







安装好hive后,打开hadoop的目录,可以看到,比之前多了一个tmp文件夹,同时user目录下也多了一个hive文件夹
一、建表及插入
数据准备:在本地准备一个word.txt文件,内容如下:
1 小明
2 小张
3 小美
4 小李
5 小宋
6 小曲
7 小樊
8 小曲
9 小樊
10 小明
11 小美
每行两个数据,中间用空格隔开
show tables;可以查看所有表
现要建立word表,建表和插入都有两种方法,一是在hdfs上hive的warehouse目录下手动建文件夹word(即为表)、上传本地文件word.txt(即为表中数据);
二是在终端启动hive后使用hive命令
create table word(id int,name string) row format delimited fields terminated by ' '; (表示建立一个id-name的表,两个字段间用空格分开)
上传数据:
load data inpath 'hdfs://localhost:9000/user/zt/input1' into table word;这是从hdfs上上传的,如果想从本地导入,可以使用这个load data local inpath '...'
删除表: drop table word;
二、查询操作
其实和sql语句基本相似。
如查询每个name及出现的次数(类似于MapReduce的WordCount):select name,count(*) from word group by name;
终端显示结果如下:
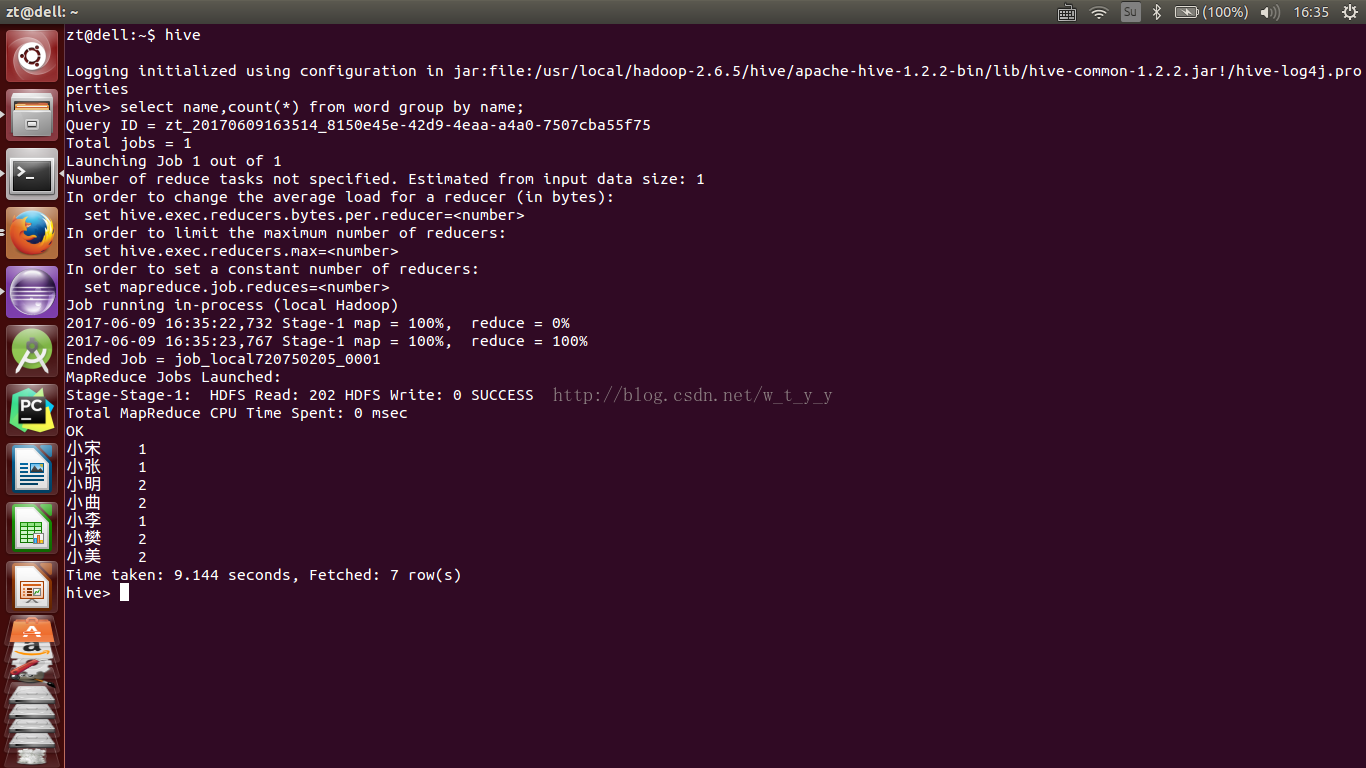
其实如果是在mysql中运行这样的sql 语句,耗时会更小。这就解释了,hive是适合大数据的,在小数据量并不具有优势,而且也是离线服务的,在线服务耗时太长,用户无法接受。之前介绍的MapReduce也是这样,大数据的体系在数据小的时候效率并不高。
数据去重select distinct(name) from word;
统计id平均值select name,sum(id)/count(name) from word group by name;类似于统计平均成绩:
小宋 5.0
小张 2.0
小明 5.5
小曲 7.0
小李 4.0
小樊 8.0
小美 7.0


















 1803
1803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











