







 本文总结了机器学习中的特征工程,包括数据预处理、特征选择、特征抽取等方面。介绍了归一化、类别型特征处理、特征组合、文本表示模型如词袋模型、主题模型和词嵌入,以及图像数据不足时的处理方法如数据扩充和迁移学习。
本文总结了机器学习中的特征工程,包括数据预处理、特征选择、特征抽取等方面。介绍了归一化、类别型特征处理、特征组合、文本表示模型如词袋模型、主题模型和词嵌入,以及图像数据不足时的处理方法如数据扩充和迁移学习。
持续更新中
特征工程
- 数据预处理-无量纲化(归一化),缺失值填充,数据变化
- 特征选择-Filter, Wrapper, Embedded
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。i.e.方差选择法、相关系数法、互信息(信息增益)法
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。i.e. 前向(后向、双向)特征选择法
- Embedded:集成法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。i.e.基于L1惩罚项的特征选择法、基于树模型(GBDT)的特征选择法
- 特征抽取(降维)-PCA, LDA
1、什么是特征工程?为什么需要特征工程?
1)特征工程:对原始数据进行一系列工程处理,将其提炼为特征,作为输入供模型和算法使用。在实际操作中,特征工程旨在去除原始数据中的冗余和噪声,设计更高效特征。i.e. FM中 feature crossing的思想就是代替特征工程设计更好的特征。
2)”Garbage in, garbage out”, 数据和特征往往决定了结果的上界,而模型、算法的选择及优化只是在逐步接近这个上限。
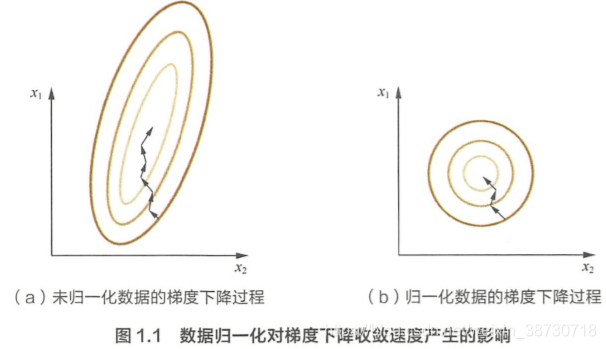
2、为什么需要特征归一化?常用归一化方法?
1)a. 消除不同数据特征的量纲影响,使得不同指标之间具有可比性。
b. 使梯度下降过程更稳定。从梯度下降实例看出:
若x1∈[0, 10], x2∈[0, 3],当学习速率一样时,x1更新速度大于x2,需要较多迭代次数到底最优解。
2)线性归一化(min-max scaling)-等比缩放 零均值归一化(Z-score normalization)-N(0,1)![]()
|
|
|
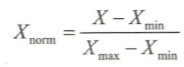
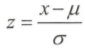
3、 类别型特征( Categorical Feature )如何处理?
序号编码(Ordinal Encoding):按照大小关系赋予一个数值ID,如,高:3, 中:2低:1
独热编码(One-hot Encoding):对于无大小关系的类别特征,变为相应维度的稀疏向量。
二进制编码(Binary Encoding):先将类别映射为ID,将ID的二进制编码作为结果。
4、 特征组合-怎么样有效寻找特征组合?
基于决策树的特征组合寻找方法-首先构造决策树,将树中每一条从根节点到叶子节点的路径看成一种特征组合的方式。如下图决策树所示,构成4个组合特征:
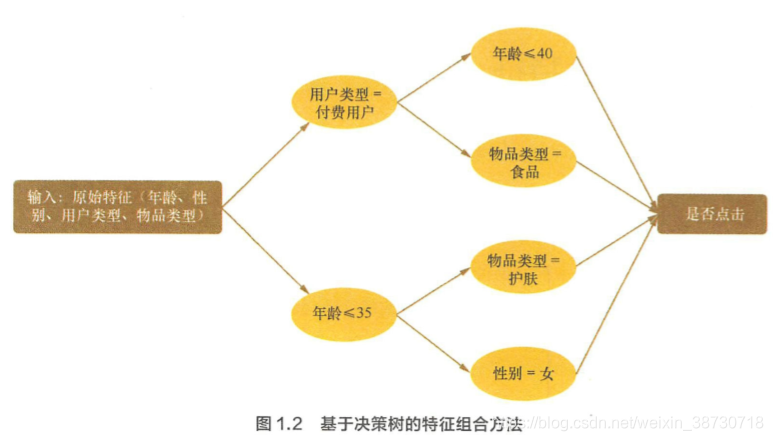
( l ) “年龄<=35 '’且“性别=女” 。
( 2 ) “军龄<=35”且 “物品类别=护肤” 。
( 3 ) “用户类型=付费”且“物品类型=食晶” 。
( 4) “用户类型=付费”且“年龄 <=40。”
5、文本表示模型有哪些?各有那些优缺点?
1)词袋模型(Bag of Words)和N-gram模型
将文章视为一袋子词,忽略词的出现顺序,将文章表示为一个长向量,每个维度表示一个单词,权重可以TF-IDF计算。
N-gram:将连续出现的n个词(n<=N)组成的词组(N-gram)也作为一个单独特征加入到向量表示中。
注:实际应用中,一般会对单词进行词干抽取(Word Stemming)处理。
缺陷:无法识别出2个不同的词/词组具有相同的主题,i.e., 篮球、排球主题都是运动。
2)主题模型(Topic Model)
用于从文本库中发现有代表性的主题(得到每个主题上面的词的分布特性),并且能够计算每篇文章的主题分布。
pLSA: 主题分布和词分布服从一个确定的概率分布。

