







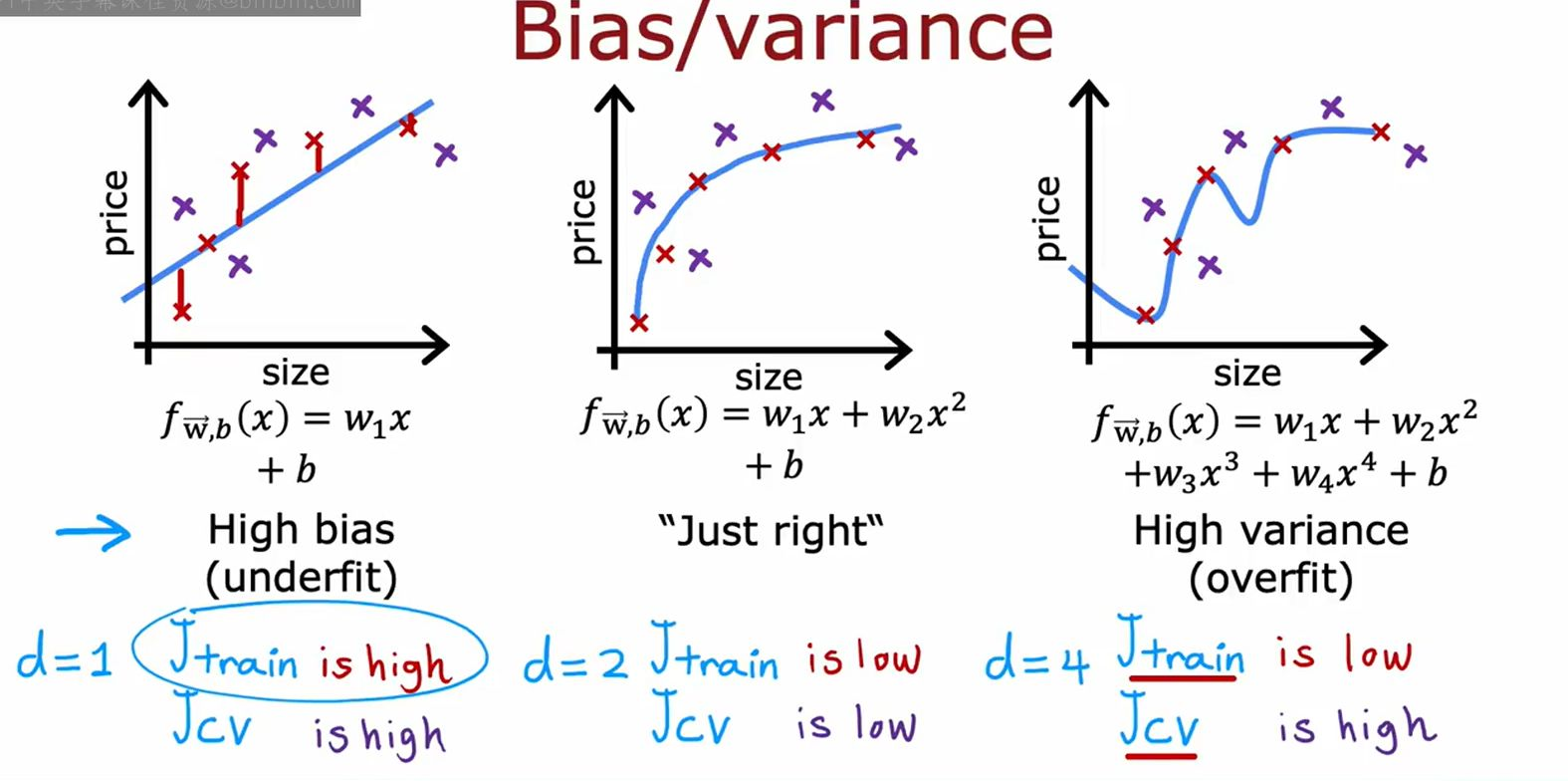
【机器学习25】-诊断偏差和方差
当你运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。那么这两种情况,哪个和偏差有关,哪个和方差有关,或者是不是和两个都有关?搞清楚这一点非常重要,因为能判断出现的情况是这两种情况中的哪一种。其实是一个很有效的指示器,指引着可以改进算法的最有效的方法和途径。在这段视频中,我想更深入地探讨一下有关偏差和方差的问题,希望你能对它们有一个更深入的理解,并且也能弄清楚怎样评价一个学习算法,能够判断一个算法是偏差还是方差有问题,因为这个问题对于弄清如何改进学习算法的效果非常重要,高偏差和高方差的问题基本上来说是欠拟合和过拟合的问题。
以下是关于**偏差(Bias)和方差(Variance)**的诊断与分析的格式化输出:
1. 核心概念
• 偏差(Bias):模型对真实关系的错误假设,导致欠拟合(
u
n
d
e
r
f
i
t
underfit
underfit)。
• 表现:模型过于简单,无法捕捉数据规律。
• 方差(Variance):模型对训练数据过度敏感,导致过拟合(
o
v
e
r
f
i
t
overfit
overfit)。
• 表现:模型过于复杂,拟合了噪声而非真实规律。
2. 诊断方法
通过比较**训练误差( J t r a i n J_{train} Jtrain)和交叉验证误差( J c v J_{cv} Jcv)**判断问题类型:
| 问题类型 | 训练误差( J t r a i n J_{train} Jtrain) | 交叉验证误差( J c v J_{cv} Jcv) | 关系 | 图示案例 |
|---|---|---|---|---|
| 高偏差( u n d e r f i t underfit underfit) | 高 | 高 | J t r a i n ≈ J c v J_{train} \approx J_{cv} Jtrain≈Jcv | 左图(线性模型) |
| 高方差( o v e r f i t overfit overfit) | 低 | 显著高于训练误差 | J c v ≫ J t r a i n J_{cv} \gg J_{train} Jcv≫Jtrain | 右图(高阶多项式) |
| 两者兼具 | 高 | 更高 | J c v > J t r a i n J_{cv} > J_{train} Jcv>Jtrain | 中间过渡区域 |
关键步骤:
- 计算训练误差和交叉验证误差。
- 根据误差大小和差距判断问题类型(参考上表)。
3. 解决方案
(1)高偏差( u n d e r f i t underfit underfit)
• 表现:
• 模型:
f
(
x
)
=
w
1
x
+
b
f(x) = w_1x + b
f(x)=w1x+b(线性)。
• 误差:
J
t
r
a
i
n
J_{train}
Jtrain 和
J
c
v
J_{cv}
Jcv 均高且接近。
• 改进方法:
• 增加模型复杂度(如更高次多项式、更多神经网络层)。
• 添加更多特征。
• 减少正则化参数
λ
\lambda
λ。
(2)高方差( o v e r f i t overfit overfit)
• 表现:
• 模型:
f
(
x
)
=
w
1
x
+
w
2
x
2
+
w
3
x
3
+
w
4
x
4
+
b
f(x) = w_1x + w_2x^2 + w_3x^3 + w_4x^4 + b
f(x)=w1x+w2x2+w3x3+w4x4+b。
• 误差:
J
t
r
a
i
n
J_{train}
Jtrain 低,
J
c
v
J_{cv}
Jcv 显著升高。
• 改进方法:
• 简化模型(如降低多项式次数、减少神经网络单元数)。
• 增加训练数据量。
• 增强正则化(增大
λ
\lambda
λ)。
(3)高偏差和高方差并存
• 表现:
• 模型复杂度介于简单和复杂之间。
• 误差:
J
t
r
a
i
n
J_{train}
Jtrain 高,
J
c
v
J_{cv}
Jcv 更高。
• 改进方法:
• 调整模型复杂度至“刚刚好”(如二次多项式)。
• 优化特征工程(如删除无关特征或添加有用特征)。
4. 实例分析
• “刚刚好”模型:
• 模型:
f
(
x
)
=
w
1
x
+
w
2
x
2
+
b
f(x) = w_1x + w_2x^2 + b
f(x)=w1x+w2x2+b(二次多项式)。
• 误差:
J
t
r
a
i
n
J_{train}
Jtrain 和
J
c
v
J_{cv}
Jcv 均低,平衡了偏差和方差。
• 选择依据:
• 交叉验证误差最小的模型(图中最低点对应的多项式次数)。
5. 总结:诊断与改进流程
- 训练模型 → 计算 J t r a i n J_{train} Jtrain 和 J c v J_{cv} Jcv。
- 诊断问题:
• 高偏差 → 增加复杂度。
• 高方差 → 简化模型或正则化。 - 验证改进:重新评估交叉验证误差。
口诀:
• “高偏差?加特征、减正则!”
