



Relation DETR
Abstract
DETRs训练收敛慢的根源使用匈牙利匹配算法为每个真值匹配了唯一的预测正样本,而导致余下的预测结果均作为负样本干扰了训练进程,因此就需要更多的数据和训练轮次进行收敛。之前的工作更多的侧重于优化训练流程(增加额外的监督或优化损失函数)或提出特定的网络结构(优化query)。但是DETRs的核心在于MSA,而self-attention的关键在于提取数据间的关联关系,而输入self-attention的图像数据不会引入结构化偏置,因此
- 本文将位置关系作为先验知识引入到self-attention中,从而实现更高效的训练。
- 提出了定量宏观相关性(MC)度量验证了所提出方法的统计意义的重要性。
Related Work
Transformer for Object Detection
Transformer在目标检测的应用中多尝试构建并行化序列。具体而言,基于Transformer的特征提取器基于图像块生成token序列,并通过聚合局部特征或金字塔后处理提取多尺度特征。DETR将初步处理后得到的图像特征编码为目标的queries,再解码为检测目标的坐标框和类别,然而这种自学习的注意力机制需要更大规模的数据量和更多的训练轮次才能收敛。许多工作从结构化注意力的角度探索了缓慢收敛的问题(例如多尺度可变形注意力、动态注意力、级联窗口注意力),具有明确先验的查询(例如锚点查询、动态锚点框查询、去噪查询、密集区分查询),以及额外的正向监督(例如群组查询、混合设计、混合匹配)。然而,即使是最先进的DETR方法仍然在Transformer解码器中使用标准的多头注意力。很少有工作从隐式先验的角度探索缓慢收敛的问题。本文旨在通过位置关系来解决这个问题。
Relation Network
不同于像素、patch、图像级别的特征处理,Relation Network捕捉的是实例/类别间的对应关系,现有的Relation Network主要涉及category-based 和 instance-based方法。
- category-based
主要从relation数据集(Visual Genome)或通过自适应地从标签中学习构建概念性或统计性关系,然而由于category的稀疏性,会带来额外的计算复杂度。 - instance-based
直接给定一组物体特征作为节点集合,以及它们之间的关系作为边集合,从而构造出精细的图结构。因此,在训练过程中对图进行推理自然确定了明确的关系权重。通常情况下,权重表示高维空间中每对物体实例之间的参数距离,例如外观相似度、提议距离甚至是自注意力权重。
Classification loss for hard mining
在物体检测训练过程中,分配给真值的正样本远少于负样本,从而导致样本分布不平衡和收敛缓慢。对于分类任务,Focal Loss提出引入一个权重参数来关注难例样本,这一方法进一步扩展为多种变体,如generalized focal loss (GFL) 、vari focal loss (VFL) 。此外,对于物体检测任务,使用基于回归度量的调制项损失(例如TOOD、IA-BCE、位置监督损失)进一步实现了分类和回归任务之间的高质量对齐。
Statistical significance of object position relation
“Are objects really correlated in object detection tasks?”
