




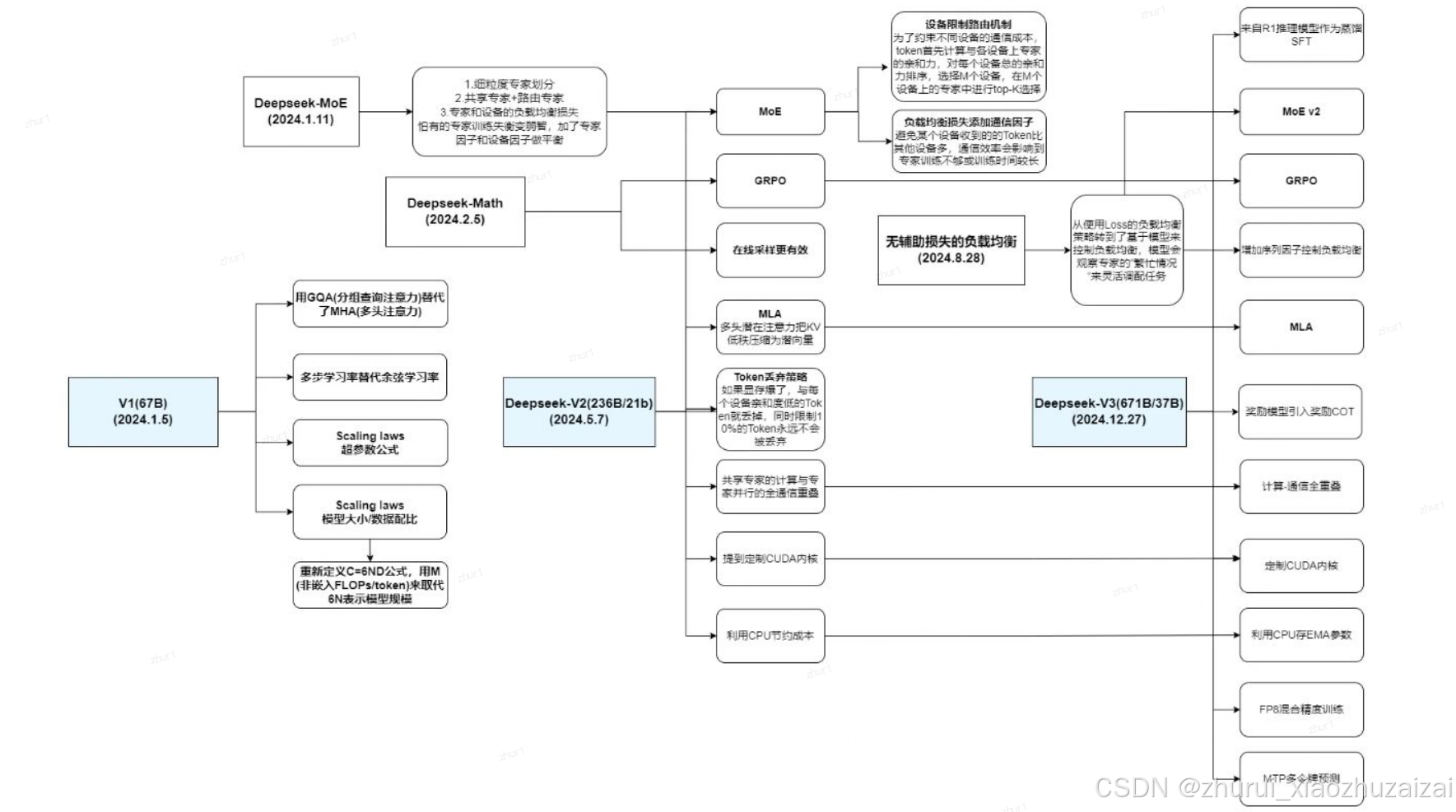
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (2024.01.06)
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models(2024.01.12)
DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence(2024.01.25)
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models(2024.02.06)
DeepSeek-VL: Towards Real-World Vision-Language Understanding (2024.03.09)
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model(2024.05.07)
DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic (2024.05.23)
DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence(2024.06.17)
Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models (2024.07.02)
DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search(2024.08.15)
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation(2024.10.18)
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation (2024.11.13)
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding(2024.12.14)
DeepSeek-V3 Technical Report (2024.12.27)
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning(2025.01.22)
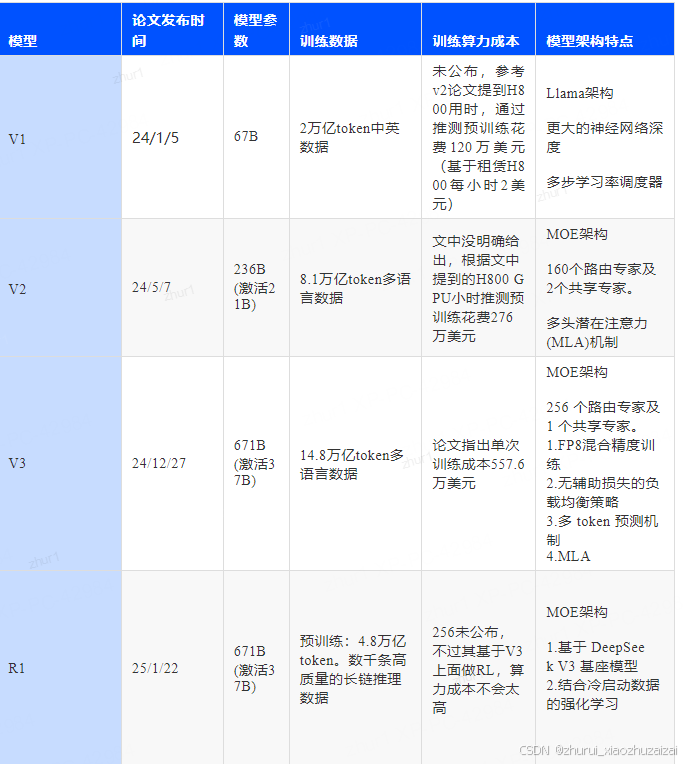
一 [deepseek-V1, LLAMA 2模型]DeepSeek LLM: Scaling Open-Source Language Models with Longtermism (2024.01.06)
1.1 预训练
- 基座模型:llama系列模型:7B, 67B
- 训练数据量:2 万亿个标记的数据集,主要以中文和英文为主
- 训练数据来源:
Computer. Redpajama: an open dataset for training large language models, 2023. URL
https://github.com/togethercomputer/RedPajama-Data.
Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite,
N. Nabeshima, et al. The Pile: An 800GB dataset of diverse text for language modeling. arXiv
preprint arXiv:2101.00027, 2020.
