 Deepseek系列大语言模型介绍与解析
Deepseek系列大语言模型介绍与解析




- 一、团队背景
Deepseek系列模型是由Deepseek公司(全称:杭州深度求索人工智能基础技术研究有限公司)研发的大语言模型。DeepSeek公司成立于 2023 年 7 ⽉,专注于研究通用人工智能底层模型与技术,挑战人工智能前沿性难题,旨在“打造低成本、⾼性能、全⾯开源的⼤语⾔模型”,试图在⾼昂成本与闭源为主导的国际⼤模型市场中,提供⼀条“平价⼜开源”的替代⽅案。
截⾄ 2025 年初,Deepseek 团队拥有约 139 名正式员⼯,核⼼成员多具有深度学习、分布式系统、GPU 底层优化等专业背景,形成“⼩团队+⾼强度”的研发文化。创始人梁⽂锋本身拥有量化⾦融与⼤数据分析的深厚背景,曾在⾼频交易、机器学习等领域积累了丰富经验,2015年,成立了Deepseek的母公司杭州幻方科技有限公司,致力于通过数学和人工智能进行量化投资,2016年幻方量化推出第一个AI模型,实现了所有量化策略的AI化转型。2017年底,几乎所有的量化策略都采用AI模型计算。 2018年,幻方正式确立了以AI为核心的发展战略。
- 二、产品系列
DeepSeek 的产品线⽬前主要分为 V 系列(Deepseek Chat) 与 R 系列(Deepseek Reasoning) 两⼤类。V 系列:主打多领域对话与内容⽣成,偏重通⽤性与⾃然语⾔覆盖⼴度。R 系列:强调推理与思维链,以深度逻辑能⼒⻅⻓。
DeepSeek 在两个系列上不断尝试新的模型架构与训练⽅法,并针对不同应⽤场景做差异化优化,逐步形成了V 系列⾯向通⽤场景、R 系列主打专家级推理的双线发展战略,同时在多模态方向进行了有益的尝试。
表1 Deepseek产品列表
| 模型名称 | 发布日期 | 发布版本 | 模型简介 |
|
Deepseek MoE | 2024-01-02 | Moe-16B-Base Moe-16B-Chat | 具有16.4B参数的混合专家(MoE)语言模型,采用基于细粒度专家分割和共享专家隔离的创新的MoE架构,在2T中英文tokens上从头训练得到,性能与DeekSeek 7B和LLaMA2 7B相当,计算量仅为其40%左右,是Deepseek系列模型的基础模型。 |
| Deepseek LLM | 2023-11-29 | LLM-7B-Base LLM-7B-Chat LLM-67B-Base LLM-67B-Chat | 在包含2T个中英文tokens的庞大数据集上从头开始训练的高级语言模型。 具备推理、编程、数学、中文等领域卓越的通用能力,尤其精通编程、数学和中文理解。 该模型是实质意义上的Deepseek V1,其性能优于GPT3.5,弱于GPT4。 |
| Deepseek Coder | 2023-10-20 | Coder-1.3B-Base Coder-1.3B-Instruct Coder-6.7B-Base Coder-6.7B-Instruct Coder-7B-Base v1.5 Coder-7B-Instruct v1.5 Coder-33B-Base Coder-33B-Instruct | 由一系列代码语言模型组成,每个模型都是在由87%的代码和13%的中英文自然语言组成的2T个tokens上从头开始训练。 每个模型都通过使用16K的窗口大小和额外的填空任务在项目级代码语料库上进行预训练,以支持项目级代码的完成和填充。在多种编程语言和各种基准测试的开源代码模型中取得了先进性能,能力表现接近GPT4. |