本文提出了一种基于皮尔逊相关系数 (Pearson Correlation Coefficient PCC) 的定量宏观关联 (macroscopic correlation MC) 指标,用于衡量单个图像中物体间的位置关联。假设图像中的所有对象形成一个节点集合,每对边界框标注之间的PCC则作为节点间对应的边权重,从而可以使用连续值构建一个无向图表征每个图像可以使用图强度进行表示:
MC=∑i∑j:j≠i∣Pearson(bi,bj)∣N(N−1)MC = \frac{\sum_i \sum_{j:j≠i}|\text{Pearson}(\textbf{b}_i, \textbf{b}_j)|}{N(N-1)} MC=N(N−1)∑i∑j:j=i∣Pearson(bi,bj)∣
,其中NNN表示目标数b=[x,y,w,h],MC∈[0,1]\textbf{b} = [x, y, w, h], MC \in [0,1]b=[x,y,w,h],MC∈[0,1]
Pearson相关系数(Pearson Correlation Coefficient)是一种用于衡量两个变量之间线性相关性强弱的统计量。它衡量了两个变量之间的线性关系程度,取值范围从 -1 到 1。
具体来说,Pearson相关系数衡量了两个变量之间的线性关系强度和方向。如果相关系数为 1,表示两个变量完全正相关(即一个变量增加,另一个也增加);如果相关系数为 -1,表示两个变量完全负相关(即一个变量增加,另一个减少);如果相关系数为 0,表示两个变量之间没有线性关系。
Pearson相关系数的计算公式如下:
r=∑(Xi−Xˉ)(Yi−Yˉ)∑(Xi−Xˉ)2∑(Yi−Yˉ)2r = \frac{\sum{(X_i - \bar{X})(Y_i - \bar{Y})}}{\sqrt{\sum{(X_i - \bar{X})^2}\sum{(Y_i - \bar{Y})^2}}}r=∑(Xi−Xˉ)2∑(Yi−Yˉ)2∑(Xi−Xˉ)(Yi−Yˉ)
其中,rrr表示Pearson相关系数,XiX_iXi和 $ Y_i 分别表示两个变量的观测值,分别表示两个变量的观测值,分别表示两个变量的观测值,\bar{X} 和和和 \bar{Y} $ 分别表示两个变量的均值。
