



1.背景-现RAG存在的问题
现在很明显,仅仅依靠向量检索技术不足以开发 RAG 应用程序,尤其是在生产环境中部署。
以下为案例:
- 关键词搜索容易返回不回答问题的结果
- 稠密检索容易返回不正确的结果
实际RAG检索中也有很多类型问题,关键词或者稠密检索知识基于向量相似度,完全没有考虑逻辑语义。导致检索失败,有时适得其反。
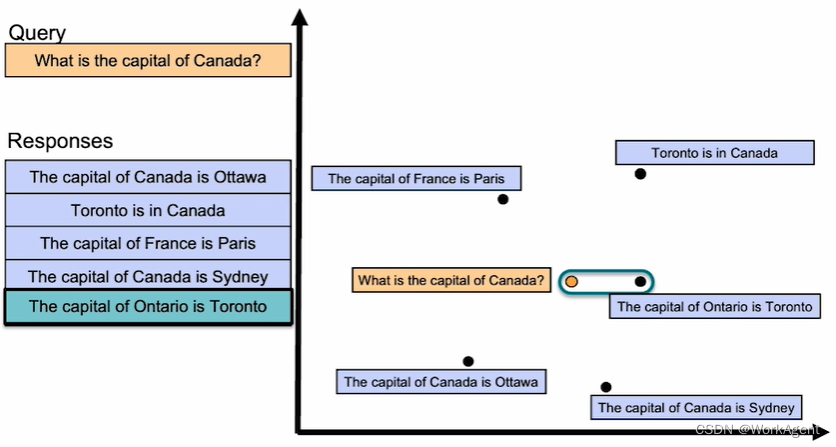
2.ReRank的原理
ReRank 在许多 QA 对上进行了训练
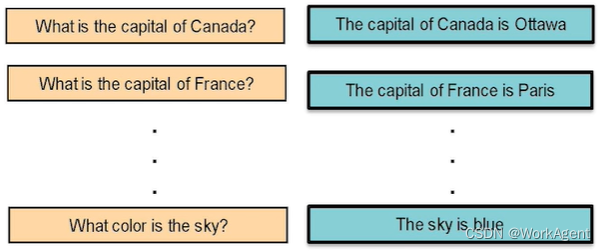
- ReRank Model是通过监督学习训练好的预训练模型
- 给定大量正确的查询-文件对(QA pairs),让模型学习给出高分数
- 同时给定大量不正确的查询-文件对,让模型学习给出低分数
- 通过最大化正确对的分数和最小化不正确对的分数来训练
- 经过训练后,ReRank 就能区分查询和文件之间的关联性
- 从而按照相关性对检索结果进行排序
直接看ReRank的原理图
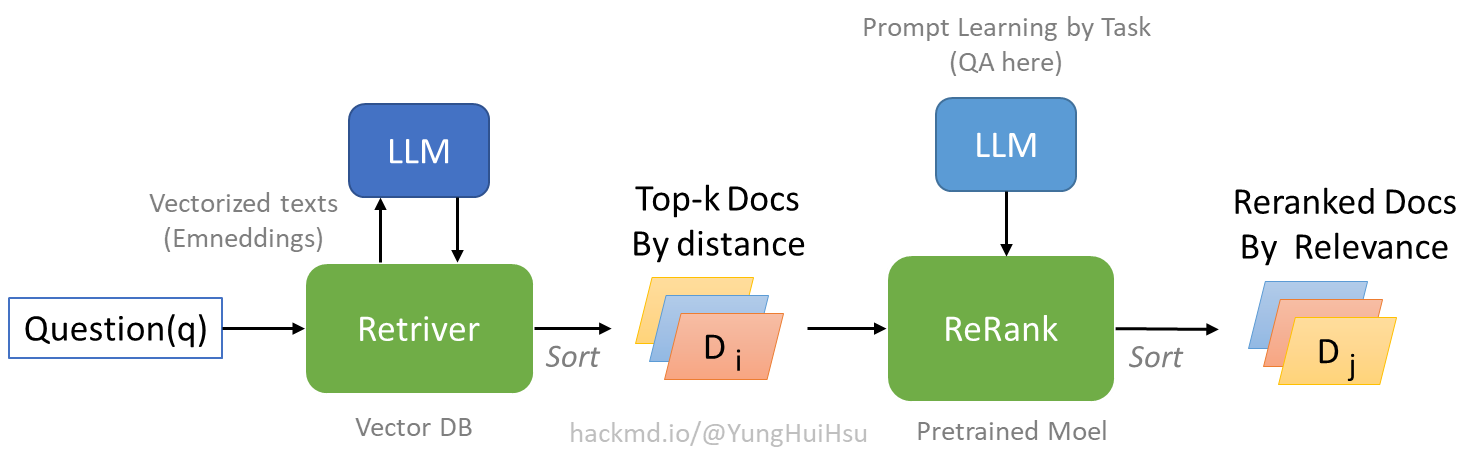
- ReRank 可以给查询和回答一个相关性分数,从而排序结果
- ReRank 可以用来改进关键词检索和稠密检索,找到正确答案
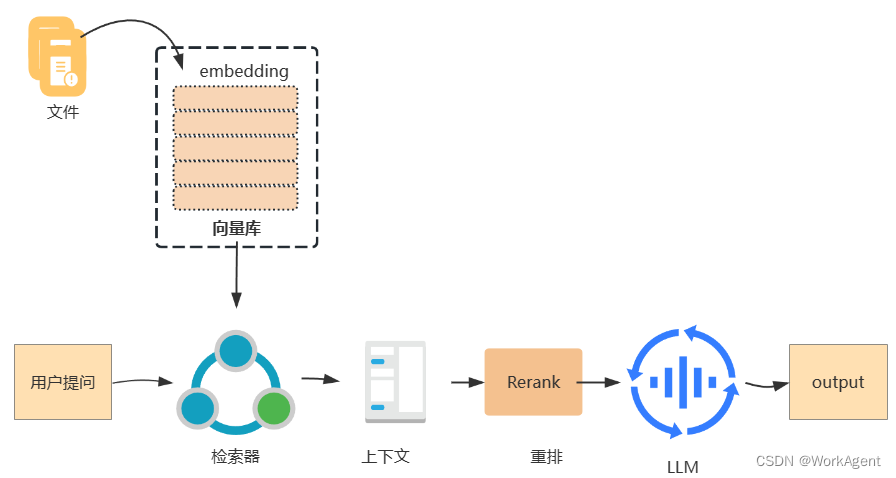
rerank 模型通过根据候选文档与用户查询的语义一致性对候选文档进行重新排序来增强语义排序结果。 其核心原则包括计算用户问题与每个文档之间的相关性分数,然后返回按相关性排序的文档列表,从高到低。流行的rerank模型包括 Cohere rerank、bge-reranker 等。
通常,在rerank之前进行初步搜索,因为计算查询与数百万个文档之间的相关性分数效率非常低。因此,rerank通常位于搜索过程的末尾,使其成为合并和排序来自各种搜索系统的结果的理想选择。
然而,重新排名不仅限于组合来自不同搜索系统的结果。这在单一搜索模式下也很有用。引入重新排名步骤,例如语义重新排名后关键字搜索,可以显着提高文档召回率。
在实际应用中,除了规范化多个查询结果之外,传递给大型模型的文本段数量通常在提供它们之前受到限制(即 TopK,可在重新排名模型参数中调整)。此限制是由于大型模型的输入窗口大小,通常范围为 4K 到 128K token。因此,有必要选择与模型的输入窗口大小约束相一致的合适分割策略和 TopK 值。
重要的是,即使模型的上下文窗口足够大,过多的chunk片段也会带来不太相关的内容影响prompt结构内容,从而降低答案的质量。因此,重新排名中较大的 TopK 参数并不是越大越好。prompt中放入越多的无关知识,会干扰大模型的生成能力。