| Deepseek Math | 2024-02-05 | Math-7B-Base Math-7B-Instruct Math-7B-RL | 在Deepseek-Coder-v1.5 7B模型初始化条件下,用源于Common Crawl的数学相关tokens和500B的自然语言和编程数据tokens预训练得到。 在不依赖外部工具包和投票技术的情况下,竞赛级MATH基准测试中接近Gemini Ultra和GPT-4的性能水平。 |
|
Deepseek VL | 2024-03-08 | VL-1.3B-Base VL-1.3B-Chat VL-7B-Base VL-7B-Chat | 专为现实世界视觉和语言理解设计的开源视觉语言(VL)模型。 具有通用的多模态理解能力,能够处理逻辑图、网页、公式识别、科学文献、自然图像和复杂场景中的隐含智能,开启了Deepseek在多模态领域的尝试。 |
|
Deepseek Prover V1.5 | 2024-08-16 | Prover-V1 Prover-V1.5-Base (7B) Prover-V1.5-SFT (7B) Prover-v1.5-RL (7B) | Prover是一种专为Lean 4(交互式定理证明器)中的定理证明而设计的开源语言模型。V1.5模型在Deepseek Math Base上经过预训练专门学习形式数学语言,通过监督微调(SFT)和基于证明辅助反馈(RLPAF)的强化学习进一步的细化,并提出了一种变体的蒙特卡洛树搜索方法RMaxTS,用于生成不同证明路径。 Prover-V1.5在高中水平的miniF2F基准和本科生水平的ProofNet基准的测试集上取得先进的结果,远优于GPT-f。 |
| Deepseek V2 | 2024-04-22 | V2 Lite (16B) V2 Lite Chat(SFT 16B) V2(236B) V2 Chat(RL 236B) | 强大的混合专家(MoE)语言模型,特征是经济训练和高效推理。模型首先在8.1T个tokens组成的多样化和高质量的语料库上进行预训练,然后开展监督微调(SFT)和强化学习(RL),以充分释放模型的能力。 模型包含236B参数,每token激活21B参数,与LLM 67B模型相比,性能更强,且节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。在标准基准和开放式生成评估上都取得了显著的性能,验证了训练方法的有效性。 |
| Deepseek Coder V2 | 2024-06-14 | Coder-V2-Lite-Base(16B) Coder-V2-Lite-Instruct Coder-V2-Base (236B) Coder-V2-Instruct | 开源混合专家(MoE)代码语言模型, Coder V2是从V2的中间检查点额外增加了6T个tokens进一步预训练得到,大大提高了V2的编程和数学推理能力,同时在一般语言任务中保持了相当的性能,在特定代码任务中实现了与GPT4 Turbo相当的性能。 相比Coder 33B,Coder V2在代码相关任务的各个方面以及推理和通用功能方面都取得了显著进步,同时对编程语言的支持从86种扩展到338种,上下文长度从16K扩展到128K。 |
