






🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主
🎄所属专栏:『LabVIEW深度学习实战』
📑推荐文章:『LabVIEW人工智能深度学习指南』
🍻本文由virobotics(仪酷智能)原创🥳欢迎大家关注✌点赞👍收藏⭐留言📝订阅专栏
🧩前言
大家好,这里是仪酷智能 VIRobotics。
工业自动化和智能制造不断推动计算机视觉技术的深入应用,其中 文字识别(OCR) 是一项基础却关键的能力。从仪表读数、零件标识到铭牌检测,OCR在工业场景中广泛应用。然而传统OCR方法在面对复杂背景、模糊字符、变形文本时,往往力不从心。PaddlePaddle团队推出的最新PP-OCRv5模型,在精度、鲁棒性和推理效率上取得显著提升,凭借其轻量化架构和优异的性能,成为当前开源OCR方案中的佼佼者。
今天我们给大家介绍使用 AI Vision Toolkit for OpenVINO™ for LabVIEW™(AIVT-OV),在 LabVIEW 中低代码部署PP-OCRv5,实现工业场景下的高效文字识别。
📦 工具介绍:AIVT-OV是什么?
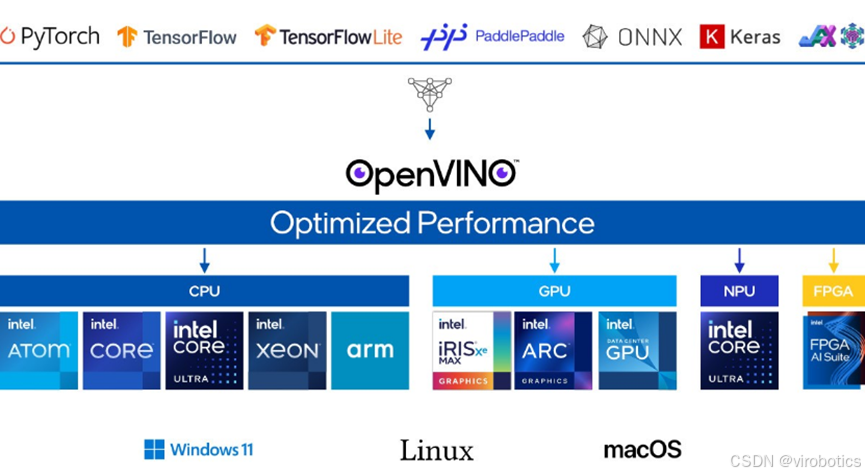
AIVT-OV 是一个基于 Intel OpenVINO™ 构建、由仪酷智能专为 LabVIEW 开发的
AI视觉工具包,它具备以下优势:
✅ 低代码使用:可视化拖拽,无需 Python/C++ 经验;
✅ 模型格式广:兼容 PaddlePaddle、ONNX、TensorFlow、PyTorch等框架模型;
✅ 平台支持全:CPU/GPU/NPU 通吃;
✅ 范例范围广:包含PaddleOCR、YOLO、Pose、Seg、DeepLab、Unet、SAM、Segment Anything、DeepSeek 等AI模型范例;
✅ 集成体验佳:LabVIEW风格原生API,完美融合工业控制与AI处理。
🔍 工业OCR的实际痛点
在真实工业场景中,OCR经常遇到这些挑战:
📸 图像模糊、反光、油污
🔠 中文英文符号混排
🌀 弯曲、倾斜、遮挡
🔍 动态采集,图像分辨率不一致
PaddleOCR(PP-OCRv5)的模型体系采用检测+分类+识别三级结构,在复杂背景下仍能稳定提取文本信息。PP-OCRv5源码可见:https://github.com/PaddlePaddle/PaddleOCR
🛠 实战演示:LabVIEW中三步搞定PPOCR部署
第1步:环境准备
-
操作系统:> = Windows 10(64位)
-
LabVIEW: >= 2018 (64-Bit)。
-
AIVT-OV:安装 AIVT-OV
最新版工具包(VXgongzhonghao:仪酷智能科技回复"AIVT-OV"获取),运行下载的安装包,按照提示完成安装,更多安装问题可以参考安装教程。
第2步:打开OCR范例程序
1、在LabVIEW菜单中点击:
Help >> Find Examples >> VIRobotics >> AI Vision >> PaddleOCR
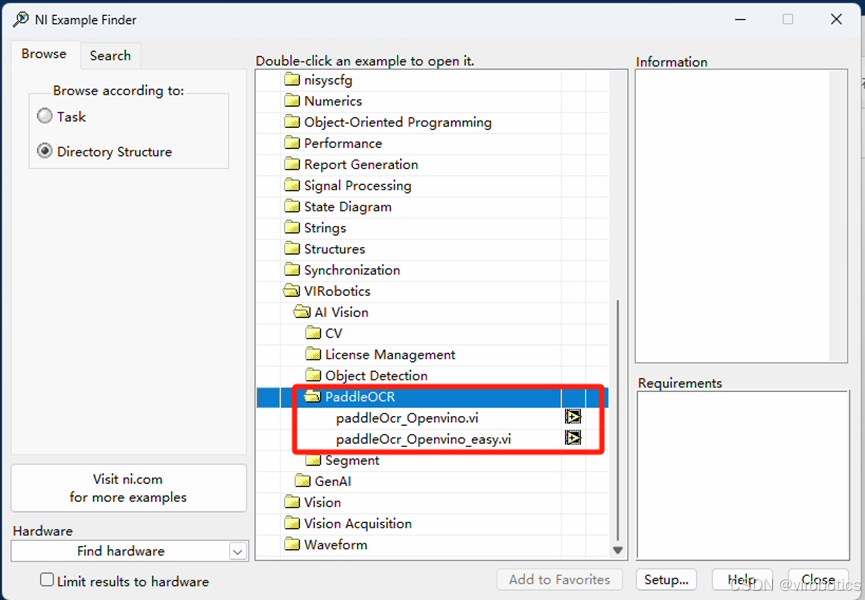
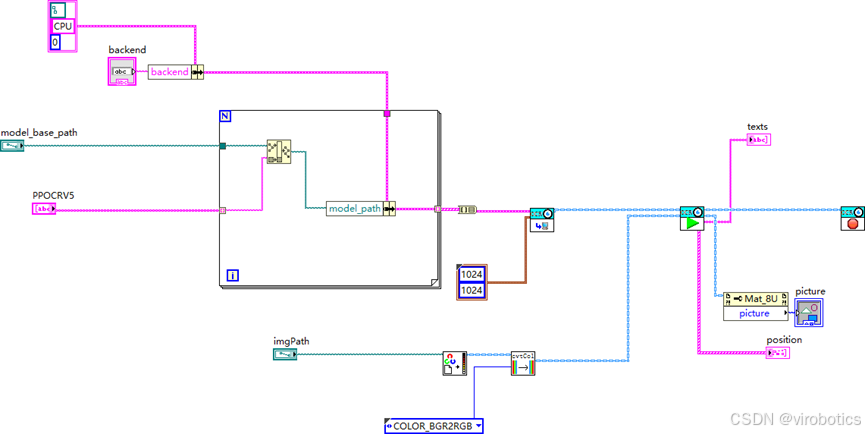
2、双击paddleOcr_Openvino_easy.vi,打开程序框图面板,即可看到如下流程:
初始化模型 → 加载图片 → 推理识别 → 输出展示
第3步:模型选择 + 图像识别
加载待识别图片,点击"运行"
👇识别结果图如下所示:
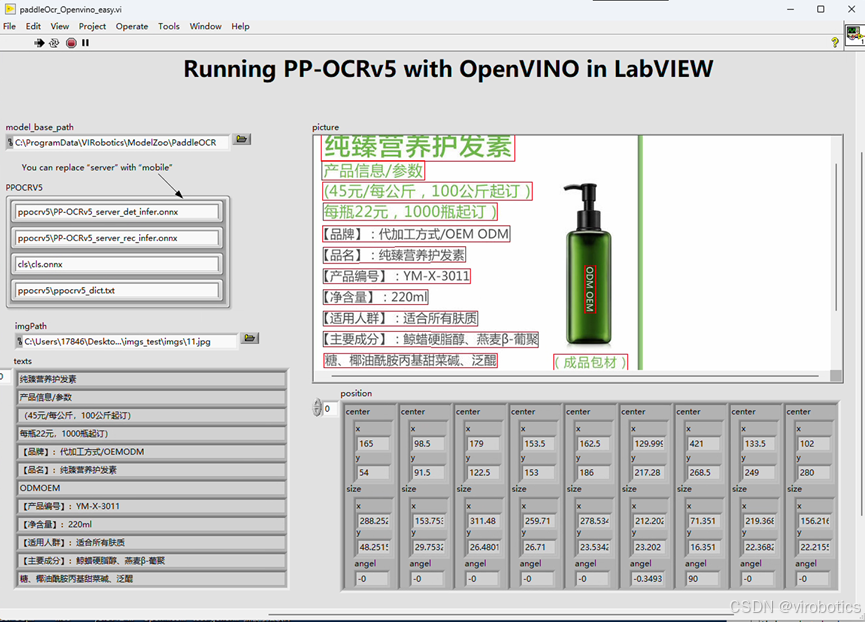
目前范例默认加载色是server模型,可以修改server为"mobile",再次测试识别结果
| 模型版本 | 精度 | 速度 | 推荐场景 |
|---|---|---|---|
| PPOCRv5-server | 高 | 中 | 高精度检测、服务器端部署 |
| PPOCRv5-mobile | 中 | 高 | 实时场景、边缘设备、嵌入式系统 |
你可以按需切换模型实现"轻量化或精度优先"的部署策略。
🔧 高级玩法:多模型版本
如果你需要更多功能扩展,推荐使用此增强版示例paddleOcr_Openvino.vi,具备以下高级特性:
🧠 多模型版本集成
支持多个PPOCR版本切换:
-
PP-OCRv3(支持中/英文模型)
-
