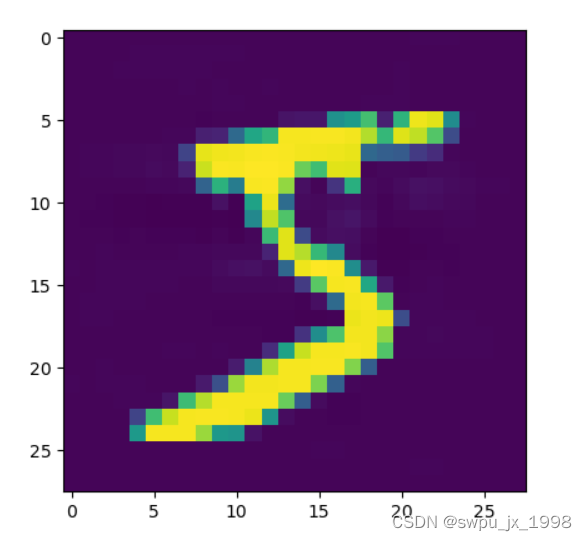
对抗样本:预测为 3


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









