



UniSeg
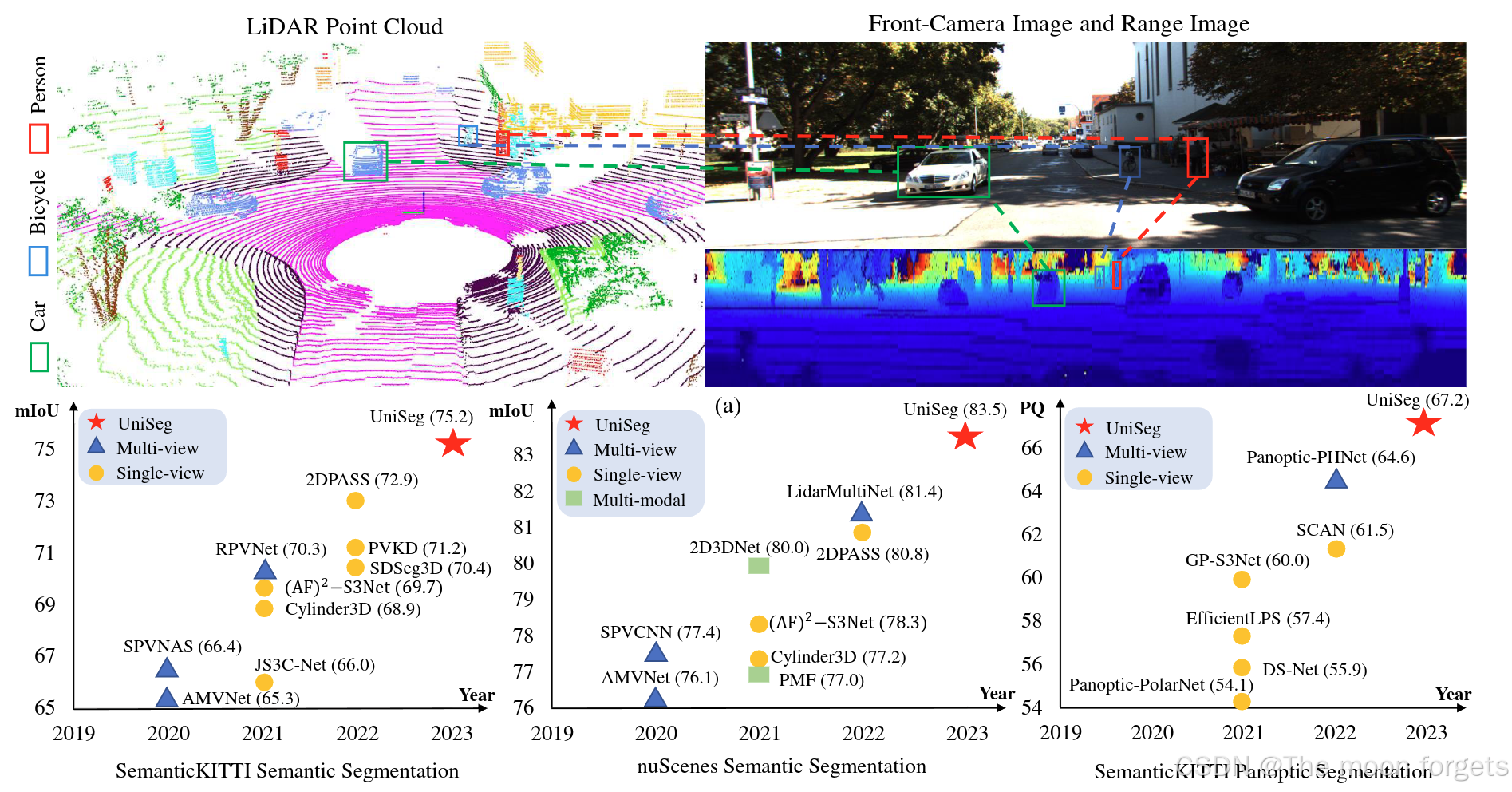
Abstract
point-based保留了最完整的点云的特征和信息,但由于非结构化数据的特点,计算效率底下;Voxel-based实现数据对应的结构化,但体素的划分方式对点云的信息损失h有很大影响;View-based实现了紧凑的特征表征,可以通过2D conv完成后续任务,但是投影本身就破坏了原有的3D结构;RGB-image保留了丰富的语义信息,但缺乏空间信息。
- 提出了一个多模态的点云分割模型(lidar[point-base voxel-base view-base]+image)
- 设计了一个可学习地跨模态关联Learnable cross-ModalAssociation (LMA)模块, 可以自动将Voxel-point和Rv-point与image特征相融合,在充分利用到图像语义信息的同时,对标定误差鲁棒。
- 最终三种形式的point统一在point space,通过可学习地跨视角关联Learnable cross-View Association module (LVA)模块对特征进行自适应融合。
Related work[转述翻译]
LiDAR-Based Semantic Scene Understanding
语义分割和全景分割是基于LiDAR的语义场景理解的两个基本任务。LiDAR语义分割旨在为输入点云序列中的每个点分配一个类标签。LiDAR全景分割分别在stuff 和thing 上执行语义分割和实例分割。大多数 LiDAR 分割方法将点云作为唯一的输入信号。例如,Cylinder3D 将点云划分为圆柱形分区,并将这些圆柱体特征送到基于 UNet 的分割backbone中。SPVCNN引入了point-base 分支来补充Voxel-based 分支,并基于融合的point-voxel特征进行点分割。LidarMultiNet在一个网络中统一了LiDAR语义分割、全景分割和3D目标检测,并实现了很好的感知性能。前面的方法忽略了RGB图像中包含的丰富信息,从而产生次优性能。本文提出的 UniSeg 考虑了点云的所有模态和所有视图,并且可以受益于所有输入信号的优点。