Pearson相关系数通常用于统计学和数据分析中,用于了解变量之间的关系以及预测一个变量如何受另一个变量影响。它是一种常用的统计量,可帮助分析数据集中变量之间的关联程度。
MC在不同场景下的统计分布可视化:
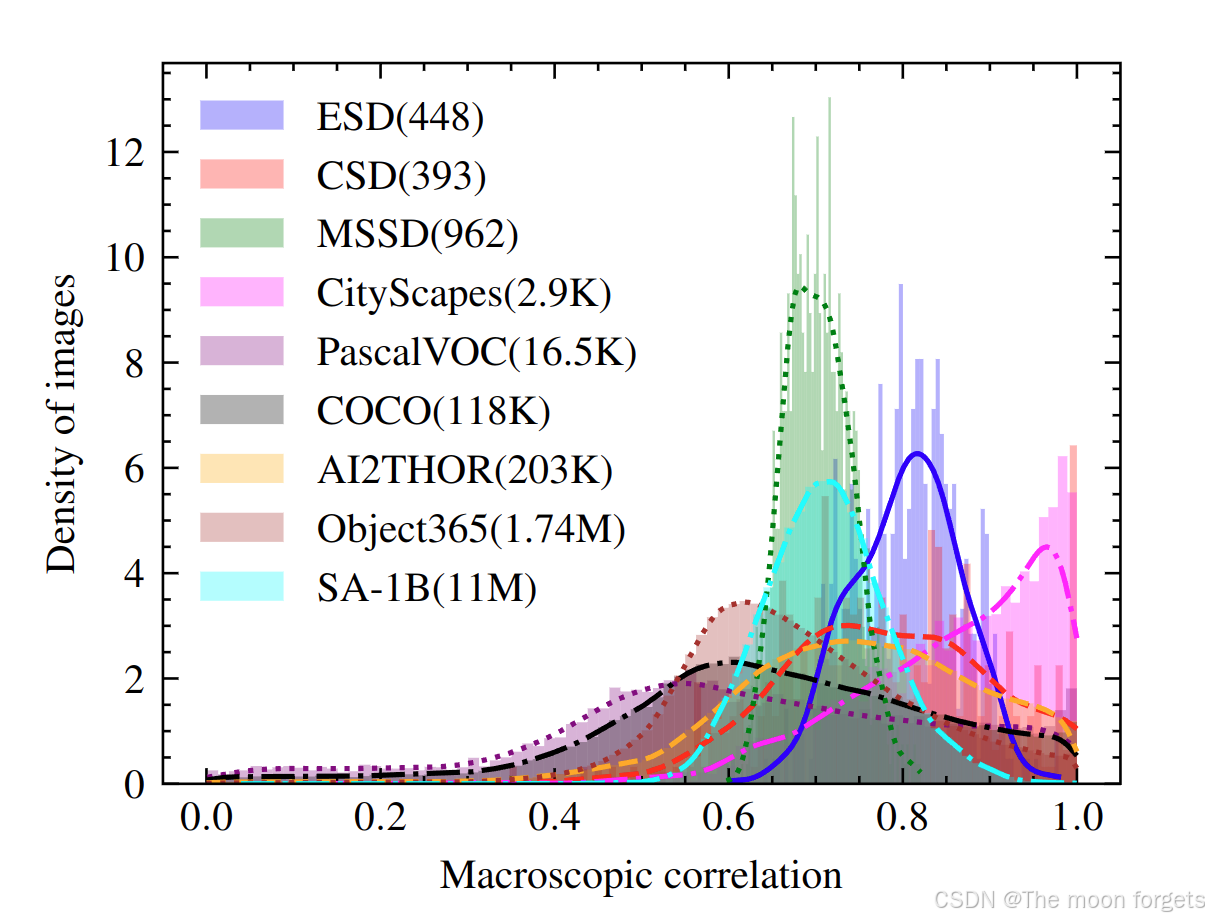
结果表明所有的数据集的MC分布都集中在高数值范围,这证明了物体位置关系的存在及其统计显著性,并且task-specific数据集的MC分布要更加集中和显著,展现出更多的位置先验信息。
Relation-DETR
Position relation encoder
之前的研究中已经表明了关联关系在卷积中的作用,DETRs则尝试通过使用类别的index顺序构建实例级别的关联关系。与这些方法相比,本文通过简单的位置编码器直接构建实例级关联关系,为 DETR 维护一个端到端的设计。
在现有的DETR pipeline中,本文提出的位置关系编码器将高维关系embedding表示为Transformer自注意力中的显式先验。(embedding是根据每个解码器层的预测边界框b=[x,y,w,h]\textbf{b} = [x, y, w, h]b=[x,y,w,h] 计算的)为了确保关联关系的空间变换不变性,我们根据归一化的相对几何特征对其进行编码:
e(bi,bj)=[log(∣xi−xj∣wi+1),log(∣yi−yj∣hi+1),log(wiwj),log(hihj)]\textbf{e}(\textbf{b}_i, \textbf{b}_j) = [\log(\frac{|x_i-x_j|}{w_i}+1), log(\frac{|y_i-y_j|}{h_i}+1), log(\frac{w_i}{w_j}), log(\frac{h_i}{h_j})]e(bi,bj)=[log(wi∣xi−xj∣+1),log(hi∣yi−yj∣+1),log(wjwi),log(hjhi)]
这一关系表示是无偏的,即当i=ji=ji=j时,e(bi,bj)=0\textbf{e}(\textbf{b}_i, \textbf{b}_j) = 0e(bi,bj)=0$。进一步可以将关系矩阵转换为高维embeddings:
E∈RN×N×4\textbf{E} \in \mathbb{R}^{N \times N \times 4}E∈RN×N×4
Embed(E,2k)=sin(sET2k/dre)\text{Embed}(\textbf{E}, 2k) = \sin(\frac{s\textbf{E}}{T^{2k/d_{re}}})Embed(E,2k)=sin(T2k/dresE)
Embed(E,2k+1)=cos(sET2k/dre)\text{Embed}(\textbf{E}, 2k+1) = \cos(\frac{s\textbf{E}}{T^{2k/d_{re}}})Embed(E,2k+1)=cos(T2k/dresE)
,其中Embed∈RN×N×4dre,T,dre,s\textbf{Embed} \in \mathbb{R}^{N \times N \times 4d_{re}}, T, d_{re}, sEmbed∈RN×N×4dre,T,dre,s为编码参数。最终经过一个线性变换得到M个标量权重:
Rel(b,b)=max(ϵ,WEmbed(b,b)+B)\text{Rel}(\textbf{b}, \textbf{b}) = \max(\epsilon, \textbf{W} \text{Embed}(\textbf{b},\textbf{b}) + \textbf{B})Rel(b,b)=max(ϵ,WEmbed(b,b)+B)
Progressive attention refinement with position relation
Deformable-DETR提出的可迭代box refinement提升了检测框的回归精度,在此基础上,本文提出了一种渐进式注意力细化机制,将位置关系引入到DETR pipeline中,其中第l层的关系是由第l层和第l-1层的关系共同决定的。具体可以表示为(公式太长懒得打系列):
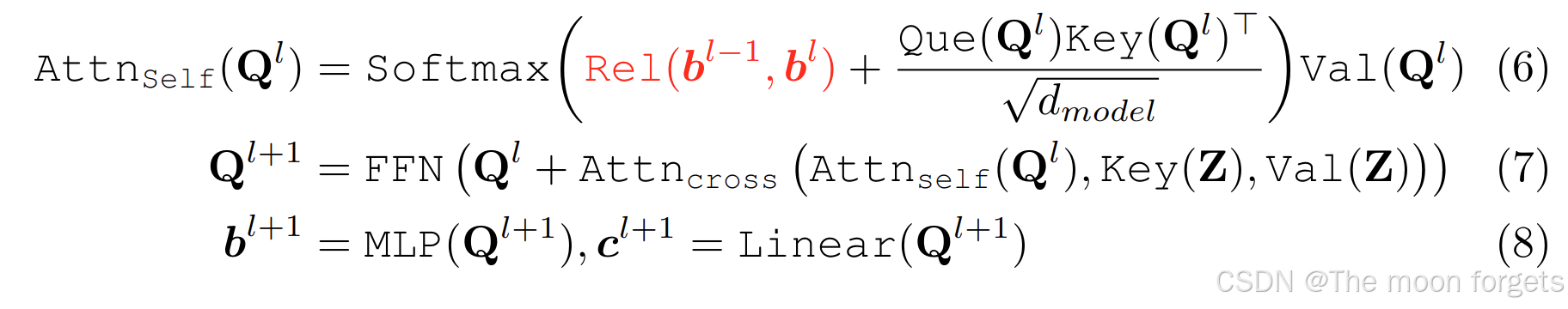
与Deformable-DETR的对比:
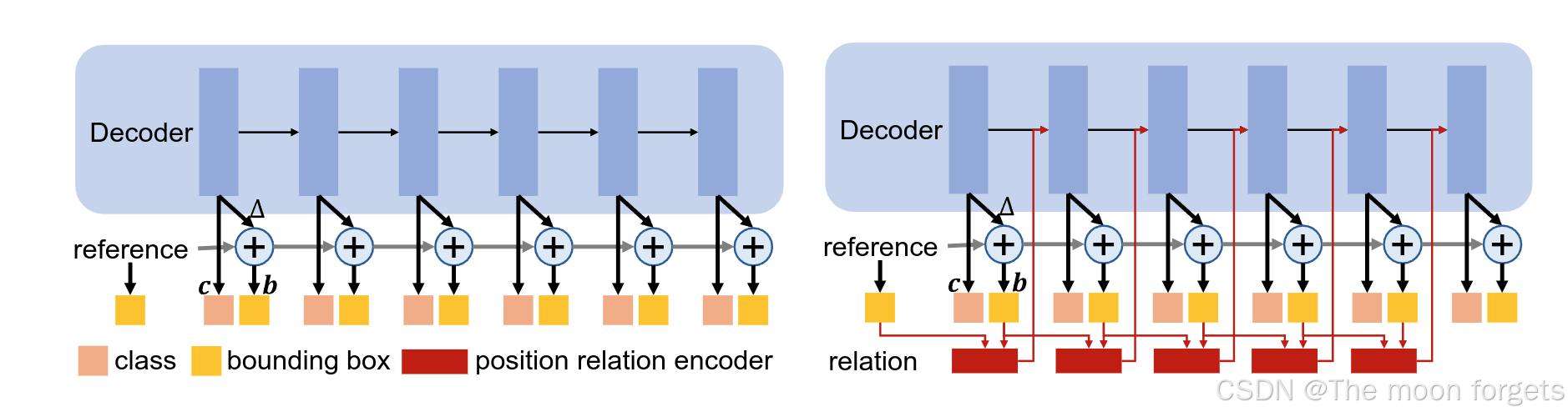
Contrast relation pipeline