• “高方差?减参数、增数据!”
通过系统性地应用上述方法,可有效诊断和解决偏差与方差问题,提升模型性能。


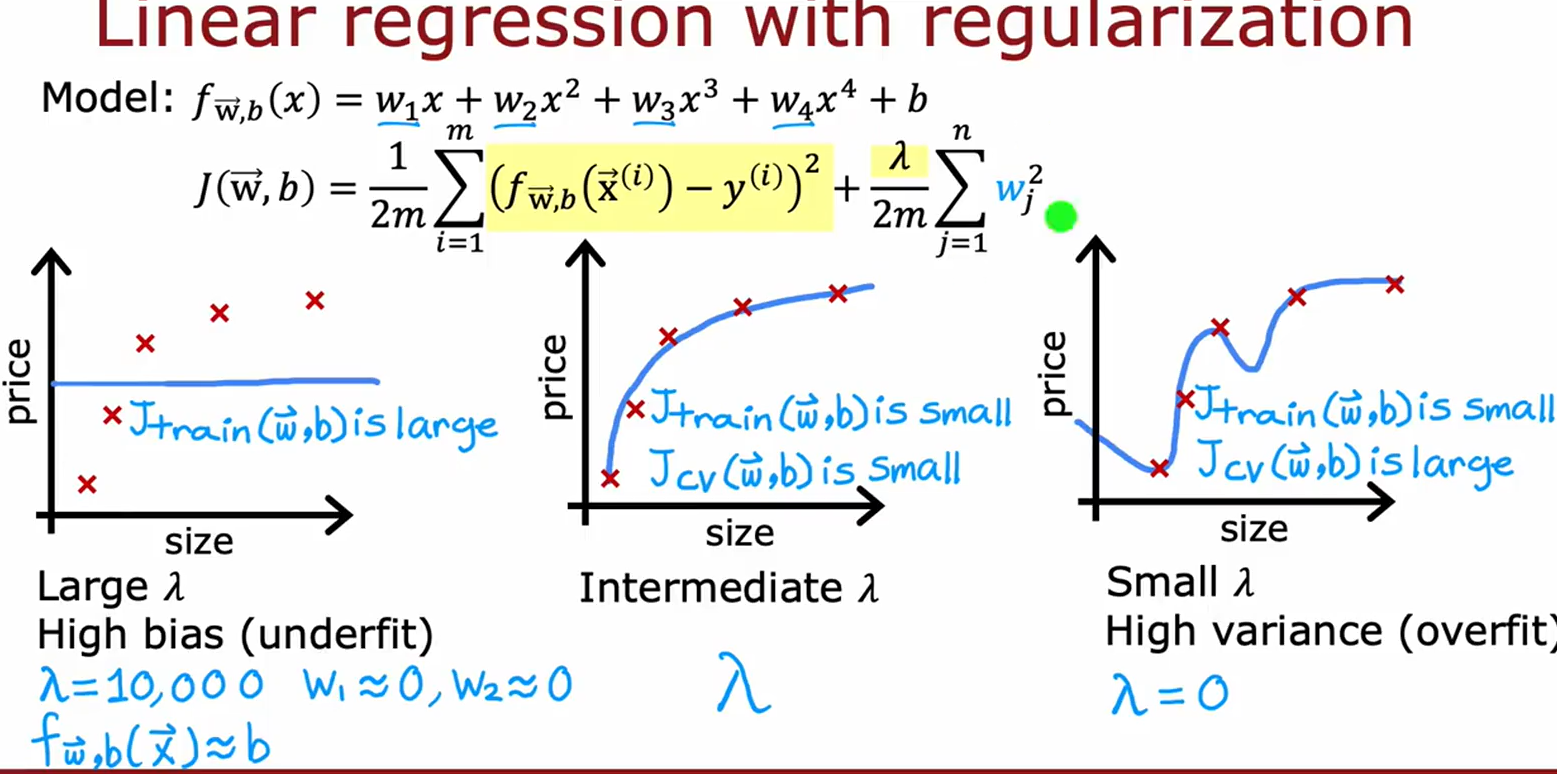
根据四张图片的核心内容,以下是关于偏差-方差权衡与正则化参数选择的系统性解析:
1. 核心概念(图1)
• 偏差(Bias):模型简化导致的欠拟合(
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv均高)。
• 方差(Variance):模型复杂导致的过拟合(
J
t
r
a
i
n
≪
J
c
v
J_{train}\ll J_{cv}
Jtrain≪Jcv)。
• 正则化作用:通过调整
λ
\lambda
λ平衡两者,公式:
J
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∑
j
=
1
n
w
j
2
J(\mathbf{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\mathbf{w},b}(\mathbf{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum_{j=1}^n w_j^2