| Deepseek Coder VL2 | 2024-12-13 | VL2-Tiny (1B) VL2-Small (2.8B) VL2 (4.5B) | 大型混合专家(MoE)视觉语言模型,在 VL基础上改进得到。VL2在包括但不限于视觉问答、光学字符识别、文档/表格/图表理解和视觉基础的各类任务中表现出卓越能力。 与现有同类模型相比,VL2以相似或更少的激活参数实现了同等或更先进的性能。 |
| Deepseek V2.5 | 2024-09-05 2024-12-10 | V2.5 V2.5-1210 | V2.5是由 V2-Chat 和Coder-V2 两个模型的合并得到的,不仅保留了原有 Chat 模型的通用对话能力和 Coder 模型的强大代码处理能力,还更好地对齐了人类偏好,在写作任务、指令跟随等多个方面实现了大幅提升。 V2.5-1210是V2系列的最终版微调模型,Post-Training 全面提升了模型各方面能力表现,包括数学、代码、写作、角色扮演等;同时,优化了文件上传功能,并且全新支持了联网搜索,展现出更加强大的全方位服务于各类工作生活场景的能力。 |
| Deepseek V3 | 2024-12-26 | V3 (671B) V3-Base (671B) | 强大的混合专家(MoE)语言模型,具备高效推理能力和经济高效的训练成本,模型在14.8T个多样化和高质量tokens上进行了预训练,然后通过监督微调和强化学习,充分利用其功能。整体训练花费2.788M H800 GPU小时,成本约557.6万美元,训练过程非常稳定,在整个训练过程中,未出现任何不可挽回的损失高峰或任何倒退。 V3模型总参数671B,每token激活37B,采用多头潜在注意力(MLA)和DeepSeek MoE架构,开创了一种无辅助损失的负载均衡策略,并采用多token预测目标以提高性能。 V3的性能表现优于其他开源模型,并可媲美领先的闭源模型,综合能力超过GPT 4o。 |
| Deepseek R1 | 2025-01-20 | R1-Zero (671B) R1 (671B) R1-Distill-Qwen-1.5B R1-Distill-Qwen-7B R1-Distill-Llama-8B R1-Distill-Qwen-14B R1-Distill-Qwen-32B R1-Distill-Llama-70B | Deepseek的第一代推理模型,包含R1-Zero和R1两个主版本和基于Llama和Qwen的六个蒸馏版本。 R1-Zero仅通过大规模强化学习(RL)训练得到,没有监督微调(SFT)过程,模型在推理方面表现出色,但存在无休止重复、可读性差和语言混合等问题。 R1模型通过冷启动、推理强化学习(RL)、监督微调(SFT)和全场景强化学习(RL)等四个步骤训练,进一步提高推理性能,并解决了R1-Zero存在的问题。 R1在数学、代码和推理任务方面的性能与OpenAI-o1相当。R1-Distill-Qwen-32B在各种基准测试中表现优于OpenAI-o1-mini。 |