. Penedo, Q. Malartic, D. Hesslow, R. Cojocaru, A. Cappelli, H. Alobeidli, B. Pannier, E. Almazrouei, and J. Launay. The refinedweb dataset for falcon llm: outperforming curated
corpora with web data, and web data only. arXiv preprint arXiv:2306.01116, 2023.
Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal,
E. Hambro, F. Azhar, et al. LLaMA: Open and efficient foundation language models. arXiv
preprint arXiv:2302.13971, 2023a.- 训练数据方法:去重,过滤,混搭
- 分词器:基于 tokenizers 库(Huggingface Team,2019)实现了字节级字节对编码 (BBPE) 算法。采用预分词技术来防止来自不同字符类别(例如换行符、标点符号和中日韩(CJK)符号)的标记合并,类似于 GPT-2(Radford 等人,2019)。我们还选择按照 (Touvron 等人,2023a,b) 中的方法将数字拆分为单个数字。根据我们的前期经验,我们将词汇表中的常规标记数量设置为 100000。分词器在约 24 GB 的多语言语料库上进行了训练,我们向最终词汇表添加了 15 个特殊标记,总大小达到 100015。为了确保训练期间的计算效率并为将来可能需要的任何其他特殊标记保留空间,我们将模型的词汇表大小配置为 102400 进行训练。
- 训练方法:从头开始构建开源大型语言模型,但用多步学习率调度器替换了余弦学习率调度器,在保持性能的同时促进了持续训练
- 模型结构:采用 Pre-Norm 结构、RMSNorm函数以及 SwiGLU作为前馈网络(FFN)的激活函数,中间层维度为 。它还结合了 Rotary Embedding进行位置编码。为了优化推理成本,67B 模型使用 GroupedQuery Attention(GQA)代替传统的 Multi-Head Attention(MHA)。
- 学习率:模型的学习率在经过2000个warmup步骤后达到最大值,然后在处理80%的训练标记后降至最大值的31.6%。在处理90%的标记后,它进一步降低到最大值的10%。训练阶段的梯度裁剪设置为1.0。
- 训练框架: HAI-LLM来训练和评估大型语言模型。
还利用 flash attention技术来提高硬件利用率。ZeRO-1被用于在数据并行秩上划分优化器状态。也做出了重叠计算和通信的努力,以最大程度地减少额外的等待开销,包括最后一个微批次的 backward 过程以及 ZeRO-1 中的 reduce-scatter 操作,以及序列并行中的 GEMM 计算和 all-gather/reduce-scatter。为了加速训练,一些层/操作被融合在一起,包括 LayerNorm、GEMM(尽可能)和 Adam 更新。为了提高模型训练稳定性,我们以 bf16 精度训练模型,但在 fp32 精度中累积梯度。执行原地交叉熵来减少 GPU 内存消耗,即:我们在交叉熵 CUDA 内核中实时将 bf16 logits 转换为 fp32 精度(而不是事先在 HBM 中转换),计算相应的 bf16 梯度,并将 logits 用其梯度覆盖。- 训练结果:DeepSeek llm模型
- 评估:
DeepSeek LLM 在各种基准测试中都优于 LLaMA-2 70B,尤其是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