Multi-Modal Sensor Fusion
由于单模态信号有自己的缺点,多模态融合近年来受到越来越多的关注。 PMF(Perception-Aware Multi-Sensor Fusion)将点云投影到透视图中,并通过基于残差的融合模块融合多模态特征。El Madawi等人对距离图像进行早期融合和中间融合,并重新投影的RGB图像。FuseSeg通过校准矩阵将图像特征合并到基于距离图像的主干中。上述方法仅进行一对一多模态融合,不能充分利用RGB图像丰富的语义信息。当校准矩阵不准确时,这些方法性能较差。相比之下,我们的方法可以实现更自适应的多模态特征融合,并使用所提出的可学习跨模态关联模块缓解点像素错位。
Methodology
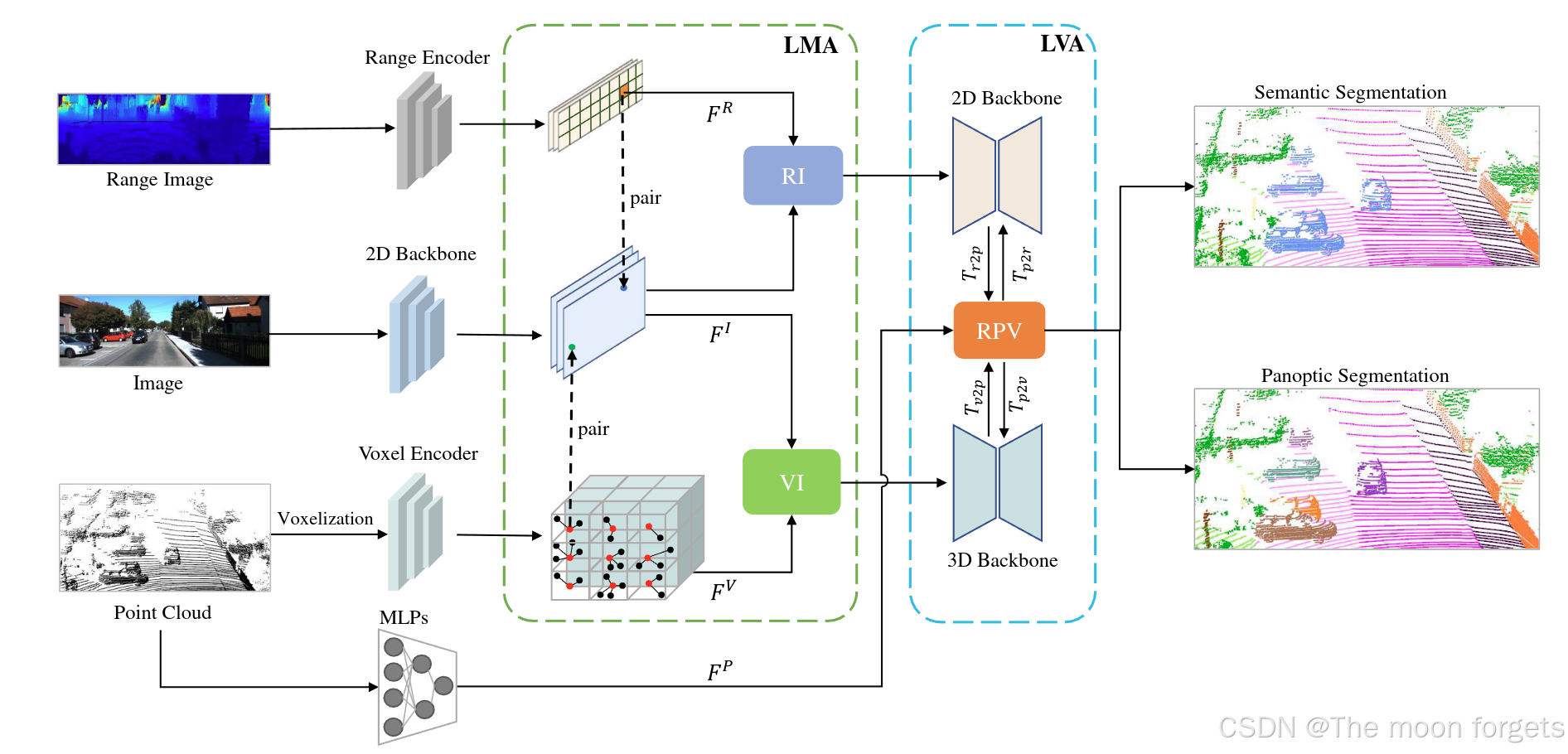
Framework Overview
- 通过变换将获取RV-image,并通过range-view-based backbone提取到对应的RV-image features: FR∈RHR×WR×CR\textbf{F}^R \in \mathbb{R}^{H_R×W_R×C_R}FR∈RHR×WR×CR
- 通过MLPs提取point features: FP∈RN×Cp\textbf{F}^P \in \mathbb{R}^{N×C_p}FP∈RN×Cp
- 体素提取+max pooling:FV∈RNv×Cp\textbf{F}^V \in \mathbb{R}^{N_v×C_p}FV∈RNv×Cp
- RGB-iamges经过ResNet-based backbone提取到对应的RGB-image features: FI∈RHI×WI×CI\textbf{F}^I \in \mathbb{R}^{H_I×W_I×C_I}FI∈RHI×WI×CI
Learnable Cross-Modal Association
- Point-Image Calibration