| Deepseek Janus | 2024-10-18 2024-11-13 2025-01-27 | Janus-1.3B JanusFlow-1.3B Janus-Pro-1B Janus-Pro-7B | Janus系列包含Janue、JanusFlow和JanusPro三个版本。 Janus是一个将多模态理解和生成统一起来的新自回归框架,将视觉编码解耦到单独的路径中,不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。其简单性、高度灵活性和有效性使其成为下一代统一多模态模型的有力候选者。 JanusFlow引入了一种极简主义架构,将自回归语言模型与校正流相结合,在大型语言模型框架内直接训练,消除了对复杂架构修改的需要,并在各领域的性能与专用模型相当或更优,在标准基准测试中明显优于现有方法。 Janus Pro是Janus和JanusFlow的高级版本。Janus Pro优化了训练策略,扩展了训练数据,并扩展到更大的模型尺寸。通过这些改进,Janus Pro在多模态理解和文本到图像指令跟踪功能方面取得了重大进展,同时也提高了文本到图像生成的稳定性。 |
- 技术解析
- Deepseek-V3技术报告解析
模型架构:Deepseek-V3延续了Deepseek-V2的模型架构,主要对专家网络MoE和Transformer进行了改进,Transformer使用多头潜在注意力(MLA),专家网络则是DeepSeek-MoE,同时采用多token预测(MTP)提升训练和预测效率。
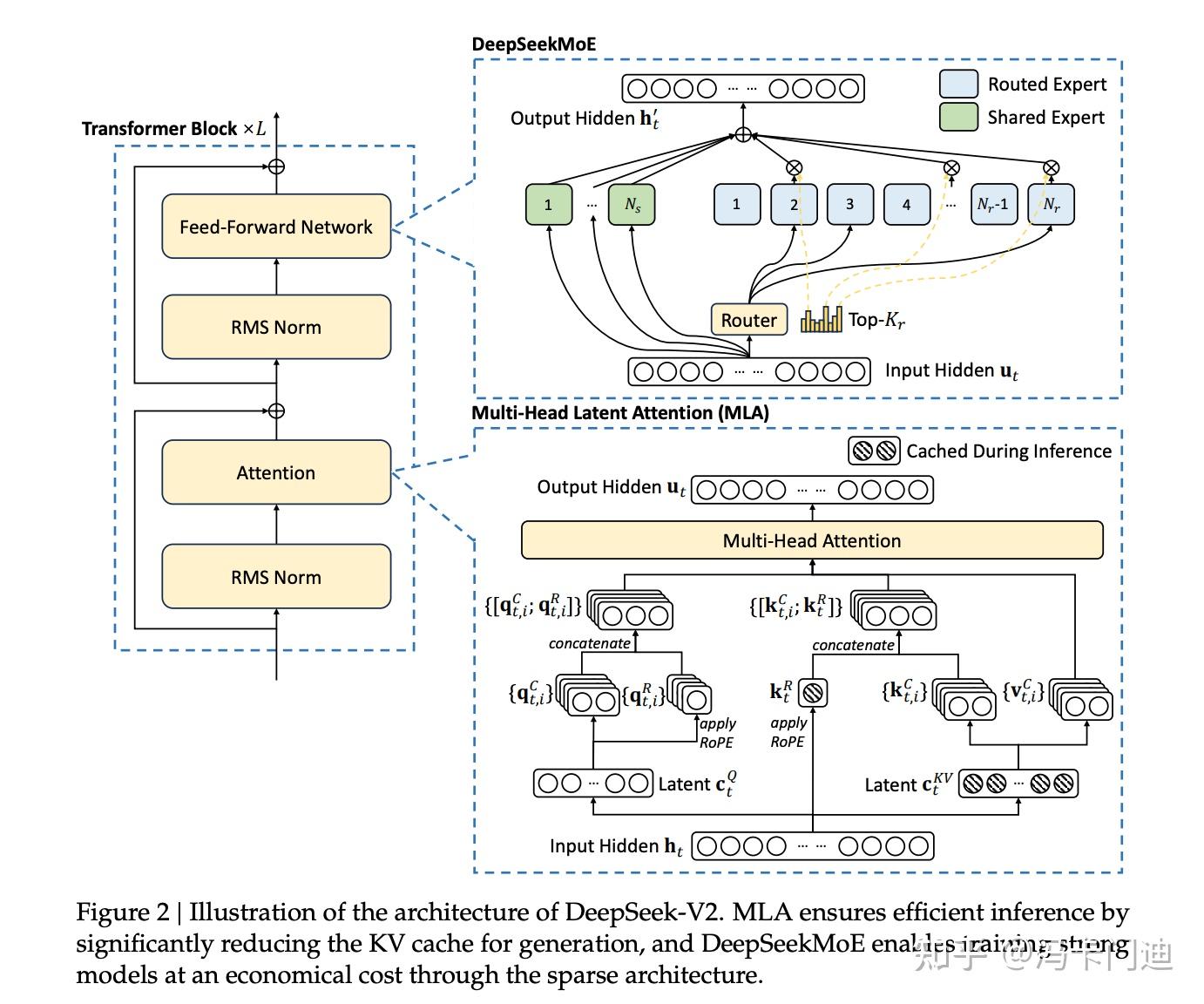
图1 Deepseek V3架构
MLA 的核心是对Transformer中的K-V键值进行低秩联合压缩,以减少推理时的键值(KV)缓存。通过一系列线性变换和操作,将输入的隐藏状态转换为压缩的潜在向量,从而降低存储需求。在这个过程中,仅需缓存特定向量,就能在保持性能的同时显著减少 KV 缓存。
Deepseek MoE架构将专家网络分位共享专家(Shared Expert)和路由专家(Routed Expert),对于共享专家,所有的输入都会传入;对于路由专家,首先通过门控网络进行“分流”,根据输入的特征,动态地决定将输入样本分配给哪些专家网络进行处理。例如,在处理不同领域的文本时,门控网络可以将金融领域的文本分配给擅长处理金融信息的专家网络,将医疗领域的文本分配给擅长处理医疗信息的专家网络。同时,DeepSeek-V3 首创了一种无辅助损失的负载均衡策略,通过对门控网络进行优化,使得样本能够在不同专家网络之间自然地实现负载均衡,而无需额外的辅助损失,避免辅助损失对模型性能的干扰,同时确保各个专家网络能够得到充分利用。
多token预测(Multi - Token Prediction,MTP)是一种训练目标,区别于传统的一次只预测一个token的方式,允许模型一次预测多个额外的token。在预测多个token的过程中,MTP 会保持完整的因果链。这意味着模型在预测后续token时,会依据前面已经预测出的token信息,确保预测结果符合语言的上下文逻辑和因果关系。例如,在文本生成任务中,预测下一个句子时会考虑前面已经生成的内容,使得生成的文本连贯合理。
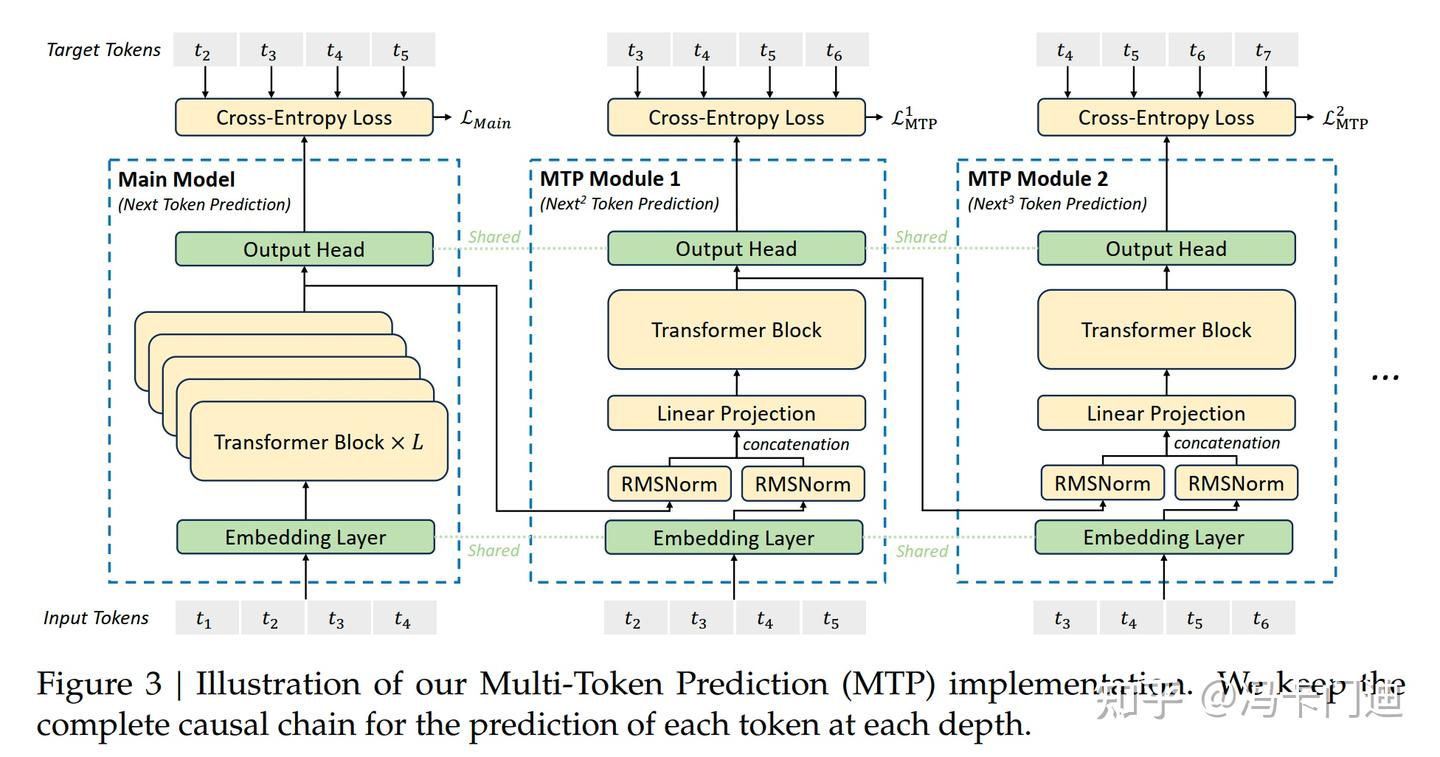
图2 MTP原理示意
训练架构:为了提高计算效率,Deepseek-V3采取了 FP8 混合精度训练和优化训练框架两项关键举措。
