




记录一次VideoLLaMA2部署与微调过程。由于Videollama2的训练数据集为英文数据集,对中文视频理解较差,因为课设的主题是对中文视频进行总结,所以我们用中文图片视频数据集对模型进行微调,记录如下。模型的部署和微调都是从0开始,如有错误之处欢迎指正
服务器环境
平台:SCNet超算互联网,链接:超算互联网 (scnet.cn)
部署环境:RTX4090 24GB
- pytorch=2.2.0
- python=3.10
- ubuntu=22.04
- cuda=12.1
模型版本
Videollama2-7B
Visual Encoder:clip-vit-large-patch14-336
Language Decoder:Mistral-7B-Instruct-v0.2
模型下载
进入Videollama2官方链接,找到自己需要的模型,进入对应的huggingface页面进行下载
进入对应的页面,例如clip-vit-large-patch14-336
将里面的文件全部下载下来,存入一个对应的文件夹中(最好以模型的名字进行命名的文件夹),我创建了一个存放所有模型的文件夹命名为videollama2,然后将下载的模型文件存入对应命名的文件夹之后,再统一存放在这个文件夹里。
做好这些之后,将这个文件夹上传超算互联网平台,创建NoteBook实例,接下来是环境配置。
环境配置
添加国内源(可选,此处是清华源,未验证是否有效)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install flash-attn==2.5.8 --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
可能在安装flash-attn时会出现报错,无法安装,可以多尝试几次。之后再
pip install -r requirements.txt在安装过程中,会出现一些报错,上网搜索解决即可。如出现:ImportError: libGL.so.1: cannot open shared object file: No such file or directory
运行
sudo apt-get update
sudo apt-get install libgl1-mesa-glx
模型部署
环境配置完成之后,还需要修改配置文件中的模型路径
在Videollama2 huggingface模型文件夹中(我的是Videollama-7B)有一个config.json文件,将里面的"_name_or_path"和"mm_vision_tower"部分的路径进行更改,改成你的模型路径。模型部署准备部分完成了。
在 Videollama2-main文件夹的gradio_web_server_adhoc.py文件中,也要将model_path的路径进行更改,换成你的Videollama-7B文件夹对应的路径。最后把gradio_web_server_adhoc.py的最后一行改为demo.launch(share=True),避免出现网页无法访问的问题。之后在终端中运行即可。
模型微调部分
首先是数据集要求。
你需要在videollama2-main文件夹中创建一个dataset文件夹,里面的内容如上图。
