







本项目为前几天收费帮学妹做的一个项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。
一、项目介绍
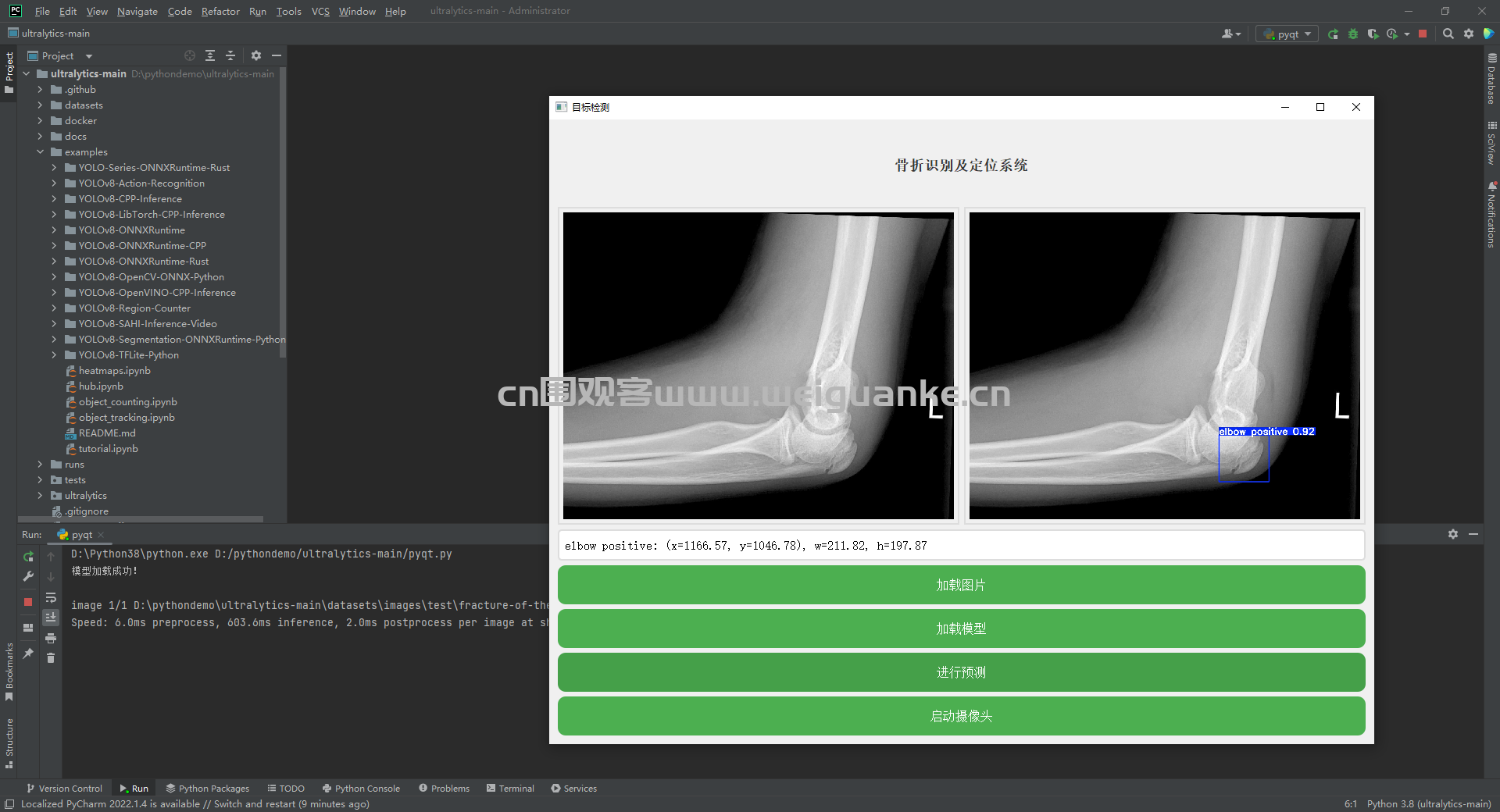
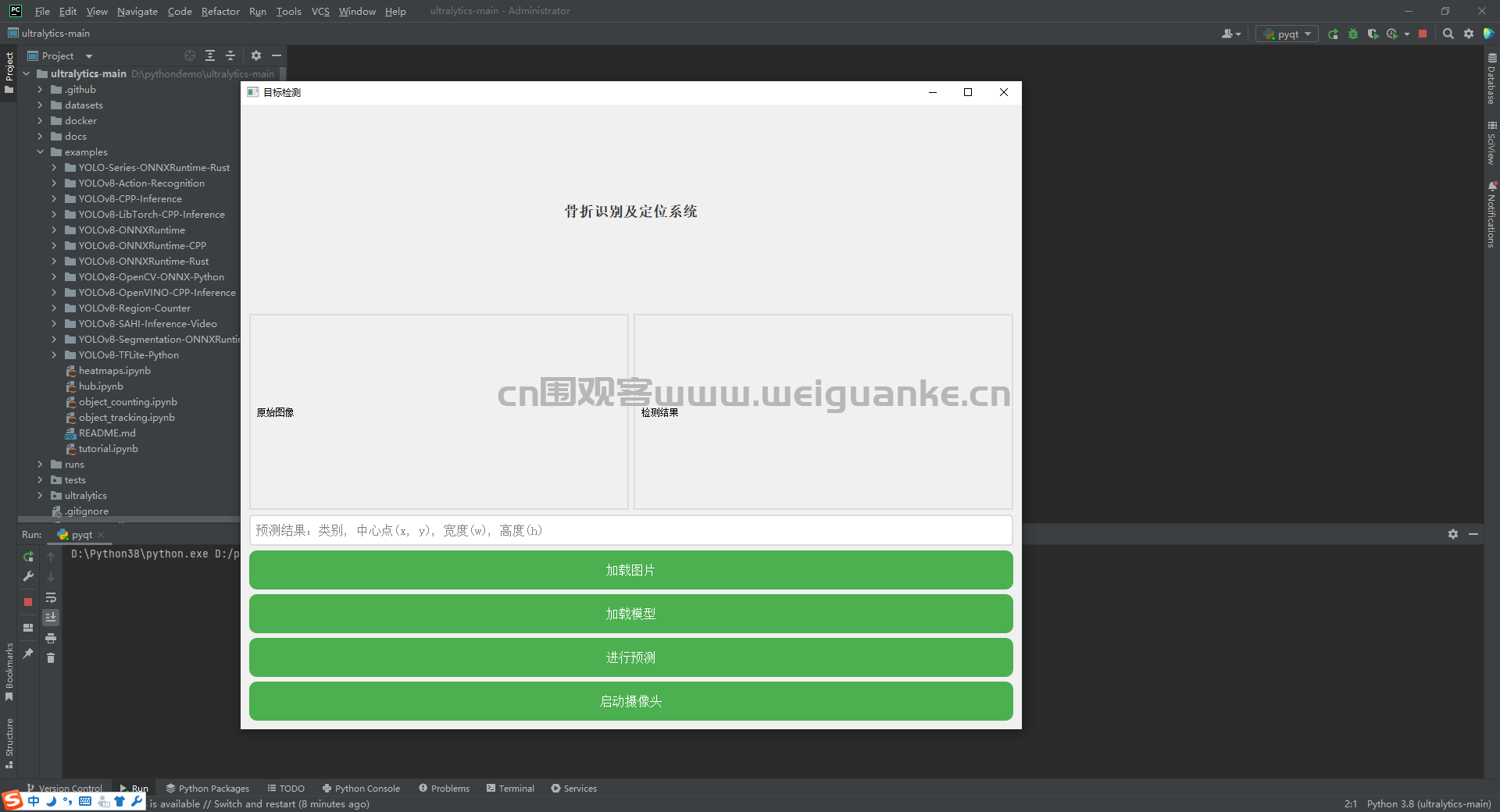
基于yolo8的骨折识别及定位系统