FP8 混合精度训练框架,在Deepseek-V3上首次验证其有效性,该框架支持 FP8 计算和存储,能加速训练并减少 GPU 内存使用。
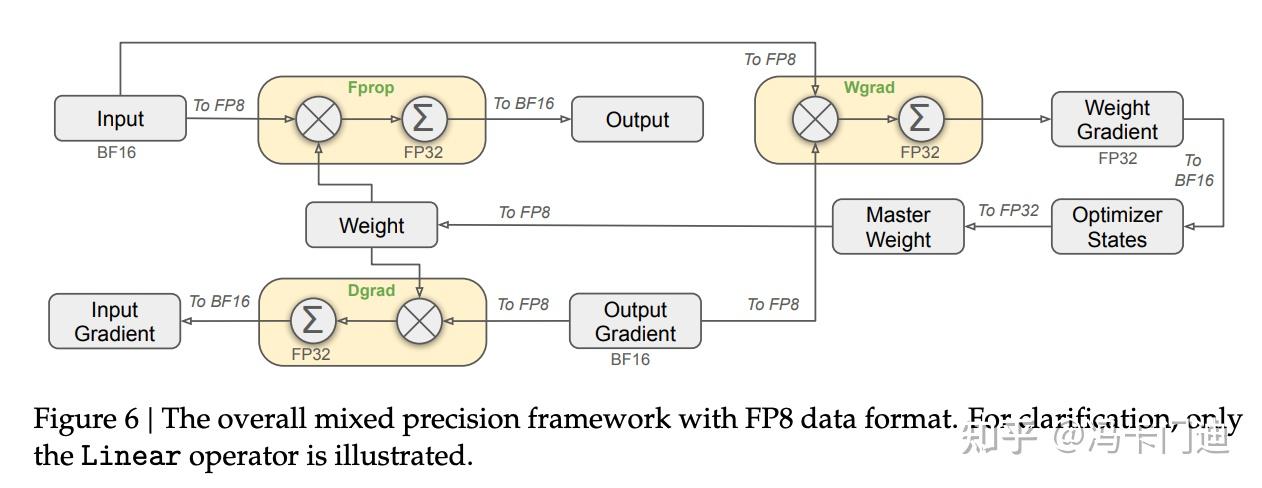
图3 FP8 混合精度训练框架
在优化训练框架上,Deepseek-V3设计了对偶管道(DualPipe)算法实现高效流水线并行,通过计算-通信重叠隐藏大部分训练时的通信开销,保证模型扩展时可跨节点使用细粒度专家且全对全通信开销近乎为零;为了充分利用 InfiniBand(IB)和 NVLink 带宽,还做了跨节点的all-to-all通信内核;同时对内存占用也做了优化,使 DeepSeek-V3 训练无需使用成本高昂的张量并行。
模型预训练:预训练过程对语料库做了优化,增加了数学和编程样本的比例,使用 14.8 万亿个tokens对 DeepSeek-V3 进行训练,整个训练过程没有出现损失峰值或回滚情况,十分稳定。同时采用分布阶段,将上下文窗口进行扩展,第一阶段将最大上下文长度扩展到 32K,第二阶段进一步扩展到 128K。
模型后处理:后处理包含微调和强化学习两部分。
微调过程对 DeepSeek-V3-Base 进行两轮微调,其微调数据集包含 1.5M 个实例,涵盖多个领域,对于推理类任务,比如生成数学、代码竞赛问题和逻辑谜题的数据,使用内部 DeepSeek-R1 模型生成并进行优化筛选,对于非推理类任务,比如创意写作、角色扮演和简单问答,通过 DeepSeek-V2.5 生成,再通过人工标注验证生成数据的准确性和正确性。
强化学习过程Deepseek-V3采用基于规则和基于模型的奖励模型,并使用组相对策略(GRPO, Group Relative Policy Optimization)进行优化。
训练成本:
表1 Deepseek-V3训练成本核算
| 训练花销 | 预训练 | 上下文扩展 | 后处理 | 总花销 |
| H800 GPU小时 | 2664K | 119K | 5K | 2788K |
| 美元 | $5.328M | $0.238M | $0.01M | $5.576M |
性能表现:
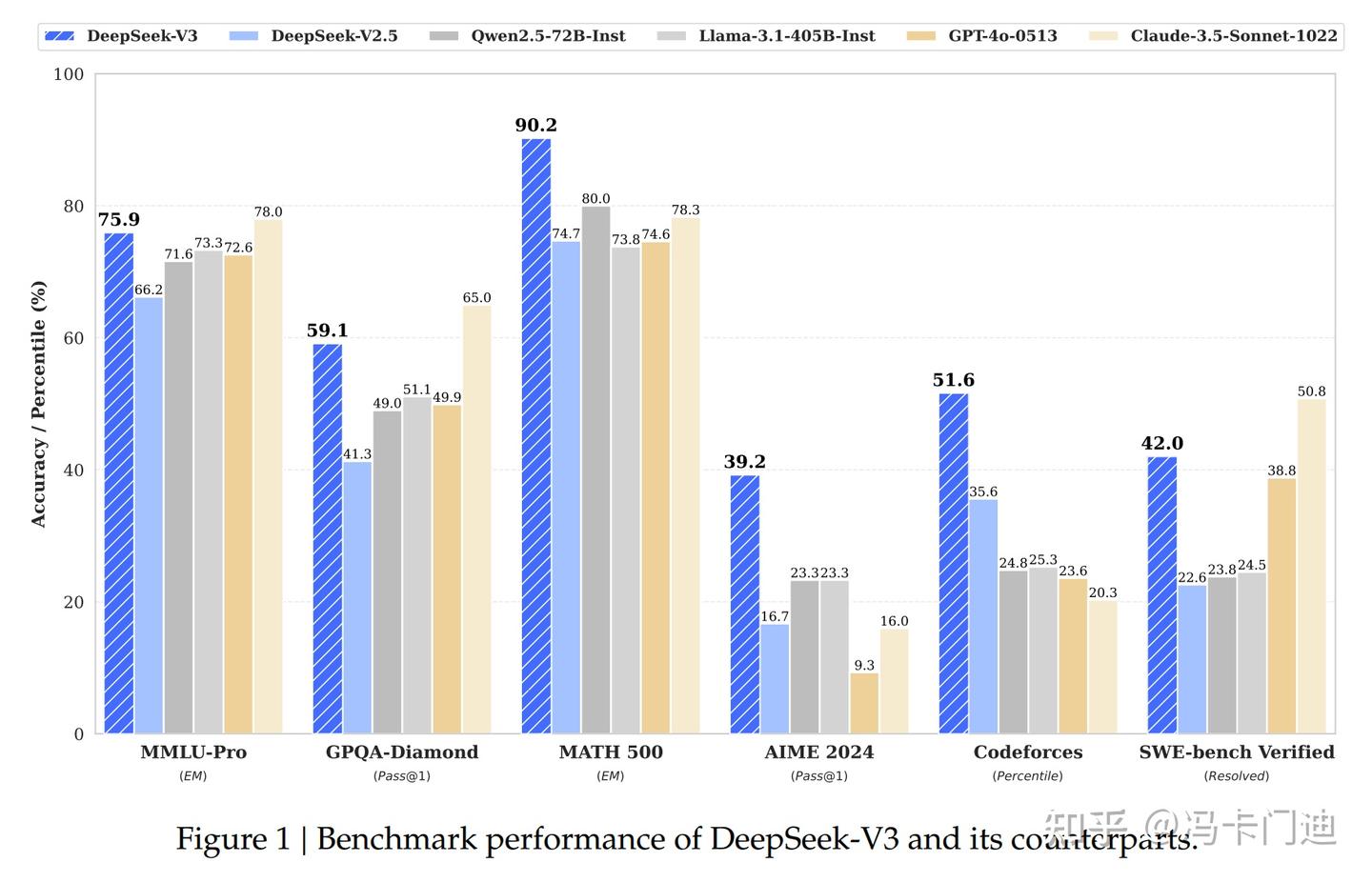
图4 Deepseek-V3性能表现
(注:MMLU-Pro为大规模多任务语言理解基准测试;GPQA-diamond 是智能测试基准,考察化学、物理和生物学方面的专业知识;MATH-500包含500个测试样本的MATH评测集,全面考察数学解题能力;AIME指美国数学邀请赛;Codeforces是编程测试评估基准;SWE-bench Verified是软件工程任务测试基准。)
通过各项基准测试,Deepseek-V3的性能优越性主要体现在:
整体性能出色,在多项基准测试中,DeepSeek-V3 的表现优于众多开源模型,且能与领先的闭源模型相媲美。以 MMLU-Pro 任务为例,DeepSeek-V3 的准确率达到 75.9% ,高于其他开源模型,和领先闭源模型处于相近水平,表明其在知识理解和掌握方面能力强劲。
数学推理能力突出,在 MATH 500 等数学相关基准测试中,DeepSeek-V3 的表现遥遥领先。体现出它在数学推理、解题等方面具备很强的能力,相比其他开源和部分闭源模型有明显优势,能有效处理复杂数学问题。