J(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2+2mλj=1∑nwj2
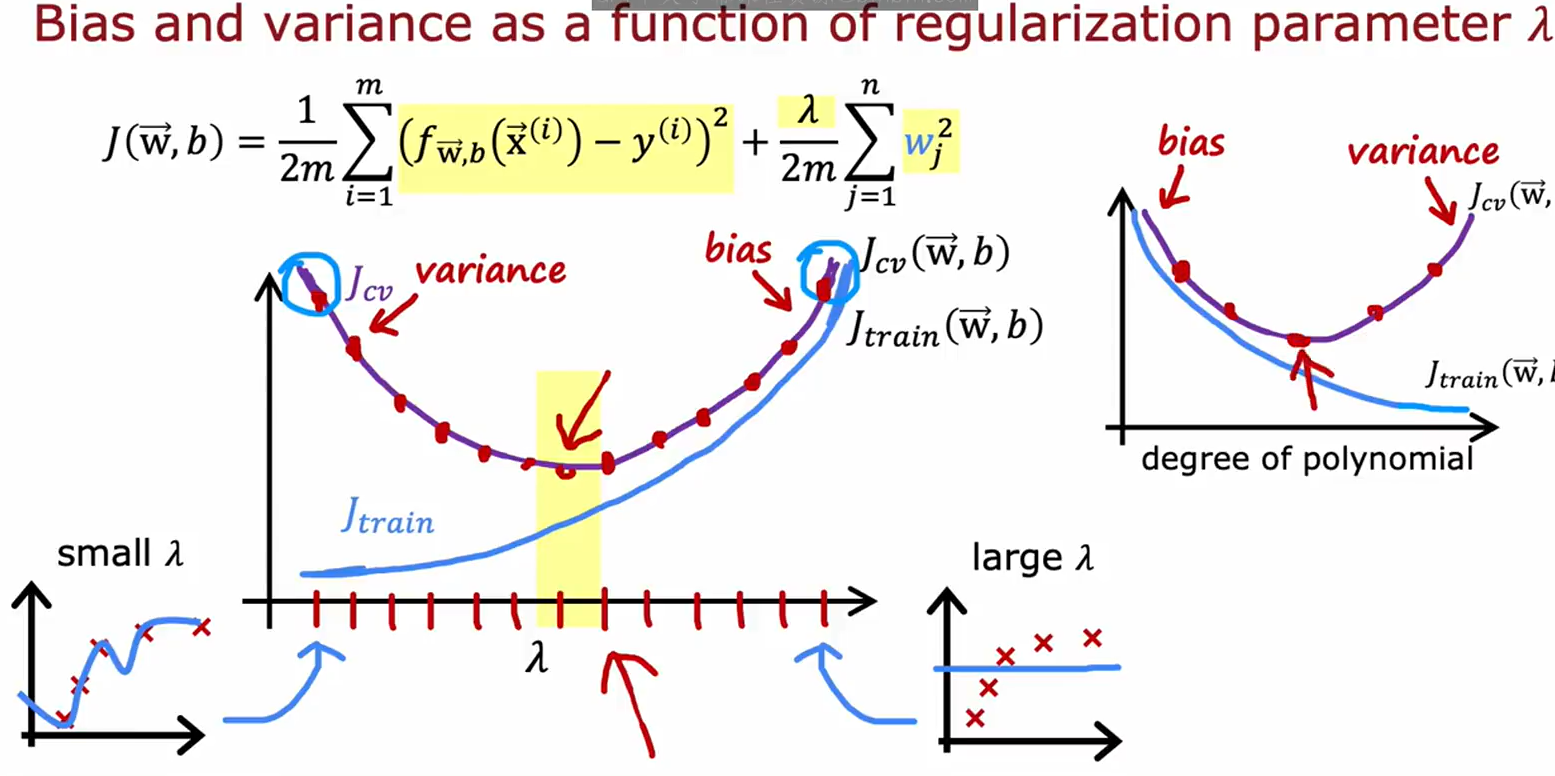
2. 正则化参数 λ \lambda λ的影响(图2 & 图4)
| λ \lambda λ取值 | 模型表现 | 误差特点 | 图示位置 |
|---|---|---|---|
| λ \lambda λ极大( 1 0 4 10^4 104) | 高偏差(欠拟合) | f w , b ( x ) ≈ b f_{\mathbf{w},b}(x)\approx b fw,b(x)≈b | 图2左图 |
| λ \lambda λ适中 | 最优平衡 | J t r a i n J_{train} Jtrain和 J c v J_{cv} Jcv均小 | 图2中图/图4最低点 |
| λ = 0 \lambda=0 λ=0 | 高方差(过拟合) | J t r a i n J_{train} Jtrain极低, J c v J_{cv} Jcv飙升 | 图2右图 |
关键结论:
• 图4显示
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv随
λ
\lambda
λ的变化曲线,最优
λ
\lambda
λ位于两条曲线间隙最小处。
3. 正则化参数选择流程(图3)
步骤:
- 尝试 λ \lambda λ候选值(如 0 , 0.01 , 0.02 , . . . , 10 0,0.01,0.02,...,10 0,0.01,0.02,...,10)。
- 计算交叉验证误差 J c v ( w < i > , b < i > ) J_{cv}(\mathbf{w}^{<i>},b^{<i>}) Jcv(w<i>,b<i>)。
- 选择最优 λ \lambda λ:对应最小 J c v J_{cv} Jcv的组合(图中选择 λ = 0.08 \lambda=0.08 λ=0.08)。
- 最终评估:用测试集计算 J t e s t ( w < 5 > , b < 5 > ) J_{test}(\mathbf{w}^{<5>},b^{<5>}) Jtest(w<5>,b<5>)。
数学表达:
min
λ
J
c
v
(
w
,
b
)
s.t.