点云坐标系和图像坐标系之间的转换关系:[ui,vi,1]T=1zi⋅S⋅T⋅[xi,yi,zi,1]T[u_i, v_i, 1]^T = \frac{1}{z_i}·S·T·[x_i, y_i, z_i, 1]^T[ui,vi,1]T=zi1⋅S⋅T⋅[xi,yi,zi,1]T, T∈R4×4T \in \mathbb{R}^{4×4}T∈R4×4为相机外参矩阵,S∈R3×4S \in \mathbb{R}^{3×4}S∈R3×4为相机内参矩阵。 - Voxel-Image Fusion
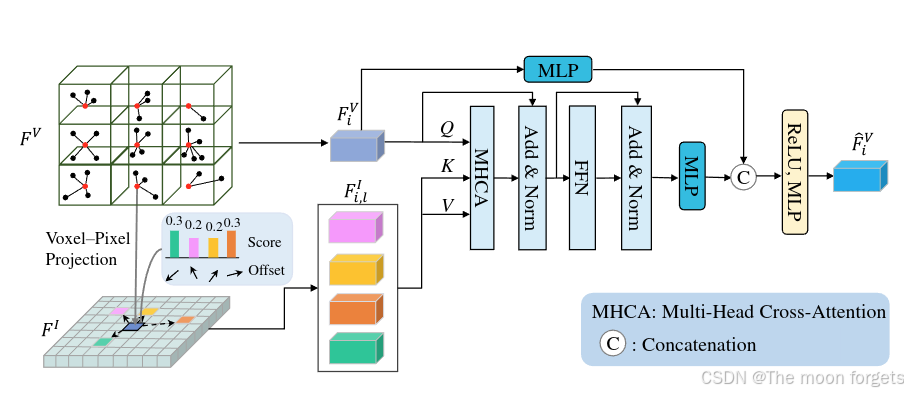
之前的多模态融合模型会受到不准确的外参/标定的影响,受到deformable-detr的启发,Voxel的坐标即为其中心坐标,再根据变换矩阵得到对应的图像坐标,再通过得到的图像坐标估计pixel offsets,最后通过如下公式完成特征融合:
Fi,jI=fI(pi+Δpi,l)F_{i,j}^I = f^I(\textbf{p}_i + \Delta\textbf{p}_{i,l})Fi,jI=fI(pi+Δpi,l)
FˉiV=∑m=1MWm[∑l=1LAi,l,m⋅(Wm′Fi,jI)]\bar{F}_i^V = \sum^M_{m=1}W_m[\sum^L_{l=1}A_{i,l,m}·(W^{'}_mF^I_{i,j})]FˉiV=∑m=1MWm[∑l=1LAi,l,m⋅(Wm′Fi,jI)],
其中FIF^IFI表示image feature, Fi,lIF^I_{i,l}Fi,lI表示采样后的image features, FˉiV∈RN×2Cf\bar{F}^V_i \in \mathbb{R}^{N×2C_f}FˉiV∈RN×2Cf表示最终输出的image-enhanced Voxel feature, WmW_mWm, Wm′W_m^{'}Wm′为可学习的权重,m为MAS的index,M为heads数量,L为采样的图片数量,$\Delta \mathbf{p}{i,j} $ 和 Ai,j,mA_{i,j,m}Ai,j,m分别表示采样offset和l-th采样图像的m-th注意力头的权重
1. 根据变换矩阵和Voxel-center得到image feature FIF^IFI