编程能力优秀,在 Codeforces 等编程竞赛基准测试里,DeepSeek-V3 成绩相比其他模型“腰斩式”领先,反映出它在编程任务上的卓越能力,如代码生成、算法实现等方面表现出色,可满足编程领域的多种需求。
- Deepseek-R1 技术报告解析
主要贡献:Deepseek-R1聚焦通过强化学习(RL)提升大型语言模型(LLM)的推理能力,作出三个主要贡献。
一是首次验证了纯强化学习在 LLM 中显著增强推理能力的可行性(DeepSeek-R1-Zero),即无需预先的 监督微调(SFT)数据,仅通过强化学习(RL)即可激励模型学会长链推理和反思等能力。
二是提出了多阶段训练策略(冷启动->RL->SFT->全场景 RL),有效兼顾准确率与可读性,产出 DeepSeek-R1,性能比肩 OpenAI-o1-1217。
三是展示了知识蒸馏在提升小模型推理能力方面的潜力,并开源多个大小不一的蒸馏模型(1.5B~70B),为社区提供了可在低资源环境中也能获得高推理能力的模型选择。
Deepseek-R1-Zero训练过程:
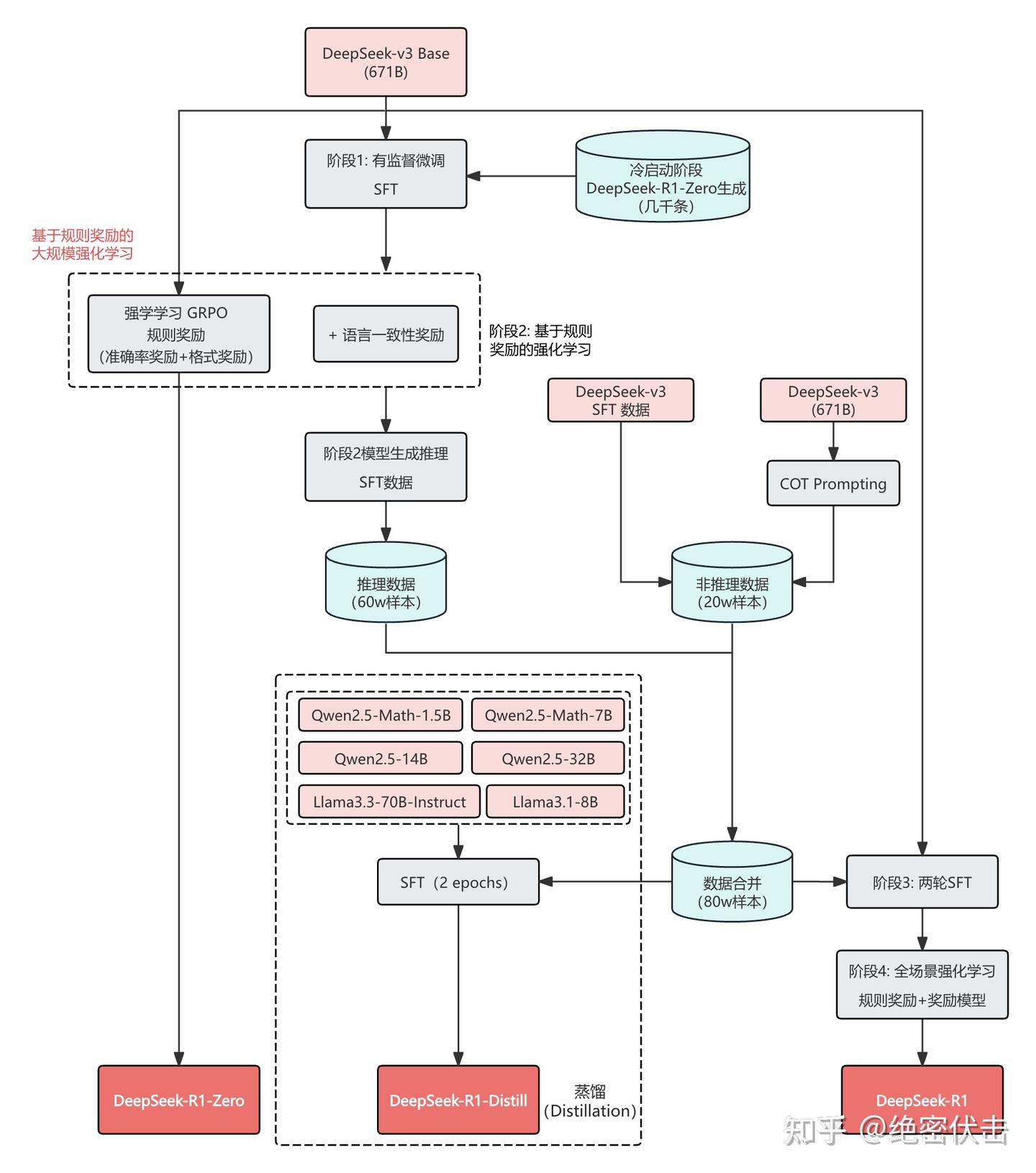
图5 Deepseek-R1训练示意图
DeepSeek-R1-Zero 直接在Deepseek-V3-Base上应用强化学习,不使用任何监督微调数据。强化训练采用了一种基于规则的奖励系统,主要由两种奖励组成。
一是准确率奖励,用于评估响应是否正确。例如,在具有确定性结果的数学问题中,模型需要以指定的格式提供最终答案,从而能够通过基于规则的验证来可靠地确认正确性。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。
二是格式奖励,要求模型将其思考过程放在<think>和</think>标签之间。
在 DeepSeek-R1-Zero 的训练历程中,出现了一个特别引人注目的现象——“顿悟时刻”(aha moment)。如图6所示,顿悟时刻发生在模型的思考阶段,模型通过重新审视其初始策略,学会了为问题分配更多思考时间。这一行为说明模型推理能力的显著提升,也展示了强化学习(RL)的强大潜力,可以让模型在没有明确指导的情况下,自主学习并改进。

图6 Deepseek-R1-Zero顿悟时刻
Deepseek-R1训练过程:
DeepSeek-R1 使用了冷启动 + 多阶段训练的方式,包含四个阶段。
阶段1,使用少量高质量的思维链(CoT)数据进行冷启动,预热模型。
为获取CoT数据,探索了几种策略,例如利用长思维回答作为 few-shot 示例,直接提示模型生成包含反思和验证步骤的详细答案;收集 DeepSeek-R1-Zero 的输出并通过人工标注进行细化。最终收集了数千条冷启动数据,微调 DeepSeek-V3-Base 作为 RL 训练起点。
阶段2,进行面向推理的强化学习,提升模型在推理任务上的性能。
推理强化学习,引入语言一致性奖励,该奖励根据思维链(CoT)中目标语言单词的比例来计算,以减少推理过程中的语言混合问题,使模型更符合人类的偏好,提高了内容的可读性。通过将推理任务的准确性与语言一致性奖励直接相加,形成了综合的奖励函数,对微调后的模型进行了强化学习(RL)训练,直至其在推理任务上达到收敛。
阶段3,使用拒绝采样和监督微调,进一步提升模型的综合能力。
