



数据库是数据存储与管理的核心载体,贯穿各类应用开发场景。本文从数据库的基础概念出发,系统梳理关系型与非关系型数据库的差异,详解 SQL 核心操作语法(增删改查),并深入拆解数据库设计三大范式,结合实际开发场景说明规范与灵活取舍的平衡,帮助开发者夯实数据库基础,掌握数据存储、操作与设计的核心技能。
数据库的定义
数据库(Database)是存储在计算机系统中的有组织的、通常是结构化的数据集合。数据库系统允许用户通过特定的方式(如查询语言)来插入、更新、删除和检索数据。
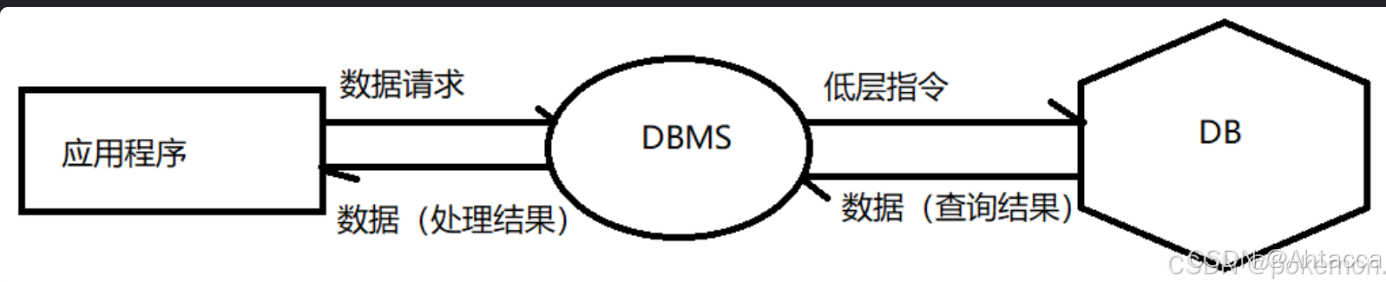
在数据库管理系统(DBMS)中,数据、表和数据库是三个层次不同的概念,它们之间有着明确的层次结构和关系
-
数据 是数据库中最小的存储单元,是表中记录的内容。
-
表 是数据库中存储数据的结构化单位,由行和列组成,每个表保存了一类相关的数据记录。
-
数据库 就是表的集合。它是以一定的组织方式存储的相互有关的数据集合
数据库管理系统
数据库管理系统(DatabaseManagementSystem,DBMS)是实现对数据库资源有效组织、管理和存取的系统软件。它在操作系统的支持下,支持用户对数据库的各项操作
DBMS 的核心功能
**数据定义:**创建和修改数据库结构,如表格、视图、索引等。
**数据操控:**执行数据的插入、更新、删除和查询操作。
事务管理:确保一系列操作(事务)的完整性和一致性。
并发控制:管理多个用户同时访问数据,防止数据冲突。
安全性管理:控制对数据的访问权限,保护数据安全。
数据备份和恢复:提供数据的备份和恢复功能,以防止数据丢失
关系型数据库(RDBMS)
数据结构:
数据以表格形式存储,每个表由行和列组成,行代表记录,列代表字段。
查询语言:
使用 SQL(结构化查询语言)进行数据操作。
特点:
支持复杂查询和事务处理,数据一致性强(ACID属性)。
适用场景:
适用于传统业务系统,如财务系统、ERP、CRM等。
示例:MySQL、PostgreSQL、Oracle、SQL Server。
ACID
是关系型数据库(如 MySQL、Oracle、SQL Server)的核心保障:
- 原子性:保证事务 “要么全成,要么全败”;
- 一致性:保证数据逻辑和规则始终有效;
- 隔离性:保证并发事务互不干扰;
- 持久性:保证已提交数据永久保存。
非关系型数据库(NoSQL)
数据结构:
支持多种数据模型,如键值对、文档、列族和图,不采用固定的表格结构。
查询语言:
没有标准的查询语言,各数据库有不同的查询方式。
特点:
高度扩展性,适合处理大量数据和高并发,通常在一致性上做出一定让步。
适用场景:
适用于大数据、实时分析、社交网络等需要灵活性和高扩展性的场景。
示例:
MongoDB(文档型)、Redis(键值型)、Cassandra(列族型)、Neo4j(图数据库)
mysql命名规则
全大写单词下划线拼接或全小写单词下划线拼接
xxx_xxx
XXX_XXX
SQL
SQL(Structured Query Language,结构化查询语言)
SQL语言主要分为以下几类:
DDL(数据定义语言):(可视化操作多)
用于创建和修改数据库对象,如数据库、表、索引等。
DML(数据操纵语言):(重要)[增删改]用于对数据库中的数据进行管理,包括插入、删除和更新记录。
DQL(数据查询语言):(重要)[查]用于从数据表中查询符合条件的记录。
DCL(数据控制语言):(数据库管理人员)[分配权限]用于设置或更改数据库用户或角色的权限,如控制访问级别和许可。
DML(数据操纵语言)
增(插入)
插入部分字段
# insert into 表名(字段1,字段2..) values('值1',值2...)
插入整条字段
# insert into 表名 values(值1,值2,...)
//一次插入多条数据
#insert into 表名(字段1,字段2..) values('值1',值2...),(值4,值3,..)