PP-OCRv4(精度与效率均衡)
-
PP-OCRv5(支持server/mobile架构)
只需在前面板菜单中选择,系统将自动加载对应模型。
🎯 可调节 scale 参数
🔄 CLS方向分类模块启用选择
根据识别场景(中文字符、非水平排列、扭曲字符),用户可启用或关闭CLS分类器模块,增强识别准确率与适应性。
双击paddleOcr_Openvino.vi,打开程序框图面板,即可看见如下所示程序:
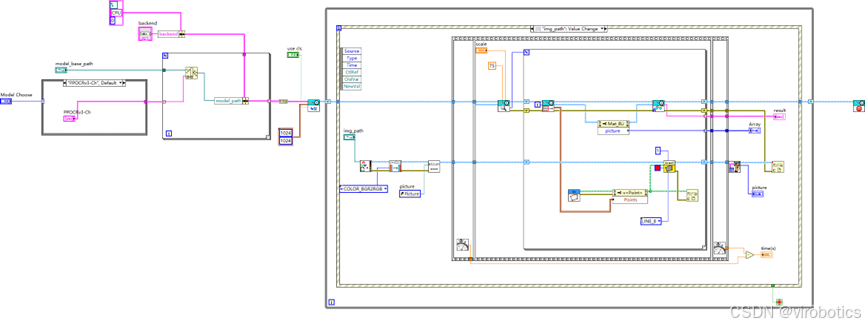
选择本次预计使用的模型,设置参数,运行程序,选择待识别图片,完成检测,点击STOP可结束程序,也可继续选择其他图片完成检测。
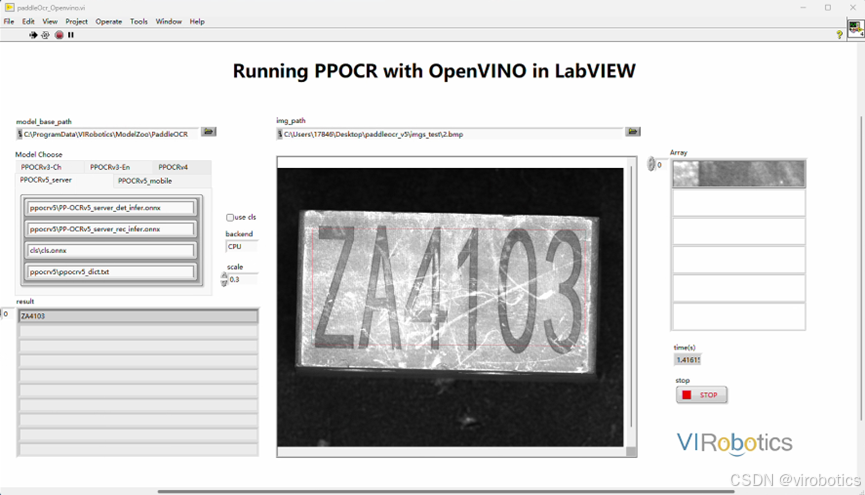
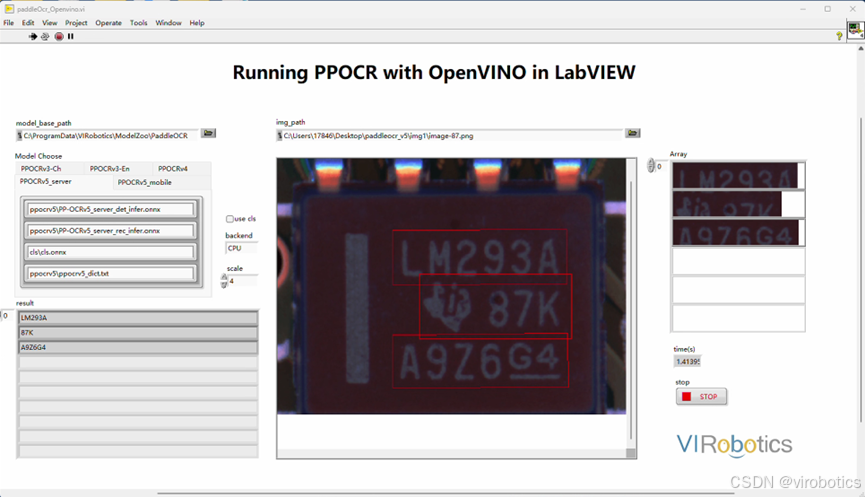
也可以切换不同类型模型进行检测,如下所示两图分别是使用PPOCRv5的server和mobile模型检测结果,很明显,mobile模型检测速度更快。
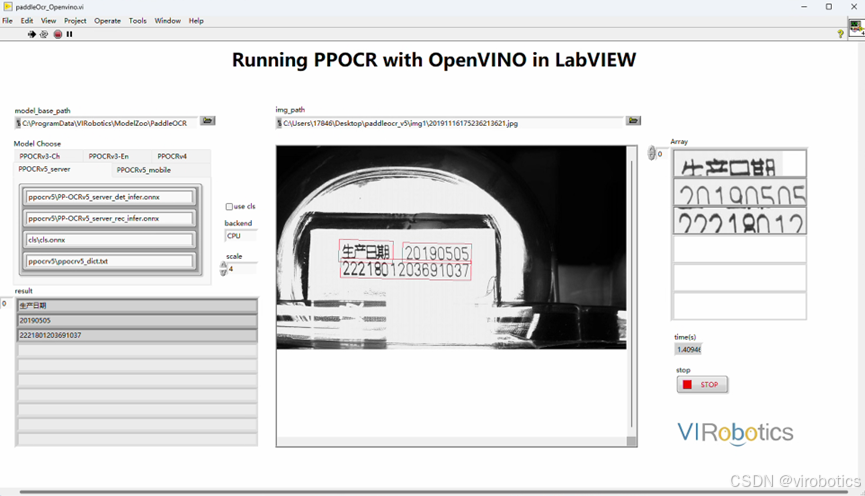
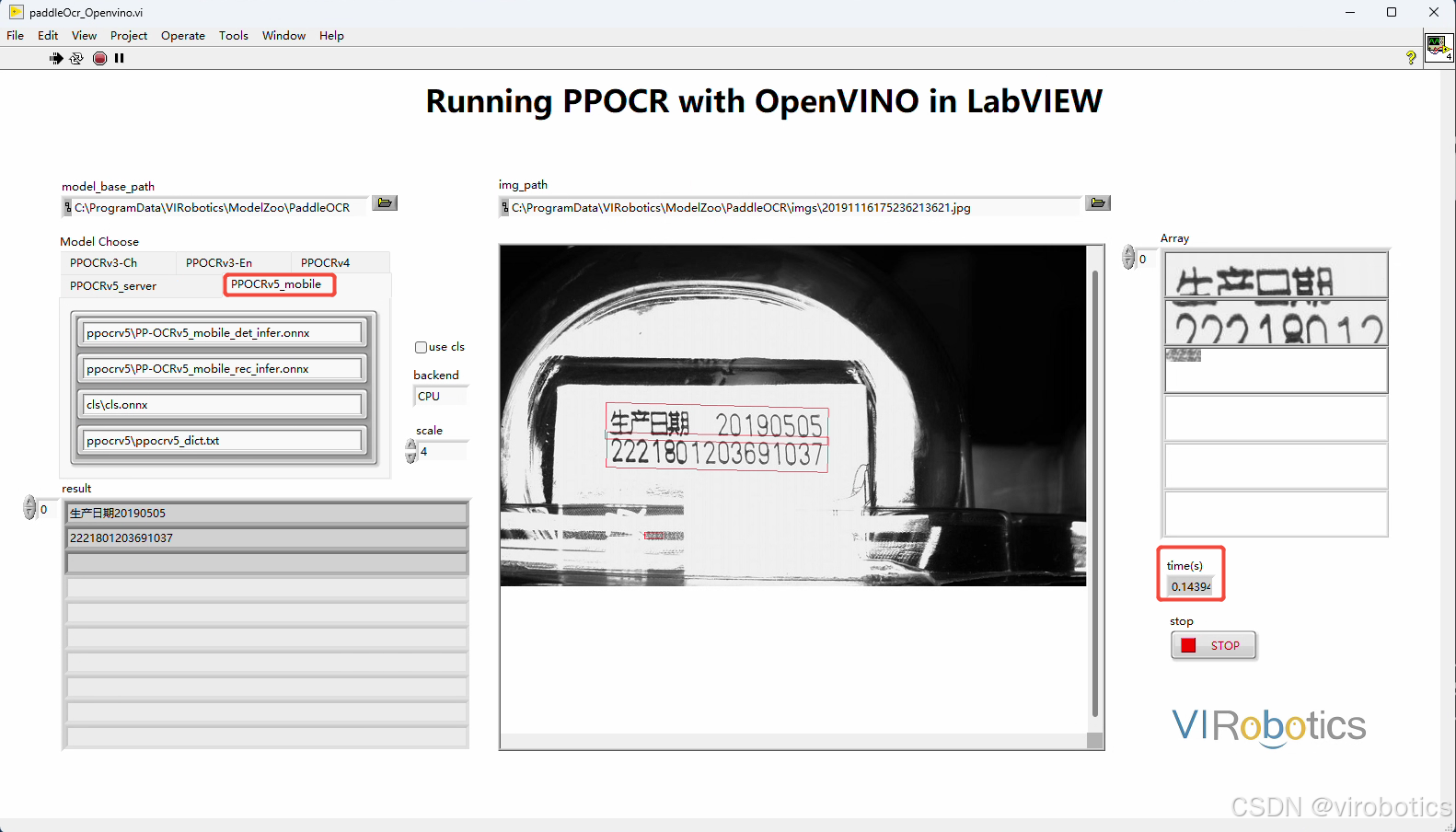
当然,模型参数可以组合使用,比如使用PP-OCRv4的detect+PP-OCRv5的rec
🎯总结
以上就是今天要给大家分享的内容,希望对大家有用。如有笔误,还请各位及时指正。后续我们将为大家更新更多关于AI模型在LabVIEW的部署案例,欢迎大家关注博主。我是virobotics(仪酷智能),我们下篇文章见~
如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。进群请备注:仪酷智能
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码))
【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码)
【YOLOv8】实战一:手把手教你使用YOLOv8实现实时目标检测
【YOLOv8】实战二:YOLOv8 OpenVINO2022版 windows部署实战
【YOLOv8】实战三:基于LabVIEW TensorRT部署YOLOv8
【YOLOv9】实战一:在 Windows 上使用LabVIEW OpenVINO工具包部署YOLOv9实现实时目标检测(含源码)
【YOLOv9】实战二:手把手教你使用TensorRT实现YOLOv9实时目标检测(含源码)
【YOLOv11】实战一:在LabVIEW 中使用OpenVINO实现YOLOv11
👇技术交流 · 一起学习 · 咨询分享,请联系👇


















 1716
1716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