监督微调阶段旨在提升模型的综合能力,使其在写作、事实问答等多种任务上表现良好。微调数据集包含60W推理数据,由上一阶段模型拒绝采样和优化筛选生成,20W非推理数据,共用 DeepSeek-V3监督微调数据集的一部分。然后用这80W微调数据对 DeepSeek-v3-Base 模型进行了两轮的监督微调。
阶段4,全场景强化学习,使模型在所有场景下都表现良好,并且保证模型的安全性和无害性。
包括推理任务和非推理任务,对于推理数据,使用DeepSeek-R1-Zero的方法,利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,利用奖励模型,捕捉复杂和微妙场景中的人类偏好。
蒸馏小模型:
为了获得更高效的小模型,并使其具有 DeekSeek-R1 的推理能力,直接对 Qwen 和 Llama 等开源模型进行了微调(不包括强化学习),使用的是微调 DeepSeek-R1 的80万数据。研究结果表明,这种直接蒸馏方法显著提高了小模型的推理能力。
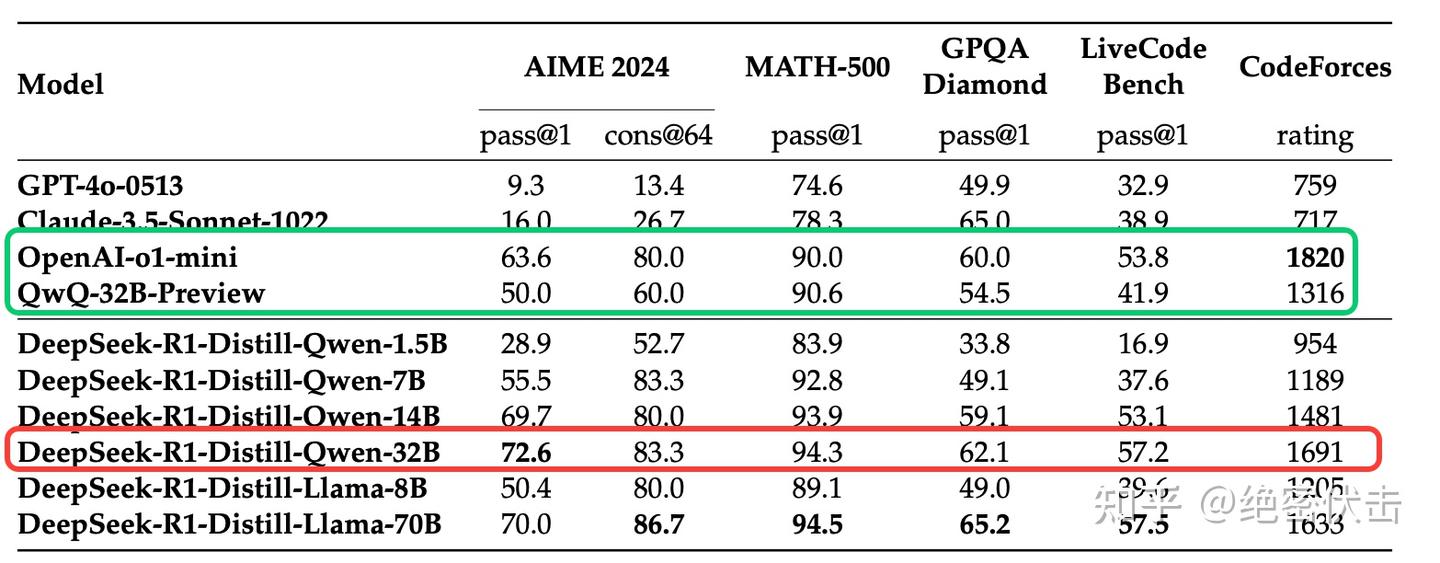
图7 蒸馏模型测试结果
通过简单蒸馏 DeepSeek-R1 的输出,得到 DeepSeek-R1-Distill-Qwen-7B,其在所有方面均优于非推理模型 GPT-4o-0513。DeepSeek-R1-14B 在所有评估指标上均超越了 QwQ-32BPreview。DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准测试中均显著优于 o1-mini。
性能表现:
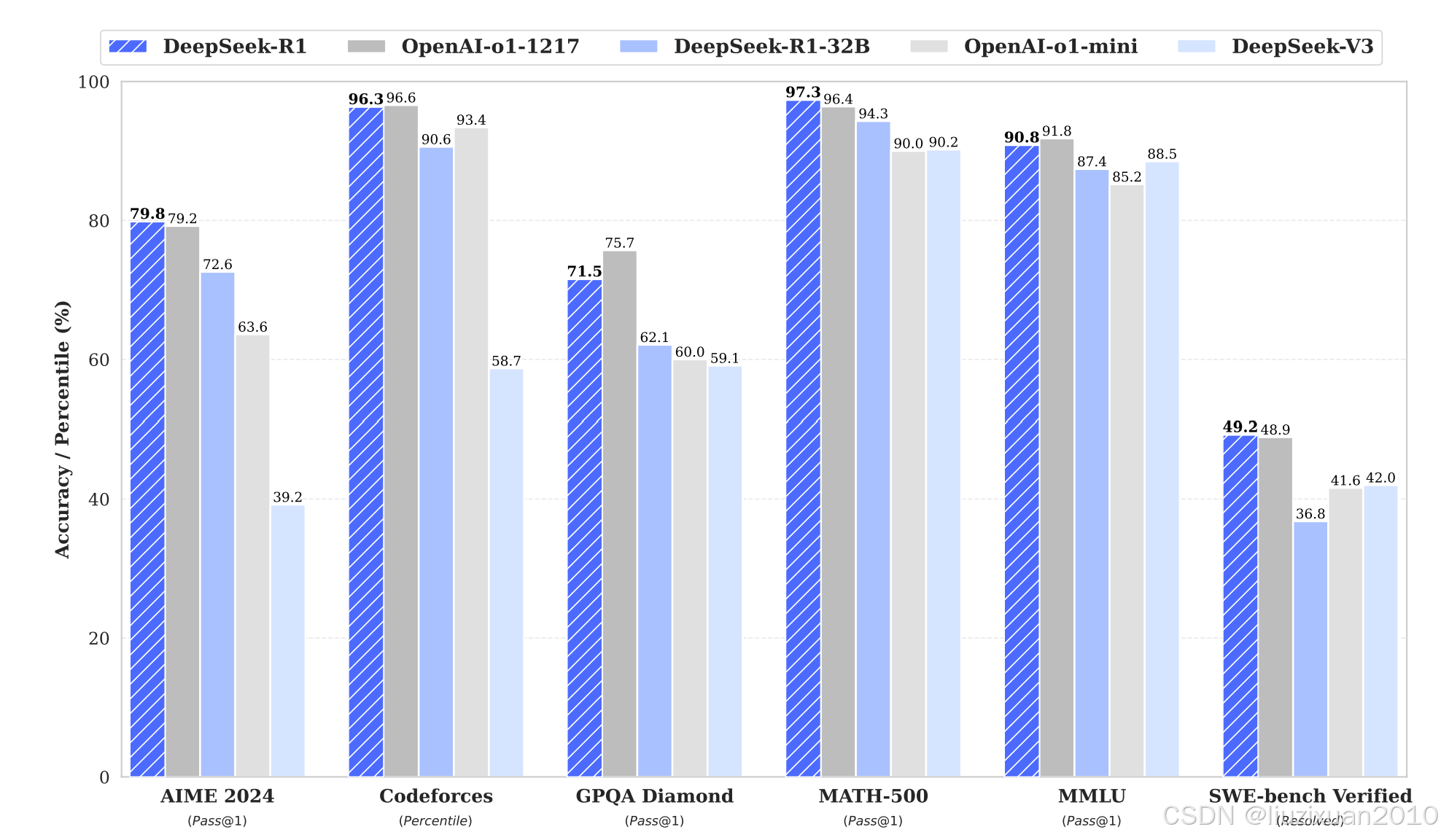 图8 Deepseek-R1性能测试
图8 Deepseek-R1性能测试
(注:AIME指美国数学邀请赛;Codeforces是编程测试评估基准; GPQA-diamond 是智能测试基准,考察化学、物理和生物学方面的专业知识;MATH-500包含500个测试样本的MATH评测集,全面考察数学解题能力;MMLU为大规模多任务语言理解基准测试; SWE-bench Verified是软件工程任务测试基准。)
Deepseek-R1在测试中展示出卓越的推理能力。
全面超越Deepseek-V3,DeepSeek-R1在几项基准测试上都展现了超越 DeepSeek-V3 的性能。
推理能力与OpenAI-o1-1217持平,DeepSeek-R1 在推理任务上的性能与 OpenAI-o1-1217 相当,超过其他模型。
- 技术创新总结
DeepSeek在有限算⼒与资⾦投⼊的前提下,之所以能训练出与国际顶尖⼤模型相当、甚⾄在某些维度更具优势的模型,归功于其在数据、模型、系统、硬件这四⼤关键环节的系统性创新。
数据集准备创新:极少⼈⼯标注 + 强机器⾃学习。具体包括⼩样本⼈⼯标注与基础对⻬、⾃动判分与机器⾃学习和AI 教 AI的循环⾃增强,达到大幅减少人工成本、加速模型自适应和更深度推理能力的效果。
模型训练架构创新:MLA + MoE + MTP。融合多头潜在注意力(MLA)、混合专家(MoE)和多Token并行预测(MTP)的模型架构,使 DeepSeek 既具备超⼤模型容量(因 MoE 稀疏扩张)和⾼训练效率(因 MLA、MTP ),⼜能在⻓序列或复杂推理中保持性能不衰减。这一Transformer 变体架构在DeepSeek‐V3、R1 中均得到验证,对提升模型质量与降低训练成本⽴下“核⼼功劳”。