w
,
b
=
arg
min
J
(
w
,
b
)
\min_\lambda J_{cv}(\mathbf{w},b) \quad \text{s.t.} \quad \mathbf{w},b=\arg\min J(\mathbf{w},b)
λminJcv(w,b)s.t.w,b=argminJ(w,b)
4. 诊断与改进策略
(1)高偏差问题
• 表现:
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv接近且高(图2左)。
• 解决:
• 增加多项式次数(图3模型
f
(
x
)
=
∑
k
=
1
4
w
k
x
k
+
b
f(x)=\sum_{k=1}^4 w_kx^k+b
f(x)=∑k=14wkxk+b)。
• 减小
λ
\lambda
λ(放松正则化约束)。
(2)高方差问题
• 表现:
J
t
r
a
i
n
≈
0
J_{train}\approx0
Jtrain≈0但
J
c
v
≫
J
t
r
a
i
n
J_{cv}\gg J_{train}
Jcv≫Jtrain(图2右)。
• 解决:
• 增大
λ
\lambda
λ(增强正则化,压缩权重)。
• 减少特征或使用更简单模型。
(3)最优平衡点
• 判定标准: J c v J_{cv} Jcv最小且 ∣ J t r a i n − J c v ∣ |J_{train}-J_{cv}| ∣Jtrain−Jcv∣适中(图4中间区域)。
5. 实例演示(图3)
• 模型:四次多项式回归
f
(
x
)
=
∑
k
=
1
4
w
k
x
k
+
b
f(x)=\sum_{k=1}^4 w_kx^k+b
f(x)=∑k=14wkxk+b。
• 选择过程:
• 尝试
λ
=
0.08
\lambda=0.08
λ=0.08时
J
c
v
J_{cv}
Jcv最小,故选定
w
<
5
>
,
b
<
5
>
\mathbf{w}^{<5>},b^{<5>}
w<5>,b<5>。
• 最终报告
J
t
e
s
t
(
w
<
5
>
,
b
<
5
>
)
J_{test}(\mathbf{w}^{<5>},b^{<5>})
Jtest(w<5>,b<5>)。
6. 总结:操作指南
- 划分数据集:训练集(拟合)、验证集(调 λ \lambda λ)、测试集(最终评估)。
- 迭代尝试:
• 遍历 λ \lambda λ候选值,训练模型并计算 J c v J_{cv} Jcv。 - 选择与验证:
• 选择最小 J c v J_{cv} Jcv对应的 λ \lambda λ,用测试集确认泛化性。
公式总结:
• 正则化损失函数:
J
(
w
,
b
)
=
1
2
m
∑
i
=
1
m
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∥
w
∥
2
2
J(\mathbf{w},b)=\frac{1}{2m}\sum_{i=1}^m(f_{\mathbf{w},b}(\mathbf{x}^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\|\mathbf{w}\|_2^2
J(w,b)=2m1i=1∑m(fw,b(x(i))−y(i))2+2mλ∥w∥22
• 最优
λ
\lambda
λ:
λ
∗
=
arg
min
λ
J
c
v
(
w
,
b
)
\lambda^*=\arg\min_\lambda J_{cv}(\mathbf{w},b)
λ∗=argλminJcv(w,b)
通过系统化应用上述方法,可有效解决偏差-方差问题并优化模型性能。


以下是关于正则化线性回归模型调试方法的详细解答与解题思路:
1. 问题诊断(图片核心公式)
模型使用正则化线性回归,但预测误差较大,其损失函数为:
J
(
w
)
=
1
2
m
∑
i
=
1
m
(
f
w
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∑
j
=
1
n
w
j
2
J(\mathbf{w}) = \frac{1}{2m} \sum_{i=1}^m (f_{\mathbf{w}}(\mathbf{x}^{(i)}) - y^{(i)})^2 + \frac{\lambda}{2m} \sum_{j=1}^n w_j^2