分析现有的去重方法(NMSs),都需要一定程度上依赖于IoU,而IoU也是反映目标框位置关联关系的指标之一。因此我们可以推断在self-attention中整合位置关系queries有助于非重复性预测。
而现有的非重复预测与充分正样本监督的问题来源于DETR的pipeline机制,必须要在一对一和一对多之间找到一个平衡点。为了解决这一问题,我们基于位置关联关系将其扩展到了对比pipeline中,构建了两个平行的query集合,匹配queriesQMQ_MQM, 混合queries QMQ_MQM.两者都是decoder的输入,但经过了不同的处理过程:
-
匹配queries QMQ_MQM经过了self-attention的处理,结合位置关系产生非重复预测结果:
Attnself(Qml)=Softmax(Rel(bl−1,bl)+Que(Qm)Key(Qm)Tdmodel)Val(Qm)\text{Attn}_{self}(\textbf{Q}^l_m) = \text{Softmax}(\text{Rel}(\textbf{\textit{b}}^{l-1},\textbf{\textit{b}}^{l}) + \frac{\text{Que}(\textbf{Q}_m)\text{Key}(\textbf{Q}m)^\text{T}}{\sqrt{d{model}}})\text{Val}(\textbf{Q}_m)Attnself(Qml)=Softmax(Rel(bl−1,bl)+dmodelQue(Qm)Key(Qm)T)Val(Qm)
Attnself(Qhl)=Softmax(Que(Qh)Key(Qh)Tdmodel)Val(Qh)\text{Attn}_{self}(\textbf{Q}^l_h) = \text{Softmax}(\frac{\text{Que}(\textbf{Q}_h)\text{Key}(\textbf{Q}h)^\text{T}}{\sqrt{d{model}}})\text{Val}(\textbf{Q}_h)Attnself(Qhl)=Softmax(dmodelQue(Qh)Key(Qh)T)Val(Qh) -
混合queries QMQ_MQM则经过相同的decoder处理,但是跳过了位置关系的计算来获取更多的候选框:
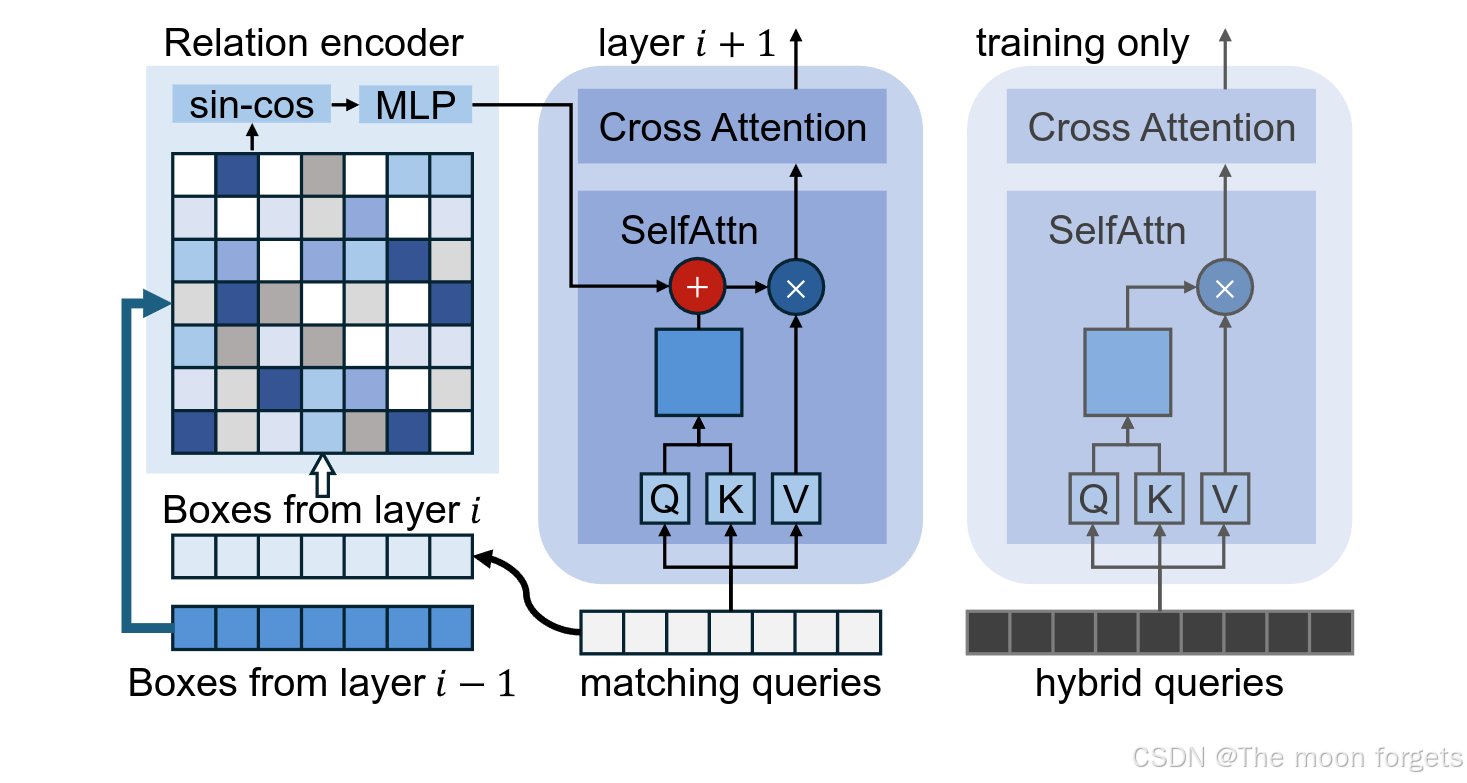
-
对于匹配queries, 使用一对一匹配机制,沿用DETR原生计算方法:
Lm(qm,g)=∑l=1LLHungarian(qml,g)\mathcal{L}_m(\textbf{\textit{q}}m, \textbf{\textit{g}}) = \sum{l=1}^L\mathcal{L}_{Hungarian}(\textbf{\textit{q}}_m^l, \textbf{\textit{g}})Lm(qm,g)=∑l=1LLHungarian(qml,g) -
对于混合queries,使用一对多匹配机制,使用H-DETR的机制,并对真值g\textbf{\textit{g}}g进行KKK次重复,gˉ={g1,g2,...,gK}\bar{\textbf{\textit{g}}} = \{\textbf{\textit{g}}^1, \textbf{\textit{g}}^2, ...,\textbf{\textit{g}}^K\}gˉ={g1,g2,...,gK}:
Lm(qh,g)=∑l=1LLHungarian(qhl,gˉ) \mathcal{L}_m(\textbf{\textit{q}}h, \textbf{\textit{g}}) = \sum{l=1}^L\mathcal{L}_{Hungarian}(\textbf{\textit{q}}_h^l, \bar{\textbf{\textit{g}}})Lm(qh,g)=∑l=1LLHungarian(qhl,gˉ)
#Results
![[图片]](https://i-blog.csdnimg.cn/direct/32b8f21192d64de1bcc4ea468046d5c1.png)
![[图片]](https://i-blog.csdnimg.cn/direct/d4ac55aa641c484692df54c8bb654f17.png)

















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