custom.json文件为训练内容,如下图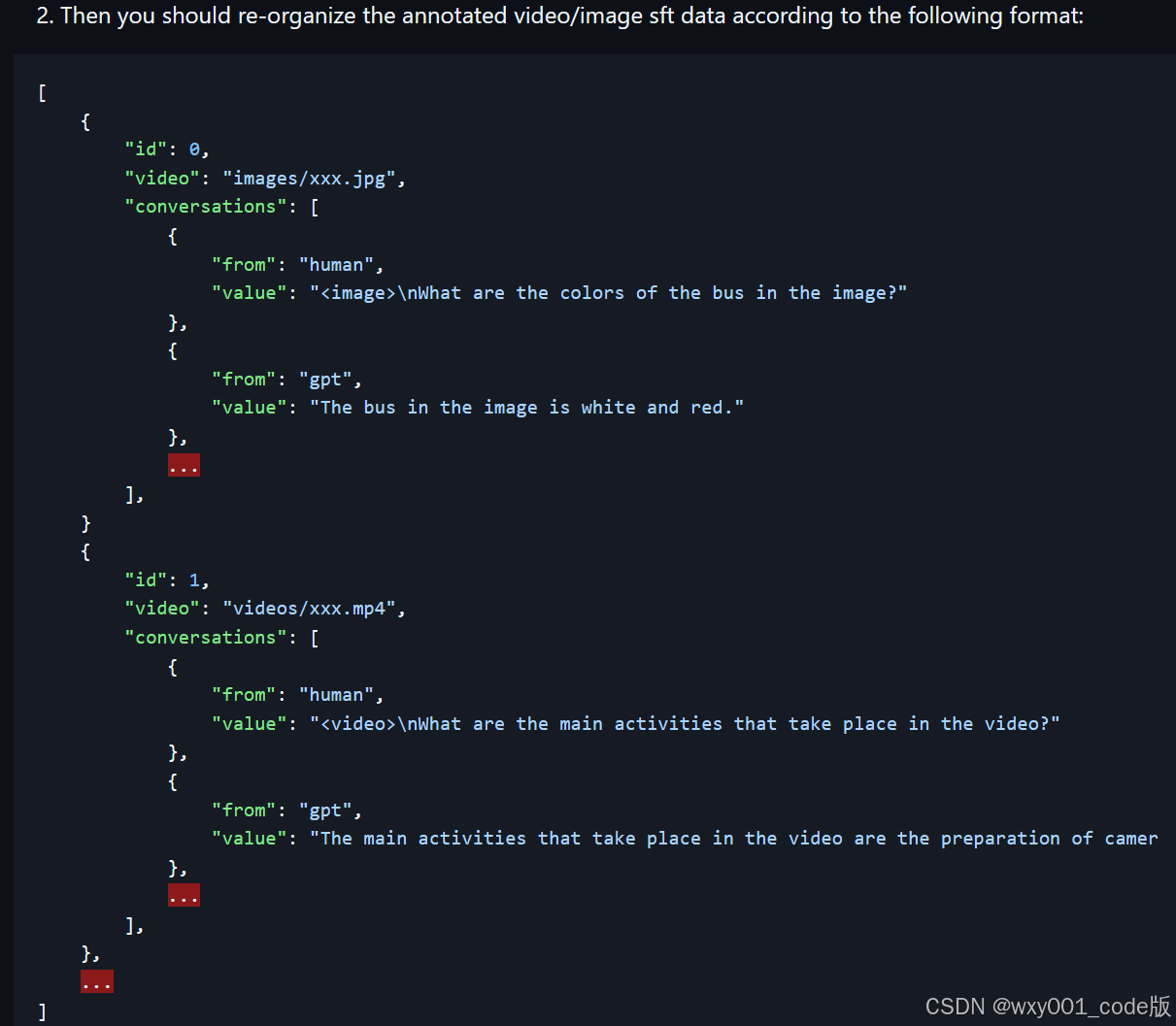
id内容可以任意,图片对应的键可以为:“video”也可以为:“image”,路径对应,就我训练的情况而言,内容必须一张图片和一段视频成一组,按照图中的格式,图片和视频的内容不需要有关联。
模型训练
我花在这部分的时间是最久的,前面只需要2天左右就可以完成,这部分花了我一个多星期。
首先在videollama2-main文件夹中找到scripts\custom文件夹,这里面为训练的脚本文件,我选择的是finetune.sh脚本,将里面的内容进行修改
文件中的
--node_rank $RANK \
/root/private_data/videollama2/VideoLLaMA2-main/videollama2/train.py \
--model_path /root/private_data/videollama2/videollama2-7B \
--vision_tower /root/private_data/videollama2/clip-vit-large-patch14 \
--data_path ${DATA_DIR}/custom_sft/custom.json \
--data_folder ${DATA_DIR}/custom_sft/ \
部分改成对应模型实际路径,我都用的绝对路径。
--pretrain_mm_mlp_adapter部分用到了一个.bin文件,需要到对应的base模型下载对应的.bin文件,我的是videollama2-7B,我需要进入到videollama2-7B-base中下载mm_projector1.bin文件,放入自己的文件夹中,填入对应的路径。
我的是--pretrain_mm_mlp_adapter /root/private_data/videollama2/videollama2-7B/mm_projector1.bin \此外,在运行时,会出现找不到模型文件的import报错,是因为训练部分的python文件导入层级错误的问题,需要结合实际进行更改。更改完这些之后,就是运行脚本进行训练,我用了两张A800来进行训练的,需要进行分布式训练,我是单机多卡进行训练,需要对应修改脚本中的内容
ARG_WORLD_SIZE=1 # 机器数量,单机用1
ARG_NPROC_PER_NODE=2 # 使用GPU数量训练参数部分根据实际情况进行更改,这是我的修改
# 训练参数
GLOBAL_BATCH_SIZE=8
LOCAL_BATCH_SIZE=4 更改完成这些之后,正常的话运行脚本会出现训练进度,如图
训练完成之后会出现一个新的文件夹,部分内容如下
然后按照部署的步骤来即可。
---------------------------------------------------------------------------------------------------
训练过程中还出现了许多其他的错误 ,由于记录时间比较久远找不到之前报错的内容了,没有写在文章里了。后续有机会再补充。
文章参考:
VideoLLaMA2部署 && huggingface命令的使用_video llama 2-优快云博客

















 1259
1259



 到【灌水乐园】发言
到【灌水乐园】发言








