




🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主
🎄所属专栏:『AI Agent for LabVIEW』
📑推荐文章:『LabVIEW人工智能深度学习指南』
🍻本文由virobotics(仪酷智能)原创🥳欢迎大家关注✌点赞👍收藏⭐留言📝订阅专栏
文章目录
🧩前言
大家好,这里是仪酷智能VIRobotics。
今天主要想要和大家分享如何在 仪酷智能 Agent 环境下创建、配置并调用自定义 VI 工具。我们将从最基础的工具制作讲起,到最后实现智能 Agent 自动调用 VI 的完整过程。
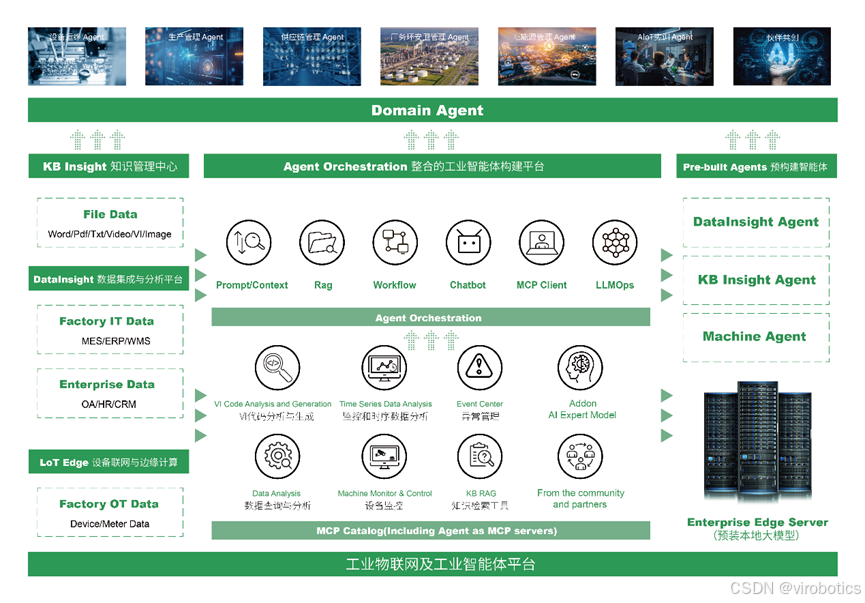
一、仪酷智能Agent简介
AI Agent for LabVIEW 是由 仪酷智能 开发的智能体工具包,为 LabVIEW 用户提供与大语言模型(LLM)的无缝集成体验。通过该工具,用户可以在 LabVIEW 中直接调用多家主流模型服务,实现自然语言交互、自动生成 VI、文档解析与硬件控制等功能。
作为业内首个深度集成大模型的 LabVIEW 智能体工具,AI Agent 让用户能够通过自然语言快速创建、理解和调用 VI,构建智能实验室与自动化控制系统,加速工程研发与测试流程智能化。
二、主要功能
| 能力 | 功能说明 |
|---|---|
| 生成 VI | 由大模型根据自然语言自动生成 VI 逻辑,帮助快速搭建程序原型。 |
| 解析 VI | 分析现有 VI 文件的功能、输入输出、层次结构和逻辑关系。 |
| 视觉生成与理解 | 对图像进行生成、识别与分析,实现视觉智能。 |