2. 利用学习到的offsets $\Delta \mathbf{p}{i,j} $ 对L个 FIF^IFI进行采样得到Fi,lIF^I_{i,l}Fi,lI
3. 将FVF^VFV作为QueryQueryQuery, 采样后得到的Fi,lIF^I_{i,l}Fi,lI作为KeyKeyKey和ValueValueValue输入MSA
- Range-Image Fusion
方式同上,最终得到image-enhanced range-view features:FˉR∈RHR×wR×Cf\bar{F}^R \in \mathbb{R}^{H_R×w_R×C_f}FˉR∈RHR×wR×Cf
Learnable Cross-View Association
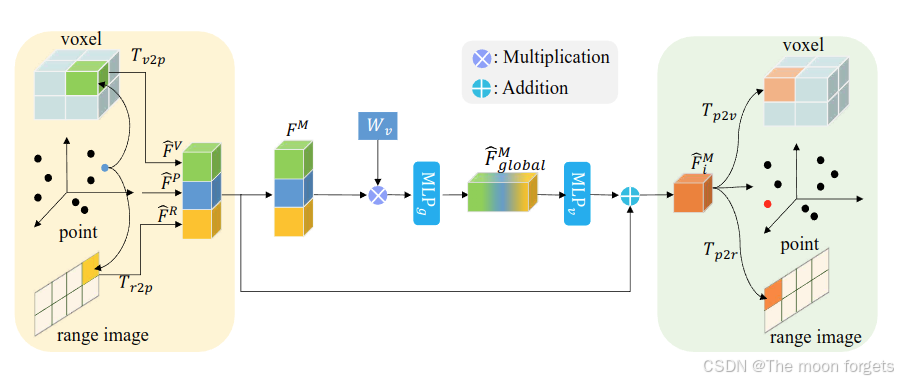
经过LMA之后得到了FˉV∈RN×2Cf\bar{\textbf{F}}^V \in \mathbb{R}^{N×2C_f}FˉV∈RN×2Cf, FˉR∈RHR×wR×Cf\bar{\textbf{F}}^R \in \mathbb{R}^{H_R×w_R×C_f}FˉR∈RHR×wR×Cf和FP∈Rm×Cf\textbf{F}^P \in \mathbb{R}^{m×C_f}FP∈Rm×Cf,再分别通过Tv2pT_{v2p}Tv2p和三线性插值得到point-wise voxel features:FˉV∈Rm×Cf\bar{\textbf{F}}^V \in \mathbb{R}^{m×C_f}FˉV∈Rm×Cf;,Tr2pT_{r2p}Tr2p和双线性插值得到point-wise range image features: FˉR∈Rm×Cf\bar{\textbf{F}}^R \in \mathbb{R}^{m×C_f}FˉR∈Rm×Cf,最终concat得到 multi-view features: FM∈Rm×3Cf\textbf{F}^M \in \mathbb{R}^{m×3C_f}FM∈Rm×3Cf之后FM\textbf{F}^MFM经过可学习地加权矩阵和MLPs得到最终的multi-view features: FˉglobalM=ReLU(MLPg(Wv(concat(FˉV,FˉR,FˉP)))){\bar{\textbf{F}}}^M_{global} = \text{ReLU}(\text{MLP}_g(W_v(\text{concat}(\bar{\textbf{F}}^V,\bar{\textbf{F}}^R, \bar{\textbf{F}}^P))))FˉglobalM=ReLU(MLPg(Wv(concat(FˉV,FˉR,FˉP)))), FˉglobalM∈Rm×Cf{\bar{\textbf{F}}}^M_{global} \in \mathbb{R}^{m×C_f}FˉglobalM∈Rm×Cf
之后,在通过跳连得到融合后的全局特征:FˉM=FˉM+ReLU(MLPg(FˉglobalM))\bar{\textbf{F}}^M= \bar{\textbf{F}}^M + \text{ReLU}(\text{MLP}_g(\bar{\textbf{F}}^M_{global} ))FˉM=FˉM+ReLU(MLPg(FˉglobalM)),再通过对应的逆变换得到各自增强后的特征。
Task-Specific Heads
融合处理之后的特征会输入到分类头中得到语义分割的预测结果,进一步地会送到全景分割头中估计实例中心的位置和offsets,生成进一步地全景分割的结果。
Overall Objective
L=Lwce+αLlovasz+βLheatmap+γLoffset\mathcal{L} = \mathcal{L}_{\text{wce}} + \alpha \mathcal{L}_{\text{lovasz}} + \beta \mathcal{L}_{\text{heatmap}} + \gamma \mathcal{L}_{\text{offset}}L=Lwce+αLlovasz+βLheatmap+γLoffset
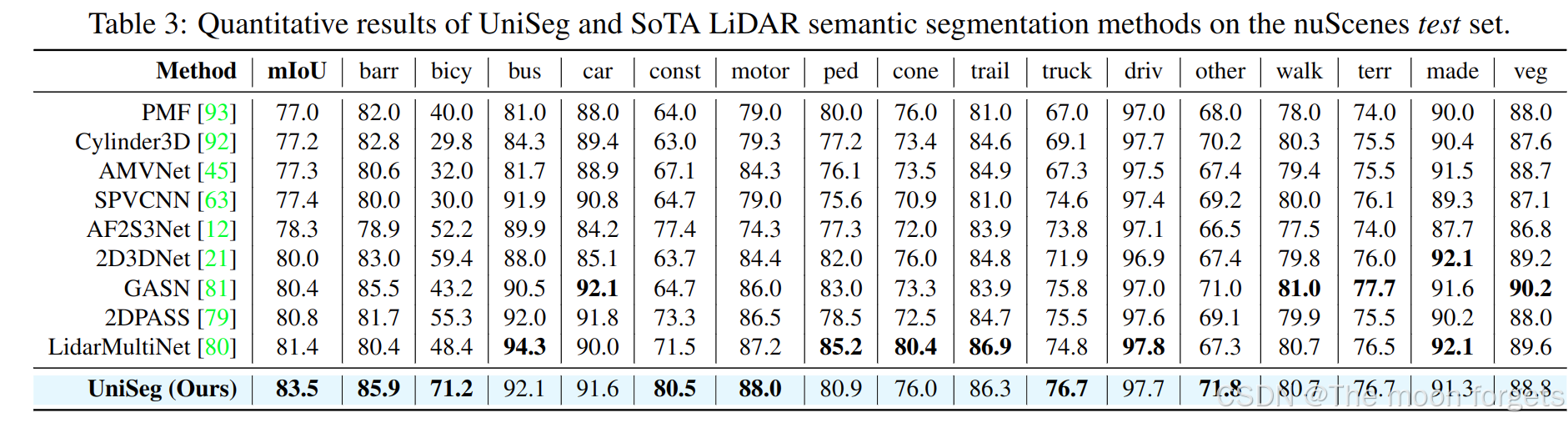
Experiments

















 1533
1533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