基于YOLOv8的骨折识别及定位系统是一款利用深度学习技术进行医学图像分析的应用。该系统能够自动检测和定位X光片中的骨折位置,提供精确的骨折区域坐标和置信度。通过图形用户界面,用户可以轻松上传图像、加载模型并获取检测结果,从而提高医疗诊断的效率和准确性。
二、主要功能
骨折检测:
系统能够自动识别X光片中的骨折位置。通过深度学习模型(YOLOv8)进行图像识别和分析。
骨折定位:
系统能够在检测到骨折后,精确定位骨折的位置。提供骨折区域的坐标(x, y)以及宽度(w)和高度(h)。
图像处理:
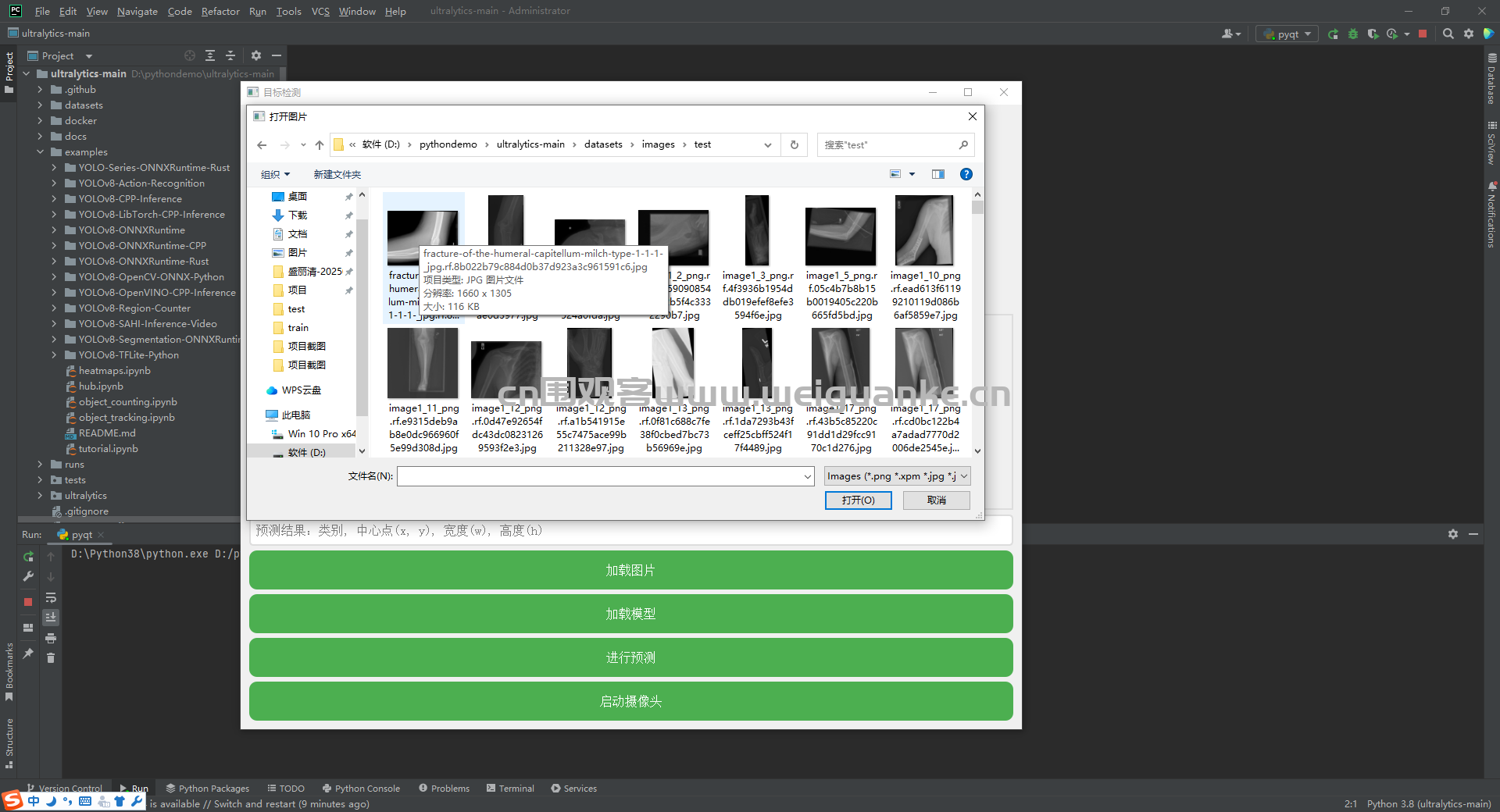
支持加载和处理多种格式的医学图像(如X光片)。提供图像预处理功能,以提高模型的检测精度。
模型加载与预测:
支持加载预训练的YOLOv8模型。能够进行实时预测,快速识别和定位骨折。
用户界面:
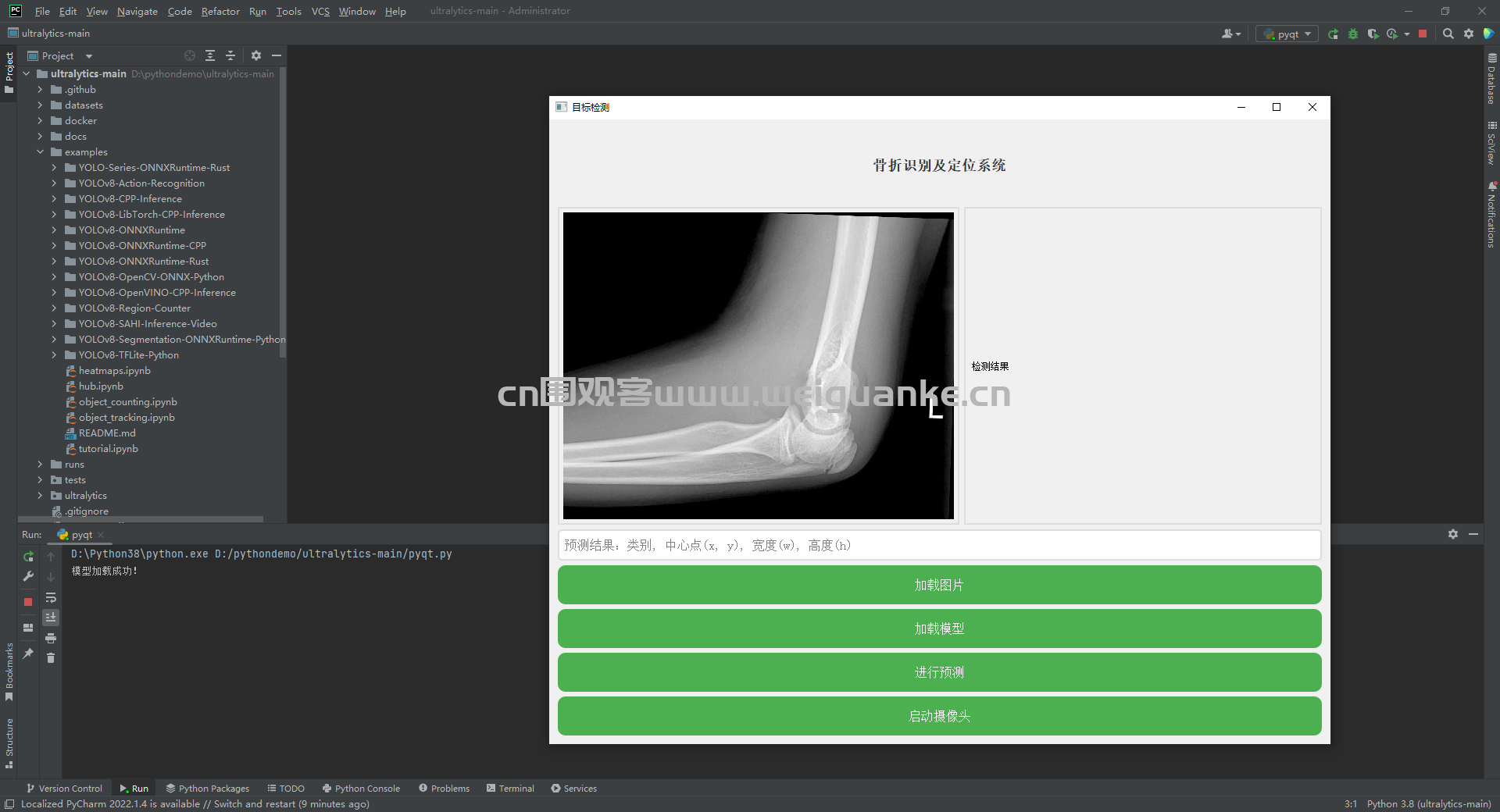