| 文档解析 | 自动解析 PDF、Word、Excel 等多种文档格式并提取关键信息。 |
| 文本与代码生成 | 根据自然语言指令生成文本报告、算法脚本或 LabVIEW 代码片段。 |
| 硬件交互 | 与传感器、执行器、采集卡等硬件进行智能交互与控制。 |
| VI 工具制作与调用 | 允许用户编写自定义 VI 工具,并由智能 Agent 自动调用,实现个性化扩展。 |
更多Agent功能期待与大家共创
三、环境搭建
1. 部署本项目时所用环境
-
操作系统:Windows 64
-
LabVIEW:2018及以上 64位版本
-
AI Agent for LabVIEW工具包:>=1.17版本
2. 软件下载及安装
查看:https://blog.youkuaiyun.com/virobotics/article/details/151324436?spm=1011.2415.3001.5331
3. 配置Agent
查看:https://blog.youkuaiyun.com/virobotics/article/details/151324436?spm=1011.2415.3001.5331
四、Agent VI工具介绍
1. VI 工具的基本概念
在仪酷智能 Agent 框架中,工具(Tool) 是 Agent 的“能力扩展”。每个工具由两部分组成:
-
VI 文件(.vi) —— 实际执行逻辑的 LabVIEW 程序。
-
JSON 文件(.json) —— 描述该 VI 的元信息(输入输出、功能说明、路径等)。
Agent 通过读取这些工具的 JSON 描述文件来加载、理解并调用对应的 VI。
2. 工具文件的存放路径
在默认环境中,所有工具文件放在以下路径下:
National Instruments\LabVIEW 20xx\examples\VIRobotics\AI Agent\tools\basic_tools
如 LabVIEW2018 安装在 C 盘,则在:
C:\Program Files\National Instruments\LabVIEW 2018\examples\VIRobotics\AI Agent\tools\basic_tools
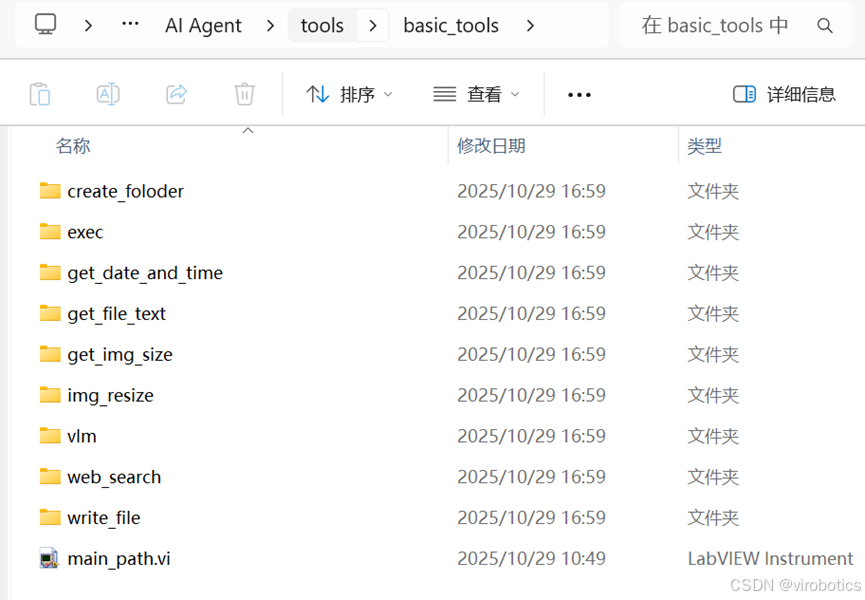
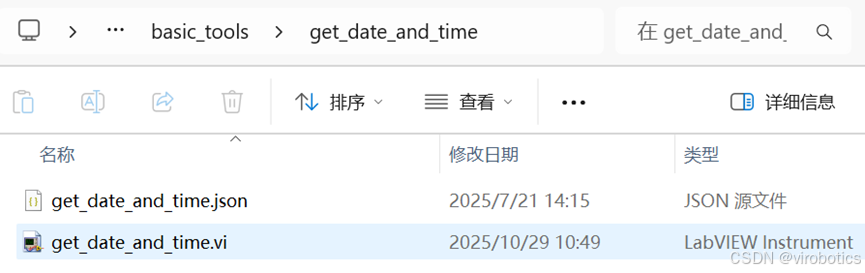
每个工具占用一个独立文件夹,其中包含:
-
一个
.vi文件(逻辑主体) -
一个
.json文件(工具定义)
五、创建VI 工具
1. 新建 VI 文件
打开 LabVIEW,新建一个 VI,编写你的功能逻辑。 在前面板中,务必保证有一个字符串输出,名字为 result。 这是智能 Agent 获取 VI 执行结果的唯一出口。
如下范例所示获取日期和时间:

-
输出控件名称:result
-
输出类型:字符串
-
内容:工具执行的最终结果
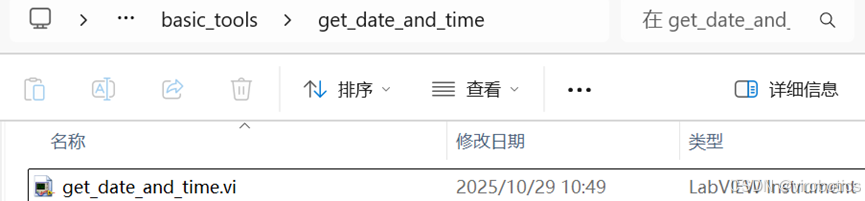
2. 保存 VI
将 VI 保存在 basic_tools 文件夹下的独立子文件夹中。 例如:
C:\Program Files\National Instruments\LabVIEW 2018\examples\VIRobotics\AI Agent\tools\basic_tools\get_date_and_time
3. 生成工具 JSON
-