重新排序不应被视为搜索技术的替代品,而应被视为增强现有搜索系统的补充工具。它的主要优势在于提供了一种简单、低复杂性的方法来优化搜索结果,从而能够将语义相关性集成到当前的搜索系统中,而无需进行重大的基础设施修改。
3.基于LLM或者Agent的ReRank
以下过程展示了Embedding检索后,将检索结果返回给大模型去做一次评估。类似CRAG或者Self-RAG,本质上都是利用了大模型的推理能力加强检索的准确性。由之前的完全由 向量检索相似度 转化为逻辑推理相似度。但是这种方案会降低RAG的效率,提升了准确度。
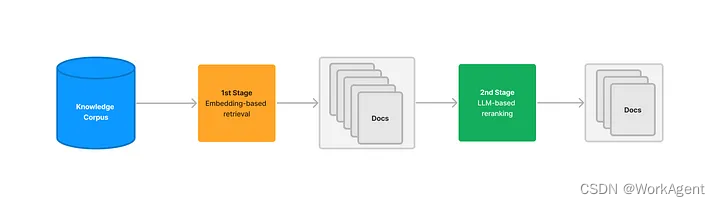
4.其它ReRank方案
4.1. 使用更精细的评分函数
RAG通常会在检索阶段根据输入问题或上下文生成一系列候选文档,然后利用这些文档的信息进行生成式回答。
reranking可以通过设计更精细的评分函数,对这些候选文档进行重新排序,优先选择与输入问题更相关、质量更高的文档作为生成回答的依据。
这可能涉及:
融合更多特征:除了原始的检索得分(如BM25分数),考虑加入其他特征,如文档长度、主题相关性、实体提及次数、段落位置等,以更全面地评估文档与问题的匹配程度。
引入深度学习模型:使用预训练的语言模型(如BERT、RoBERTa等)计算问题与文档的语义相似度,或者使用专门针对文档相关性设计的模型(如ANCE、DPR等)进行reranking。
考虑上下文敏感性:对于多轮对话或具有明确上下文的场景,评分函数应考虑上下文信息,确保所选文档不仅与当前问题相关,还与对话历史或上下文保持一致。
4.2. 集成外部知识
在reranking阶段,可以引入外部知识源(如百科、词典、专家规则等)来辅助判断文档的质量和相关性。例如:
利用领域专业知识:对于特定领域的应用,如医疗、法律、金融等,可以利用领域知识库或规则库来筛选出符合专业要求的文档。
利用常识知识:使用常识推理模型或知识图谱来判断文档内容是否符合常识,避免生成不符合事实的回答。
4.3. 采用多阶段reranking
将reranking过程分为多个阶段,逐步精细化文档排序:
粗排阶段:首先基于简单、高效的指标(如BM25得分)进行初步排序,筛选出一部分高潜力文档。
精排阶段:对粗排后的文档集使用更复杂的评分函数或模型进行二次排序,进一步提升相关文档的优先级。
微调阶段(可选):对于某些关键应用场景,可以加入人工规则或专家干预的微调阶段,确保最终选择的文档满足特定业务需求。
5.ReRank的意义
引入Rerank模型后的retrieval引擎能够去除上下文不相关的污染数据、提供更精准的上下文信息。重排后(Rerank)精准的上下文不仅可减少了token的使用量进而还可能提高LLM推理速度与准确率。

















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









