







一、投影查询:
1、列名可以做别名查询,如:
select name as EmpName,age as EmpAge from employee;
2、表名也是可以取别名的,在查询中首次出现表名的地方后接as并设定别名,如:
select t.name as EmpName,t.age as EmpAge from employee as t;
以上,as也可以去掉,别名与原名使用空格隔开即可。
二、选择查询:
在关系表中选择满足给定条件的元组(从行的角度),更进一步说,选择查询通过一系列的方式筛选出我们实际需要的数据,常见的有四种筛选方式:条件字句、范围查询、模糊查询、子查询。
1、条件子句:
多条件连接词and、or。
关系型运算符优先级高到低为:NOT >AND >OR。如果where 后面有OR条件的话,则OR自动会把左右的查询条件分开。也就是说,在没有小括号()的干预下,总是先执行AND语句,再执行OR语句。例:select * from table where 条件1 AND 条件2 OR 条件3 等价于select * from table where ( 条件1 AND 条件2 ) OR 条件3;
select * from table where 条件1 AND 条件2 OR 条件3 AND 条件4 等价于 select * from table where ( 条件1 AND 条件2 ) OR ( 条件3 AND 条件4 )
2、范围查询:
2.1、运算符:>、<、>=、<=、=、!=、is null、is not null

2.2、in查询:
一般用于离散数据,关键字IN后面的括号中必须包含所有可能匹配的值。如果表示不在这个范围里的话,可以用关键字NOT IN来反转查询结果:

2.3、exists:
(1)exists和in的区别:in 是把外表和内表作hash join,而exists是对外表作loop,每次loop再对内表进行查询。如:
A:select * from t1 a where exists (select * from t2 b where b.id = a.id)
B:select * from t1 a where a.id in (select b.id from t2 b)
对于A,用到了t2上的id索引,exists执行次数为t1.length,不缓存exists的结果集。对于B,用到了t1上的id索引,首先执行in语句,然后将结果缓存起来,之后遍历t1表,将满足结果的加入结果集,所以执行次数为t1.length*t2.length次。因此对t1表大t2表小的情况使用in,t2表小t1表大的情况使用exists
(2)not exists和not in:
A:select * from t1 a where not exists (select * from t2 b where b.id = a.id)
B:select * from t1 a where a.id not in (select b.id from t2 b)
对于A,和exists一样,用到了t2上的id索引,exists()执行次数为t1.length,不缓存exists()的结果集。
而对于B,因为not in实质上等于!= and != ···,因为!=不会使用索引,故not in不会使用索引。
因此,不管t1和t2大小如何,均使用not exists效率会更高。
2.4、between ... and ... :

3、模糊查询:
通配符是一种特殊语句,主要用于模糊搜索,常见的通配符包括:
(1)%任意数量的未知字符的替身;
(2)-下划线是一个未知字符的替身。
如:select * from employee where name LIKE '张%';
4、子查询:
将内层查询的结果集作为外层查询的条件使用,如:
select * from employee where entry_time in(select entry_time from employee where name='张三');
三、查询排序:
order by:对查询的结果进行排序,默认为升序。SQL语句不写order by时,表如果含有主键,查询的结果集是默认按照主键进行排序的;如果没有主键,含有其他索引,查询的字段如果含有索引字段,也会默认按照索引进行排序;如果表不含任何索引(主键或其他索引),查询的结果集则的无序的,每次都是随机的,这种情况比如在分页查询时就需要手动添加排序条件,否则下一页数据可能和上一页重复。
select * from employee where dept='软件开发部' order by name ASC,create _time DESC;
ASC是升序,DESC是降序,如果是中文字符,排序会按照其拼音的顺序排序。
四、聚合查询:
做一些统计方面的工作,有两种统计方式:简单统计和分组统计:
1、简单统计:
简单统计主要是利用SQL语言中的内置聚合函数来实现,聚合函数只能出现在select 和from之间。聚合函数不统计NULL值。常见的聚合函数包括:
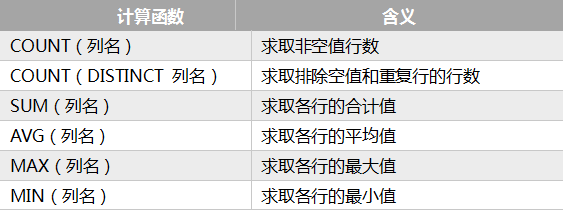
如:

如果想要把NULL值当成0处理,也平均到计算中,参照以下sql
SELECT AVG(COALESCE(salary, 0)) FROM employees;
2、分组统计:group by:
(1)group by 是自带排序的,排序规则同SQL不写order by的情况,即默认按照主键排序,没有主键且用到了索引使用索引字段排序,再没有则是无序。故group by的执行过程分两步,第一步按照group by 后面的分组字段进行分组,然后取每组的第一条记录进行组合做为结果集。如

现在希望得到时间最早的两条user_id记录(user_id不一样):
select * from (select * from repeat_user order by create_time)a group by user_id ;结果集为:

(2)带有条件的分组查询:使用having筛选,如:
 结果集:
结果集:
having和where本质的区别就是where筛选的是数据库表里面本来就有的字段,而having筛选的字段是从前筛选的字段筛选的
举例:现有选课系统:
学生表 student:
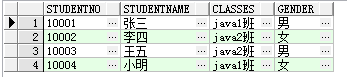
课程表 course:
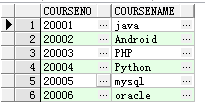
选课表 xk:
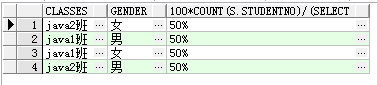
(1)按照班级统计男女的比例:
select s.classes,s.gender,100*count(s.studentno)/(select count(studentno) from student s1 where s.classes=s1.classes)||'%' from student
s group by s.classes,s.gender;
说明:小括号的优先级是最高的,这里最外面的count有条件group by s.classes,s.gender的限制,所以它是分过班级并且分过性别后的人数,里面一层的count统计的则是分过班级后的总数。两者相除即为结果。结果集如下:
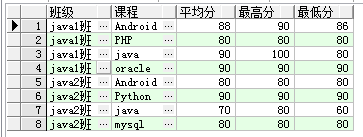
(2)统计各个班级各门课程的平均分、最高分、最低分:
select s.classes 班级,c.coursename 课程,sum(score)/count(id) 平均分,max(score) 最高分,min(score) 最低分 from
xk inner join student s on xk.studentno=s.studentno inner join course c on xk.courseno=c.courseno
group by s.classes,c.coursename order by s.classes;
同样这里有group by的条件。所以这里的sum、max、min都是分过班级、分过课程后的结果集:
(3)查询所有已选课程的函数querycourse:
create or replace function querycourse(sname varchar2) return varchar2 is
Result varchar2(500);
cursor c_job is
select c.coursename from course c inner join xk on c.courseno=xk.courseno
inner join student s on s.studentno=xk.studentno where s.studentname=sname;
c_row c_job%rowtype;
begin
open c_job;
loop
fetch c_job into c_row;
exit when c_job%notfound;
dbms_output.put_line(c_row.coursename);
Result:=Result||c_row.coursename||',';
end loop;
close c_job;
return(Result);
end querycourse;
查询所有未选课程的函数nocourse:
create or replace function nocourse(sname varchar2) return varchar2 is
Result varchar2(500);
cursor c_job is
select c.coursename from course c where c.coursename not in (
select c.coursename from course c
inner join xk on xk.courseno=c.courseno
inner join student s on s.studentno=xk.studentno where s.studentname=sname);
c_row c_job%rowtype;
begin
open c_job;
loop
fetch c_job into c_row;
exit when c_job%notfound;
dbms_output.put_line(c_row.coursename);
Result:=Result||c_row.coursename||',';
end loop;
close c_job;
return(Result);
end nocourse;
查询张三的选课情况:
select s.studentno 学号,s.studentname 姓名,(select querycourse('张三') from dual) 已选课 ,
(select nocourse('张三') from dual) 未选课
from student s where s.studentname='张三';
结果集:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