接下来,为 VI 创建一个描述文件(JSON)。可以直接使用系统提供的工具界面编辑这个 JSON 文件。
路径:Tools >> VIRobotics GenAI >> Agent_VI_Editor

-
加载已经写好的 VI 工具
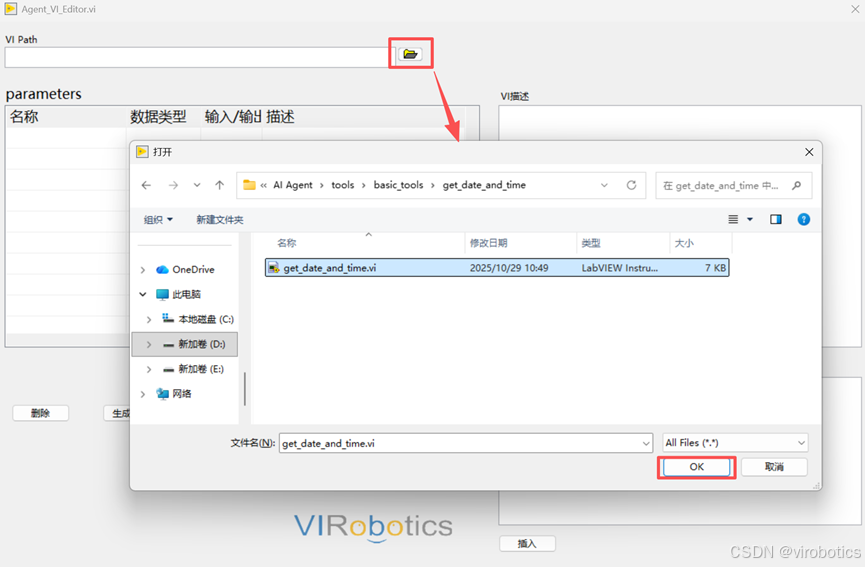
-
输入当前 VI 描述,以便让大模型知道这个 VI 做什么用

-
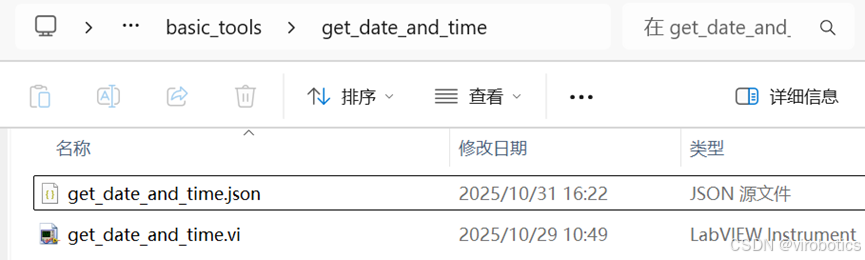
编辑完成后,在界面中点击 “生成 json” 按钮,这会自动生成可供 Agent 识别的 JSON 文件。 可以在 VI 同路径下看到生成的 JSON 文件。
六、Agent中调用写好的工具
6.1 加载工具到仪酷智能 Agent
在 Agent 中,存在一个专门的 VI 用于加载所有工具。
它会扫描工具文件夹下的所有 JSON 文件并载入。
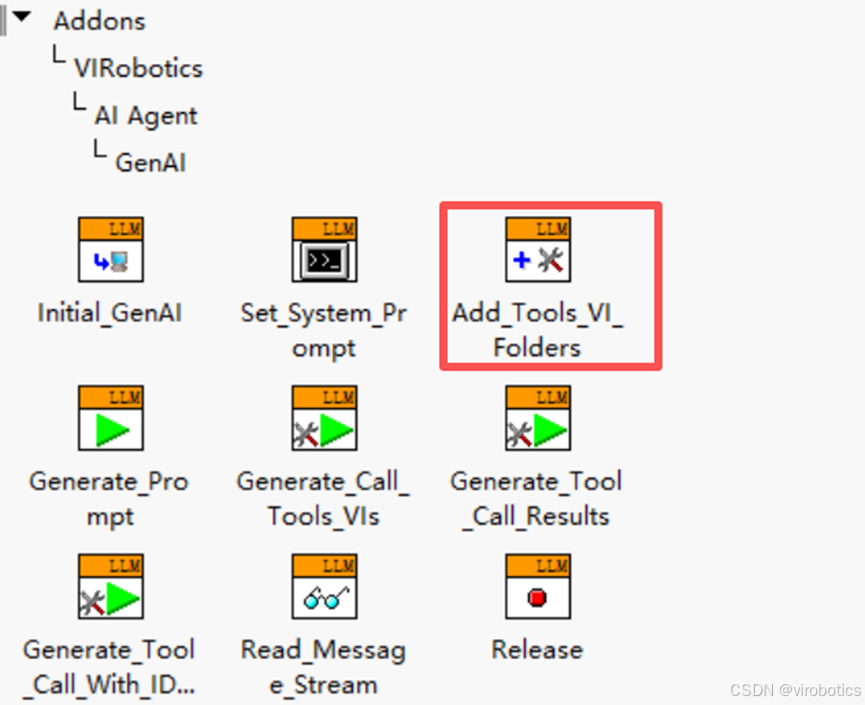
这样,Agent 就能理解:
-
工具有什么功能;
-
需要哪些输入;
-
输出是什么;
-
以及在哪里执行。
6.2 调用工具
1. 使用范例 deepseek_stream_with_tools.vi
1)打开 LabVIEW 的范例查找器(Find Example),选择模式为 Directory Structure。 导航至 VIRobotics\AI Agent\ 目录,您可以看到按模型厂商分类的范例文件夹。
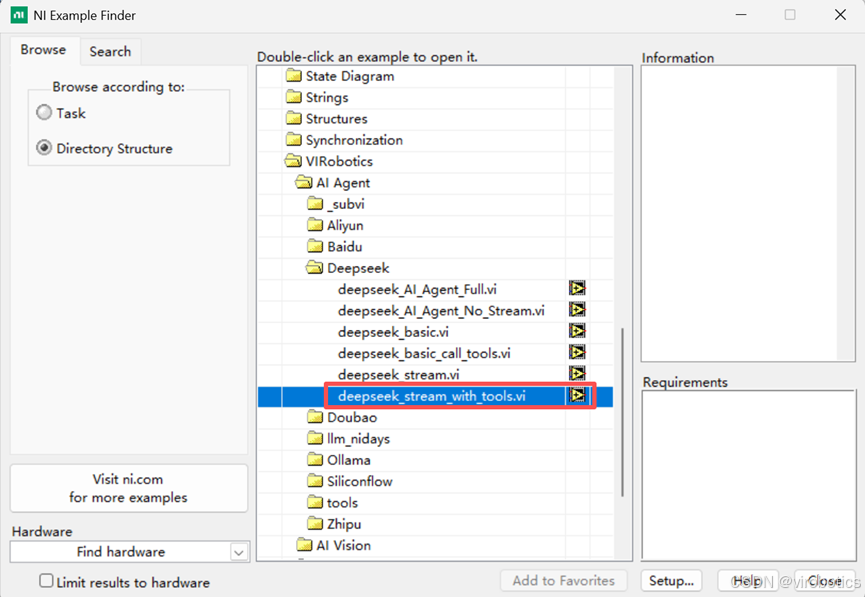
2)选择 “Deepseek”,运行范例,可以获取当前时间,即调用当前写好的查找时间的 VI 工具。
