







【机器学习26】-偏差、方差权衡
以下是关于偏差-方差权衡、神经网络优化及正则化应用的系统性解析与解题思路:
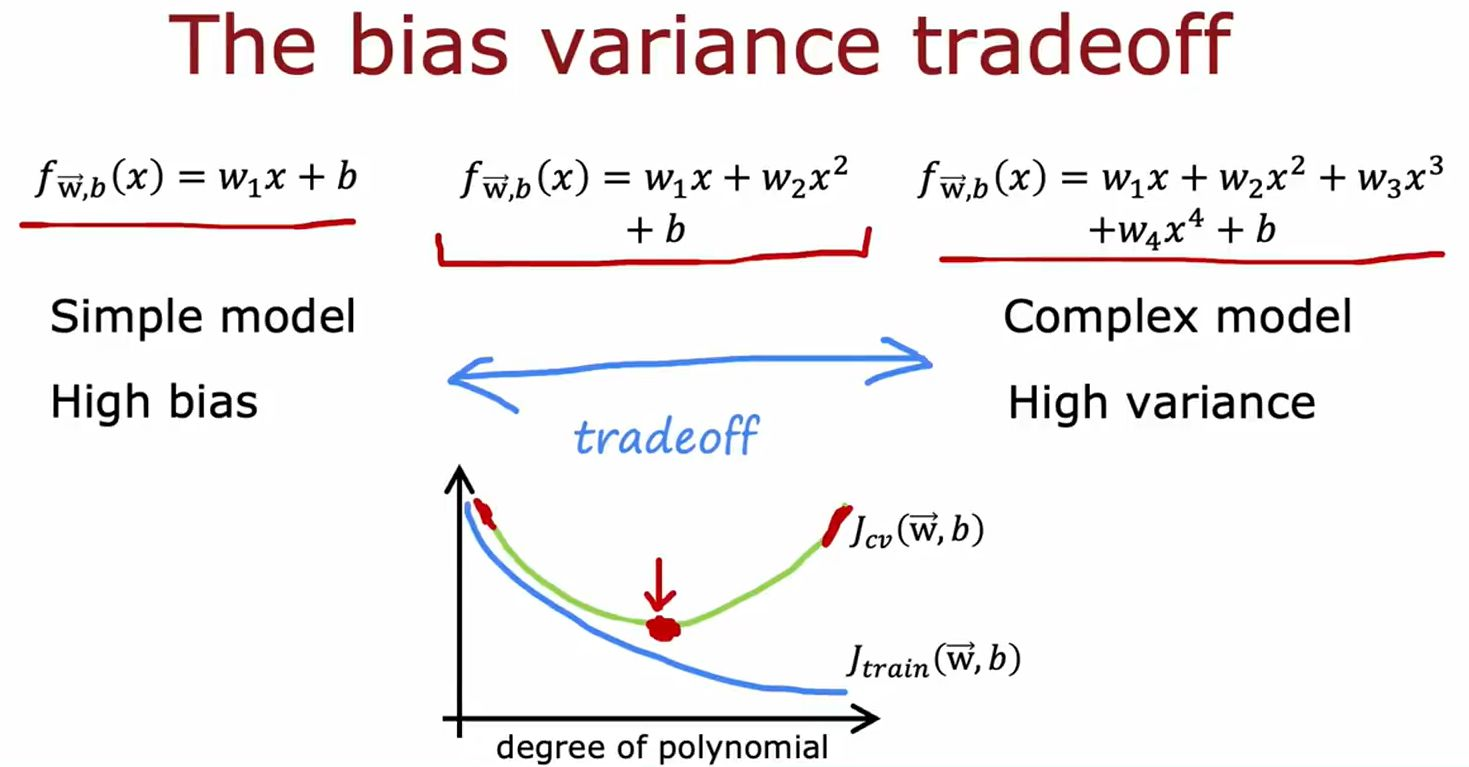
1. 偏差-方差权衡(图1)
核心概念
• 简单模型(如线性回归):
f
w
,
b
(
x
)
=
w
1
x
+
b
f_{\mathbf{w},b}(x) = w_1x + b
fw,b(x)=w1x+b
• 高偏差:训练误差
J
t
r
a
i
n
J_{train}
Jtrain和验证误差
J
c
v
J_{cv}
Jcv均高(欠拟合)。
• 复杂模型(如高阶多项式):
f
w
,
b
(
x
)
=
∑
k
=
1
4
w
k
x
k
+
b
f_{\mathbf{w},b}(x) = \sum_{k=1}^4 w_kx^k + b
fw,b(x)=k=1∑4wkxk+b
• 高方差:
J
t
r
a
i
n
J_{train}
Jtrain低但
J
c
v
J_{cv}
Jcv显著升高(过拟合)。
诊断与解决
- 观察误差曲线:
• 若 J t r a i n J_{train} Jtrain和 J c v J_{cv} Jcv均高 → 增加模型复杂度(如升高多项式次数)。
• 若 J t r a i n J_{train} Jtrain低但 J c v J_{cv} Jcv高 → 简化模型或正则化(如降低次数、增大 λ \lambda λ)。 - 最优复杂度选择:
• 选择 J c v J_{cv} Jcv最低对应的多项式阶数(图1中 d = 2 d=2 d=2附近)。
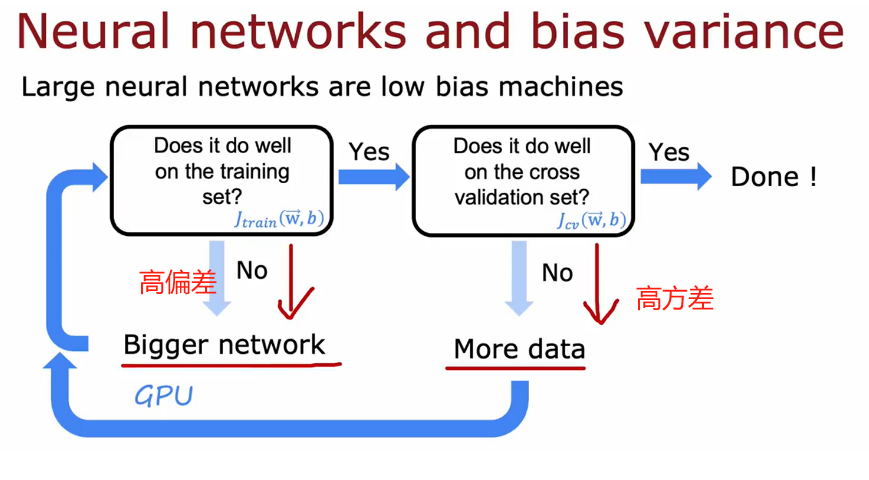
2. 神经网络优化流程(图2)
调试步骤
- 检查训练集表现:
• 若 J t r a i n J_{train} Jtrain高 即高方差→ 增大网络规模(增加层数或单元数)。
◦ 原理:神经网络是低偏差模型,容量不足会导致欠拟合。
• 若 J t r a i n J_{train} Jtrain低 → 进入下一步。 - 检查验证集表现:
• 若 J c v J_{cv} Jcv高 即高方差→ 收集更多数据或添加正则化。
◦ 原理:数据不足或模型过复杂时需抑制过拟合。
关键结论
• 大型神经网络优先解决偏差,再通过数据/正则化控制方差。
• 硬件支持(如GPU)对大规模网络训练至关重要。
3. 正则化在神经网络中的应用(图3)
正则化模型 vs 非正则化模型
| 组件 | 非正则化模型 | 正则化模型(L2, λ = 0.01 \lambda=0.01 λ=0.01) |
|---|---|---|
| 层结构 | Dense(25, ReLU) → Dense(15, ReLU) → Sigmoid | 每层添加kernel_regularizer=l2(0.01) |
| 损失函数 | 交叉熵 | 交叉熵 + λ 2 m ∑ ∣ w ∣ 2 2 \frac{\lambda}{2m}\sum|\mathbf{w}|_2^2 2mλ∑∣w∣22 |