求解:由于参数中包含的 zk 是隐含变量(即 无法直接观测到的变量), 因此无法用最大似然估计直接求解3 可以利用最大期望法来解决。
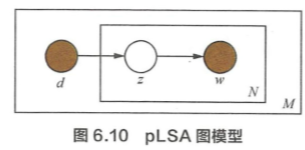
LDA: pLSA 的贝叶斯版本,其文本生成过程与 pLSA 基本相同,不同的是为主题分布和词分布分别回了两个狄利克雷(Dirichlet)先验。
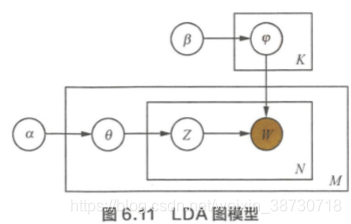
求解:吉布斯采样(Gibbs Sampling)的方式实现。 首先随机给定每个单词的主题, 然后在真他变量固定的情况下,根据转移概率抽样生成每个单词的新主题。
pLSA与LDA区别
pLSA-是频率派思想,将每篇文章的主题分布和主题的词分布看成确定的未知常数,可以求解出来。
LDA-贝叶斯派思想,认为待估参数(主题分布和词分布)不是固定常数,而是服从一定分布的随机变量。这个分布符合一定的先验概率分布(即狄利克雷分布),并且在观察到样本信息之后,可以对先验分布进行修正,从而得到后验分布。
3)词嵌入模型(Word Embedding)
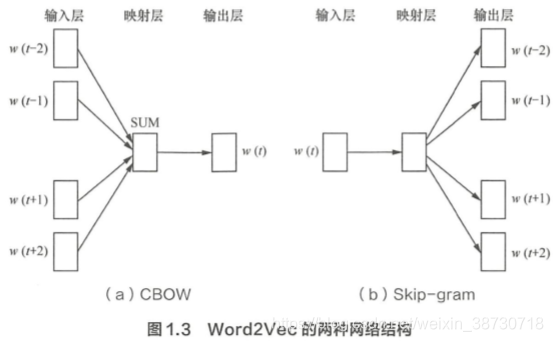
核心思想:将每个单词映射成低维空间上的一个Dense Vector, i.e. Word2Vec
Word2Vec的2中结构:CBOW (Continues Bag of Words)和 Skip-gram。
CBOW:根据上下文词语预测当前词。
Skip-gram:根据当前词预测上下文。
LDA与Word2Vec区别?
LDA: 利用文挡中单词的共现关系来对单词按主题聚类,即对“文挡-单词” 矩阵进行分解 得到“文档-主题”和“主题-单词”两个概率分布。
Word2Vec: 对“上下文-单词”矩阵进行学习,得到的词向量表示更多地融入了上下文共现的特征
主题模型和词嵌入两类万法的主要差异?
主题模型是一种基于概率图模型的生成式模型,其似然函数可以写成若干条件概率连乘的形式,其中包括需要推测的隐含变量(即主题);而词嵌入模型一般表达为神经网络的形式,似然函数定义在网络的输出之上,通过学习网络的权重以得到单词的向量表示。
6、图像数据不足时的处理方法
3类处理方法:
1) 基于模型的方法-降低过拟合风险
简化模型、添加正则项、集成学习、Dropout
2)基于数据的方法-数据扩充( Data Augmentation ),根据一些先验知识,在保
持特定信息的前提下,对原始数据进行适当变换。
对图像:
- 一定程度内进行旋转、平移、缩放、裁剪、填充、左右翻转等。
- 对像素添加躁声扰动,比如椒盐噪声、高斯白噪声等。
- 颜色变换。
- 改变图像的亮度、清晰度、对比度、锐度等。
3)迁移学习。

















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