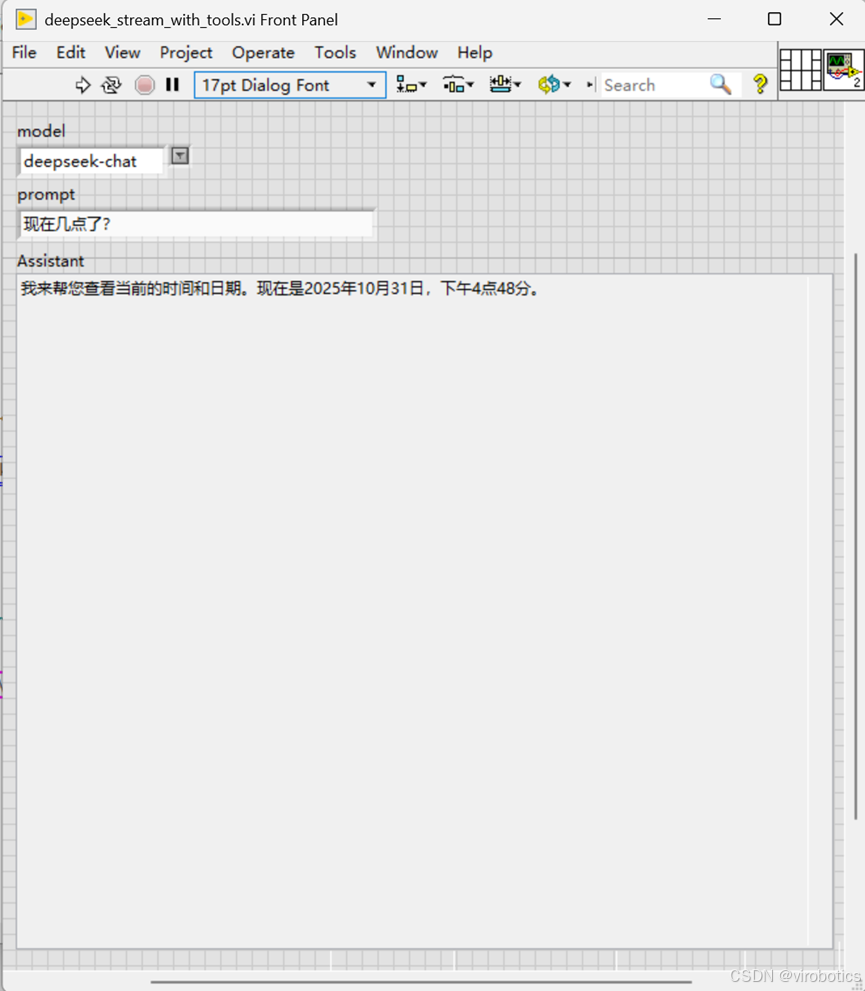
Tips: 尝试备份并删掉查找时间的 VI 工具,并再次查询时间,看看结果。
2. 由智能 Agent 自动调用
当用户向 Agent 提出问题或任务时,Agent 会根据问题内容判断是否需要调用某个工具,然后自动运行相应的 VI,获取结果并返回。
具体步骤如下:
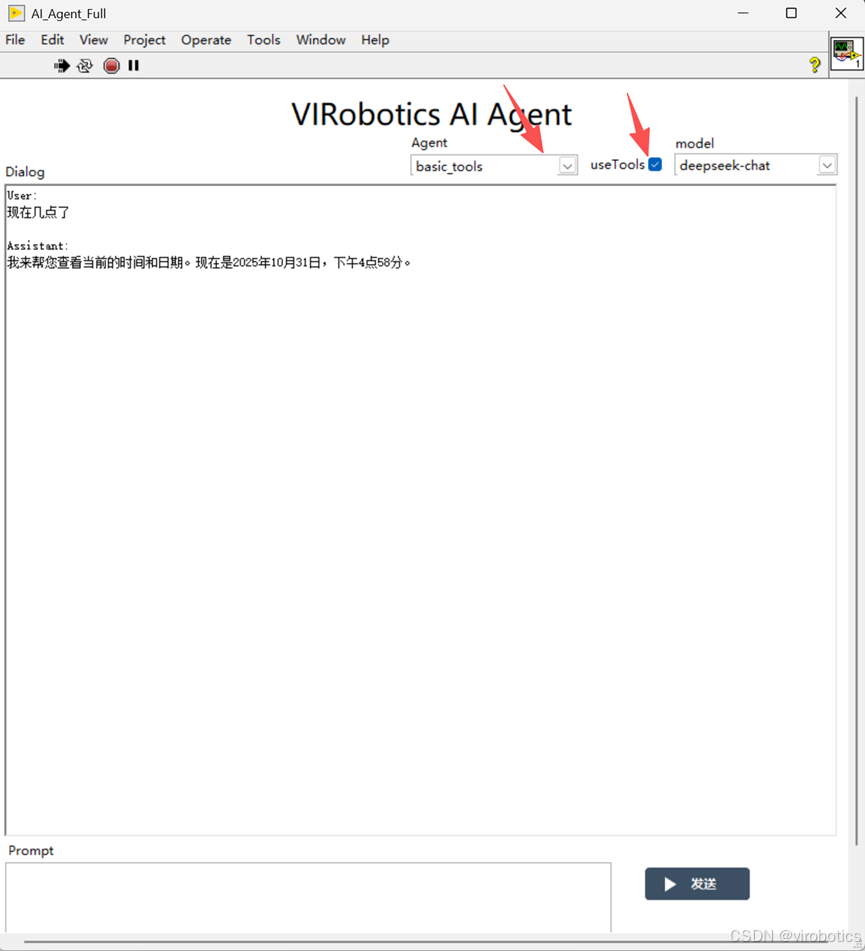
1)双击范例 deepseek_AI_Agent_Full.vi
2)运行并输入和刚刚制作工具相关的问题,如我们演示使用的是查询时间和日期的 VI,则提问当前时间。
七、其他工具的制作
其他工具也可以按照类似的办法制作。
需要注意的是:在 Editor 中填写的 “VI描述” 至关重要。
它让大模型理解工具的作用,从而在对话中正确调用。
例如:
-
分析数据采集结果
VI描述: “分析数据采集的结果,提取平均值、最大值、波形趋势等。” -
检查 VI 功能
VI描述: “读取指定 VI 的功能说明并验证输入输出是否符合标准。”
这样,当你让 Agent 分析某项数据时,它会自动选择合适的工具执行,而无需你显式调用。
总结
通过以上步骤,我们完整体验了在 仪酷智能 Agent for LabVIEW 环境下,如何从零开始创建、配置并调用自定义 VI 工具。
从理解 VI 工具的结构、编辑 JSON 描述文件,到让智能 Agent 自动识别并调用,我们可以看到——AI Agent 已不再只是一个辅助工具,而是 LabVIEW 用户的智能助手与创新引擎。