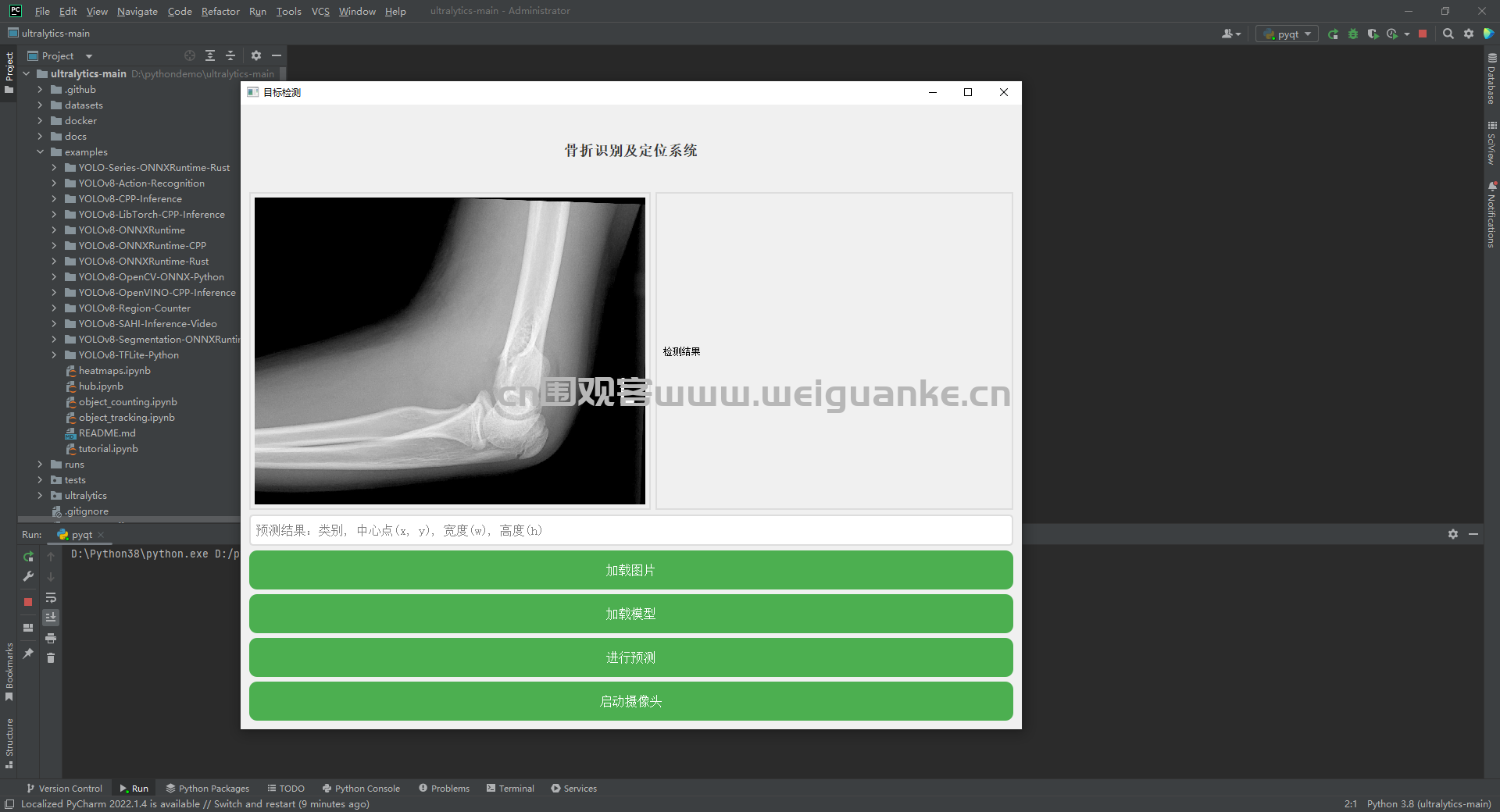
提供图形用户界面(GUI),方便用户操作。用户可以通过界面上传图像、加载模型、进行预测和查看结果。
结果展示:
在界面上展示检测结果,包括骨折区域的标注和置信度。提供详细的检测报告,包括骨折类型、位置和尺寸等信息。
摄像头集成:
支持启动摄像头进行实时图像捕捉和分析。适用于需要实时检测的场景。
数据集管理:
支持数据集的加载和管理,方便用户进行模型训练和测试。提供数据集的预处理和增强功能,提高模型的泛化能力。
三、项目运行
运行环境开发工具:PyCharm 2022.1.4
运行环境:python3.8(此配置为本人调试所用,仅供参考)
四、项目技术
服务端技术:yolo8
五、项目截图


















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