| 效果 | 易过拟合 | 抑制权重过大,提升泛化能力 |
实现代码示例
from tensorflow.keras import Sequential, Dense
from tensorflow.keras.regularizers import l2
# 正则化模型
model = Sequential([
Dense(25, activation='relu', kernel_regularizer=l2(0.01)),
Dense(15, activation='relu', kernel_regularizer=l2(0.01)),
Dense(1, activation='sigmoid', kernel_regularizer=l2(0.01))
])
4. 综合解题思路
问题类型判断与解决策略
| 问题类型 | 判断依据 | 解决方案 |
|---|---|---|
| 高偏差 | J t r a i n J_{train} Jtrain和 J c v J_{cv} Jcv均高 | 增加模型复杂度/特征/减小 λ \lambda λ |
| 高方差 | J t r a i n ≪ J c v J_{train}\ll J_{cv} Jtrain≪Jcv | 增大 λ \lambda λ/正则化/简化模型/增加数据 |
| 最优平衡 | J c v J_{cv} Jcv最小且与 J t r a i n J_{train} Jtrain差距合理 | 保持当前模型 |
操作流程
- 训练基础模型 → 计算 J t r a i n J_{train} Jtrain和 J c v J_{cv} Jcv。
- 诊断问题:
• 神经网络优先扩规模解决偏差,再用正则化/数据解决方差。
• 传统模型通过调整复杂度或 λ \lambda λ平衡偏差-方差。 - 验证改进:监控 J c v J_{cv} Jcv下降且泛化性提升。
5. 核心公式总结
- 正则化损失函数:
J ( w , b ) = 1 m ∑ i = 1 m L ( f ( x ( i ) ) , y ( i ) ) + λ 2 m ∥ w ∥ 2 2 J(\mathbf{w},b) = \frac{1}{m}\sum_{i=1}^m \mathcal{L}(f(\mathbf{x}^{(i)}),y^{(i)}) + \frac{\lambda}{2m}\|\mathbf{w}\|_2^2 J(w,b)=m1i=1∑mL(f(x(i)),y(i))+2mλ∥w∥22 - 偏差-方差决策:
• 高偏差: ↑ \uparrow ↑复杂度, ↓ λ \downarrow\lambda ↓λ
• 高方差: ↓ \downarrow ↓复杂度, ↑ λ \uparrow\lambda ↑λ或 ↑ \uparrow ↑数据量
通过系统化应用上述方法,可高效优化模型性能并解决过拟合/欠拟合问题。


















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