未来,仪酷智能 Agent 还将持续拓展更多模型适配、自动化能力与多智能体协作场景,助力 LabVIEW 用户在智能研发、测试与生产领域实现真正的“语言即开发”。
💡 特别提示: 我们将于 11 月开启 LabVIEW 代码生成内测申请!
感兴趣的朋友可以 加入仪酷智能交流群 664108337,第一时间体验 AI 自动生成 VI 代码的创新功能,与工程师团队一起共创智能未来。
更多内容可查看:
-
仪酷智能官网:https://www.virobotics.net/
-
微信公众号:仪酷智能科技
-
B站:仪酷智能
-
邮箱:info@virobotics.net
-
QQ群:664108337
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码))
【YOLOv5】手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别(含源码)
【YOLOv8】实战一:手把手教你使用YOLOv8实现实时目标检测
【YOLOv8】实战二:YOLOv8 OpenVINO2022版 windows部署实战
【YOLOv8】实战三:基于LabVIEW TensorRT部署YOLOv8
【YOLOv9】实战一:在 Windows 上使用LabVIEW OpenVINO工具包部署YOLOv9实现实时目标检测(含源码)
【YOLOv9】实战二:手把手教你使用TensorRT实现YOLOv9实时目标检测(含源码)
👇技术交流 · 一起学习 · 咨询分享,请联系👇


















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