J(w)=2m1i=1∑m(fw(x(i))−y(i))2+2mλj=1∑nwj2
关键问题:需判断误差源于高偏差(欠拟合)还是高方差(过拟合)。
2. 调试方法及适用场景(图片标注)
(1)解决高方差(过拟合)的方法
| 方法 | 作用原理 | 数学依据 |
|---|---|---|
| 获取更多训练样本 | 减少模型对噪声的敏感性 | 降低 J c v J_{cv} Jcv与 J t r a i n J_{train} Jtrain的差距 |
| 尝试更小的特征集 | 减少冗余特征,降低复杂度 | 减小 ∑ j = 1 n w j 2 \sum_{j=1}^n w_j^2 ∑j=1nwj2项影响 |
| 增大正则化参数 λ \lambda λ | 强化权重惩罚,抑制过拟合 | 增大 λ 2 m ∣ w ∣ 2 2 \frac{\lambda}{2m}|\mathbf{w}|_2^2 2mλ∣w∣22 |
(2)解决高偏差(欠拟合)的方法
| 方法 | 作用原理 | 数学依据 |
|---|---|---|
| 获取额外特征 | 增强模型捕捉规律的能力 | 增加特征维度 n n n |
| 添加多项式特征 | 引入非线性关系(如 x 2 , x 3 x^2, x^3 x2,x3) | 扩展模型为 f ( x ) = w T ϕ ( x ) + b f(\mathbf{x}) = \mathbf{w}^T \phi(\mathbf{x}) + b f(x)=wTϕ(x)+b |
| 减小正则化参数 λ \lambda λ | 放松权重约束,提升模型灵活性 | 减小正则化项权重 |
3. 解题流程与选择策略
步骤1:判断问题类型
• 高方差表现:
•
J
t
r
a
i
n
J_{train}
Jtrain低但
J
c
v
J_{cv}
Jcv显著高(
J
c
v
≫
J
t
r
a
i
n
J_{cv} \gg J_{train}
Jcv≫Jtrain)。
• 图片提示:红色标注"Try smaller sets of features"或"increasing
λ
\lambda
λ"。
• 高偏差表现:
•
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv均高且接近。
• 图片提示:红色标注"Try adding polynomial features"或"decreasing
λ
\lambda
λ"。
步骤2:选择对应调试方法
• 若高方差:优先尝试获取更多数据或增大
λ
\lambda
λ(图片中红色箭头强调)。
• 若高偏差:优先尝试添加多项式特征或减小
λ
\lambda
λ(图片中红色标注)。
步骤3:验证效果
• 重新计算
J
t
r
a
i
n
J_{train}
Jtrain和
J
c
v
J_{cv}
Jcv,观察误差变化:
• 成功标准:
J
c
v
J_{cv}
Jcv下降且与
J
t
r
a
i
n
J_{train}
Jtrain差距缩小。
4. 实例演示(图片中案例)
• 场景:房价预测模型误差大。
• 调试过程:
- 发现 J c v ≫ J t r a i n J_{cv} \gg J_{train} Jcv≫Jtrain → 判断为高方差。
- 选择方法:
◦ 增大 λ \lambda λ(从0.01调整到0.1),重新训练模型。
◦ 或减少特征(如删除冗余特征 x 3 , x 5 x_3, x_5 x3,x5)。 - 验证:调整后 J c v J_{cv} Jcv降低至合理范围。
5. 总结:关键公式与口诀
• 正则化损失函数:
J
(
w
)
=
MSE
+
λ
2
m
∥
w
∥
2
2
J(\mathbf{w}) = \text{MSE} + \frac{\lambda}{2m}\|\mathbf{w}\|_2^2
J(w)=MSE+2mλ∥w∥22
• 调试口诀:
• “方差大?加数据、减特征、调大
λ
\lambda
λ!”
• “偏差高?加特征、升次数、调小
λ
\lambda
λ!”
通过系统化应用图片中的调试策略,可快速定位并解决模型性能问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









