







1 .训练误差和泛化误差
1.训练误差:在训练数据上表现的误差
2.泛化误差: 在任意测试数据集上的误差期望
训练误差小于等于泛化误差。由于无法估计泛化误差,所以一味降低训练误差并不意味着泛化误差会降低。
机器学习模型应该降低泛化误差。
2.如何选择模型
2.1 验证数据集
预留验证集,判断验证集在模型中的表现能力 Validation Set
2.2 K 折交叉验证
当训练数据不够,不能预留很多验证数据,使用 K 折。
将训练数据集分成 K个不重合的子集,做 K 次模型训练和验证。用一个验证,k-1 个训练
最后对 k 次训练误差和验证误差分别求平均
3. 过拟合欠拟合
欠拟合: 模型过于简单,训练误差降不下去
过拟合: 模型过于复杂,训练误差很小,测试误差很大
选择合适的模型复杂度解决过拟合和欠拟合
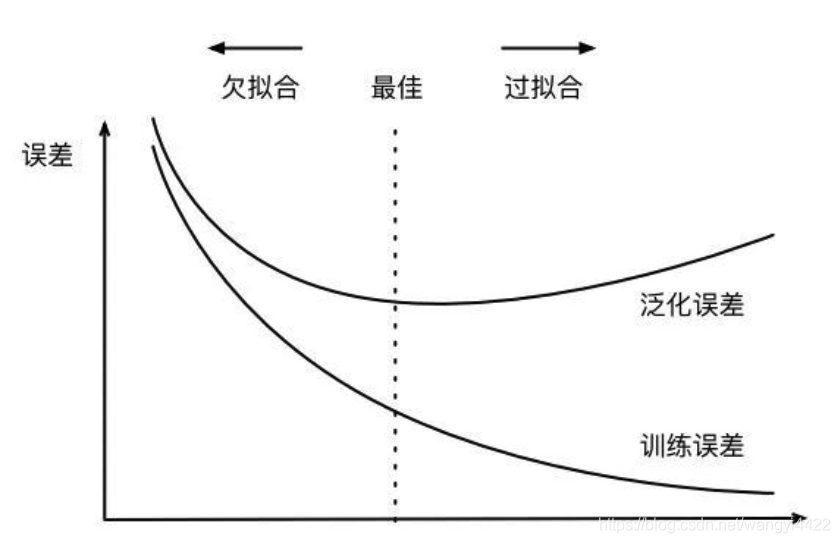
训练数据集大小
模型复杂度大,需要的训练数据大小就更大。训练样本少,比模型参数量少,过拟合容易发生。
正则化
权重衰减 = L2 范数正则化
4.DropOut
倒置丢弃法(inverted dropout):不改变输入的期望值
反向传播时,清零的神经元梯度为 0
原理:所有神经元都可能为 0,因此输出层的计算无法过度依赖神经元,从而起到正则化的作用,降低过拟合。
测试模型时不使用 DropOut
5.梯度消失/梯度爆炸
不合理的初始化和激活函数(sigmoid) 会导致梯度过大或过小,引起消失或爆炸
策略:
1. 预训练➕微调
一层一层训练 ,用的不多
2.梯度剪切、正则
1.梯度剪切针对梯度爆炸,当梯度大于某个阈值,强制限制在阈值范围内
2.权重正则化(weithts regularization)比较常见的是L1和L2正则。
3.ReLU 、LeakReLu
4、Batch Normalization
具有加速网络收敛速度,提升训练稳定性的效果
通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
残差的方式,能使得深层的网络梯度通过跳级连接路径直接返回到浅层部分,使得网络无论多深都能将梯度进行有效的回 传
LSTM 主要原因在于LSTM内部复杂的“门”(gates)。在计算时,将过程中的梯度进行了抵消。
6. 随机梯度下降法(SGD)
1. mini-batch梯度下降
-
batch_size=1,就是SGD, 噪声多,效率低
-
batch_size=n,就是mini-batch 效率高,收敛快
-
batch_size=m,就是batch 相对噪声低,幅度稍大
-
2 调节 Batch_Size 对训练效果影响到底如何?
-
Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
-
随着 Batch_Size 增大,处理相同数据量的速度越快。
-
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
-
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
-
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
7.优化算法
1.动量法
每次迭代是根据当前位置的梯度更新变量会有一些问题,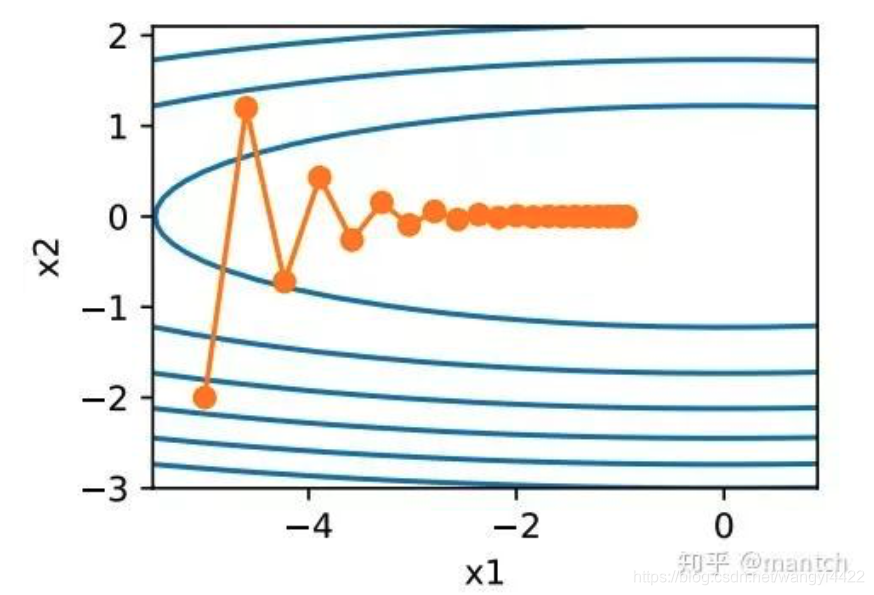
x2 方向的梯度比x1 上的大 要解决问题就需要采用更小的学习率,但是学习率小了,就会使得移动缓慢 ,效率低下
动量梯度法:在动量法中,⾃变量在各个⽅向上的移动幅度不仅取决当前梯度,还取决于过去的各个梯度在各个⽅向上是否⼀致。我们就可以使⽤较⼤的学习率,从而使⾃变量向最优解更快移动。
2 .AdaGrad算法
AdaGrad算法,它根据⾃变量在每个维度的梯度值的⼤小来调整各个维度上的学习率,从而避免统⼀的学习率难以适应所有维度的问题。