算⼒调配系统创新:HAI-LLM、负载均衡、FP8 等。DeepSeek ⾃研的 HAI-LLM (Highly Automated & Integrated LLM Training)框架融合了分布式并行计算、通信优化与负载均衡、FP8混合精度与内存管理等技术,⼤幅提升了集群利⽤率与通信效率,使算力利用率显著提升,训练周期缩短,通信瓶颈显著降低,达到低成本训练的目标。
底层硬件调⽤创新:绕过 CUDA,直接使⽤ PTX。通过PTX指令级编程,实现Token-to-Expert的动态分配和通信调度,开发了通用矩阵乘法内核,支持FP8混合精度计算,在 H800 集群上实现与 A100/H100 相近的运算效率,使其在被封锁或受限的硬件环境下依旧可以实现“⼩投⼊训练⼤模型”。
DeepSeek系列模型的创新探索,使其在与 GPT-4 等巨型闭源模型的竞争中,依靠“创新”⽽⾮“单纯的⾼算⼒投⼊”赢得了⼀席之地。
表2 模型训练成本对比
| 模型 | 参数规模 | 训练成本 | 开源/闭源 | 强项 |
| DeepSeek-V3 | 6710 亿 (MoE稀疏) | ~557.6 万美元 | 开源 (MIT) | 通⽤对话、⾼效率稀疏架构 |
| DeepSeek-R1 | ~6600 亿 (MoE稀疏) | ~600万美元 | 开源 (MIT) | 复杂推理、数 |
| GPT-4 (OpenAI) | ~1.8 万亿 (推测) | 数千万~上亿美元 | 闭源 | 通⽤对话、多模态(部分) |
| Claude 2 | 未公开 | 数千万美元级 | 闭源 | 多轮对话安全、对⻬ |
- 四、应用领域
Deepseek可以直接面向用户或支持开发者,提供智能对话、文本生成,语义理解、计算推理,代码生成补全等应用场景,并支持联网搜索和深度思考模式。
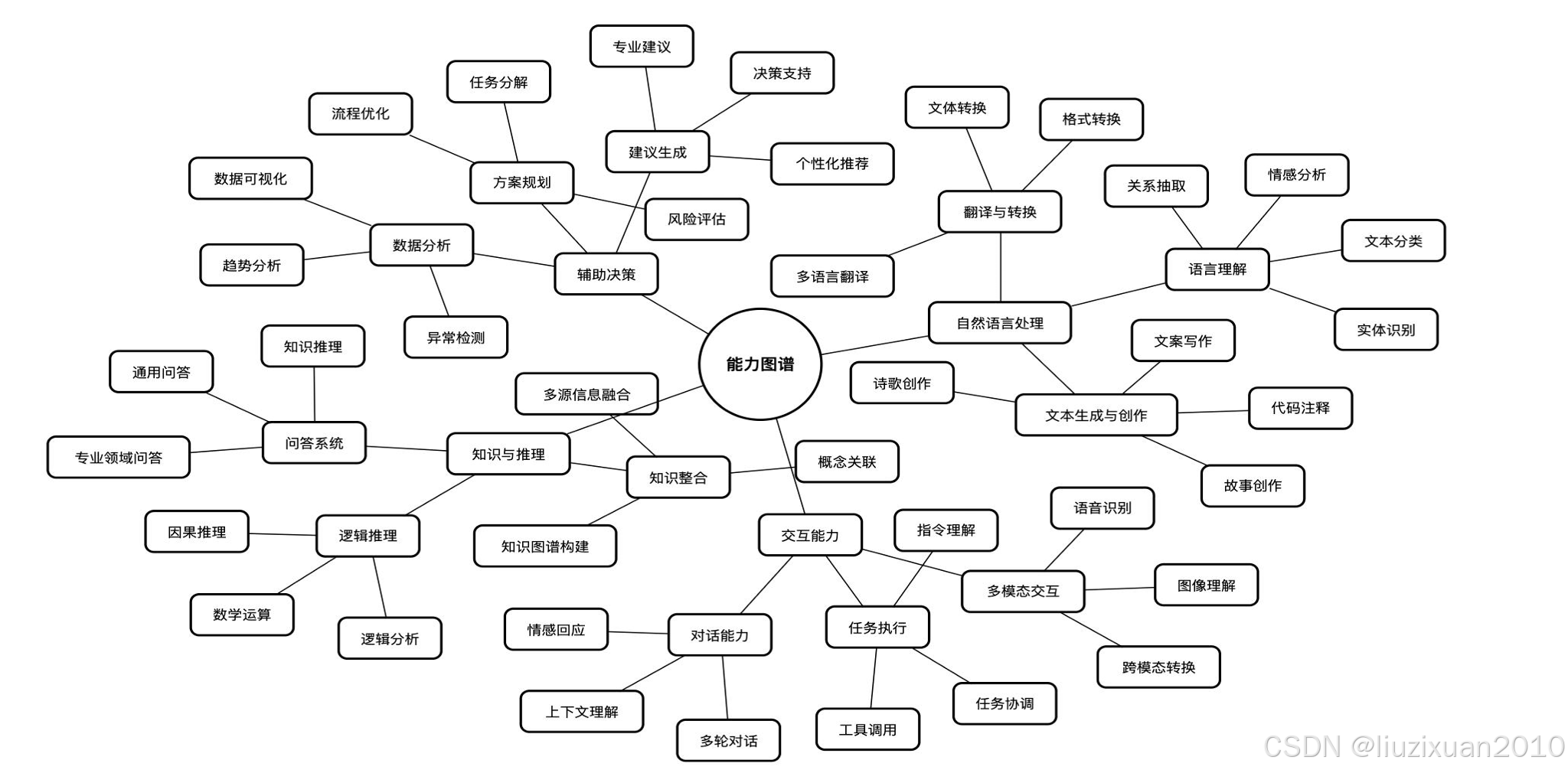
图8 大语言模型能力图谱
文本生成:包含文本创作,如文章写作、剧本或对话设计等;摘要与改写,如长文本摘要生成,多语言翻译与本地化等;结构化生成,如表格、列表生成,代码注释、文档撰写等。
自然语言理解与分析:包含语义分析,如语义解析、情感分析、意图识别等;文本分类,如主题标签生成、垃圾内容检测等;知识推理,如逻辑问题解答、因果分析等。
编程与代码:包含代码生成,如自动补全与注释生成等;代码调试,如错误分析与修复、代码性能优化提示等;技术文档处理,如API文档生成、代码库解释与示例生成等。
常规绘图,包含SVG矢量图、Mermaid图表、React图表等。
参考文献:
1.https://zhuanlan.zhihu.com/p/20568497248 知乎.冯卡门迪 《过个好年|DeepSeek-V3技术报告|万字归总|学习解读》
2.https://zhuanlan.zhihu.com/p/19868935152 知乎.绝密伏击 《DeepSeek-R1 技术报告解读》
3.清华大学新闻与传播学院 新媒体研究中心 元宇宙文化实验室 《DeepSeek:从入门到精通》
4.netseek & chatgpt o1整理材料《DeepSeek 与 DeepSeek-R 专业研究报告》

















 1143
1143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