当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到⼀个有⽤的解。
3 .RMSProp算法

4 .AdaDelta算法

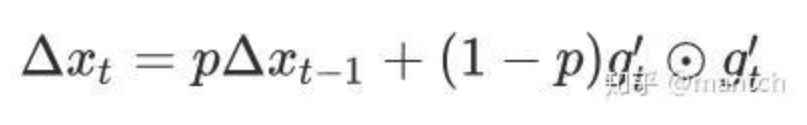
5 Adam算法
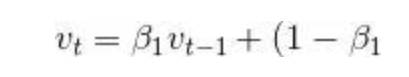
超参数0 ≤ β1 < 1(算法作者建议设为0.9
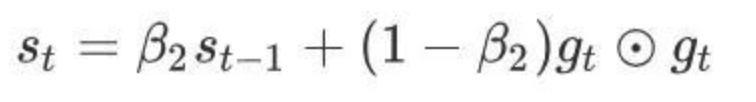
超参数0 ≤ β2 < 1(算法作者建议设为0.999
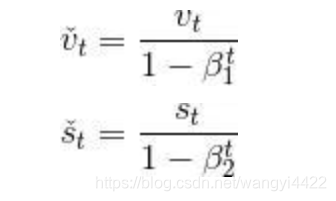
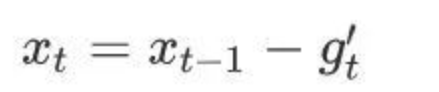
8.如何提升模型的稳定性?
-
1.正则化(L2, L1, dropout):模型方差大,很可能来自于过拟合。正则化能有效的降低模型的复杂度,增加对更多分布的适应性。
-
2。前停止训练:提前停止是指模型在验证集上取得不错的性能时停止训练。这种方式本质和正则化是一个道理,能减少方差的同时增加的偏差。目的为了平衡训练集和未知数据之间在模型的表现差异。
-
3.扩充训练集:正则化通过控制模型复杂度,来增加更多样本的适应性。
-
4.特征选择:过高的特征维度会使模型过拟合,减少特征维度和正则一样可能会处理好方差问题,但是同时会增大偏差。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