# insert into 表名 values(值1,值2,...),(值1,值2,...),(值1,值2,...)
字段 表名 必须完全与表中设置一样

改(修改)
# update 表名 set 字段 = 值 [where条件]
没有条件会修改整个字段
# 把id为3的学生名字改成李四
update user set name = '李四' where id=3
修改多个字段
#把id为6的学生 名字改成张三 年龄改成18
update user set name = '张三',age = 18 where id = 6
删(删除)
# delete from 表名 [where 条件]
没有条件会全部删除 保修表结构
# 删除id为5的数据
delete from user where id=5
# 删除多个
delete from user where id in (1,2,3,4)
软删除(逻辑删) ------>改状态
如1-表示正常 2-表示锁定
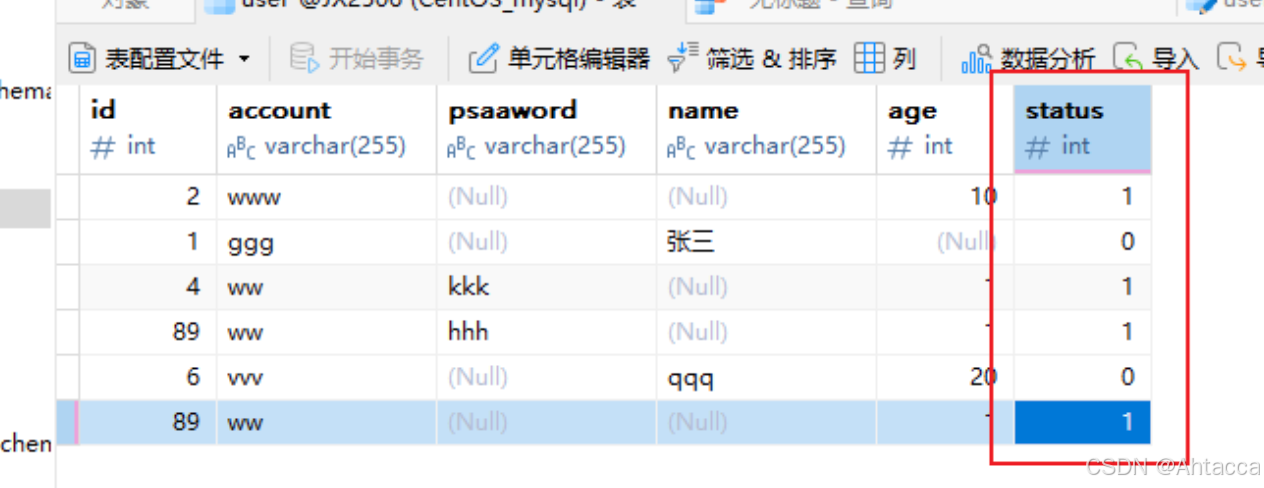
硬删除(物理删除)----->把数据真正的删掉
DQL(数据查询语言)
查(查询)
#select 字段 from 表名 [where 条件]
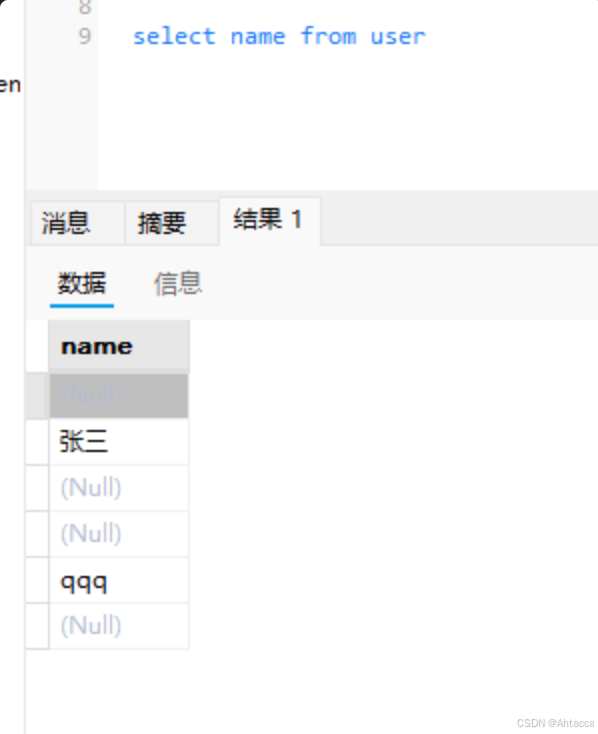
查询部分字段
select name , account from user
查询所有字段
select * from user
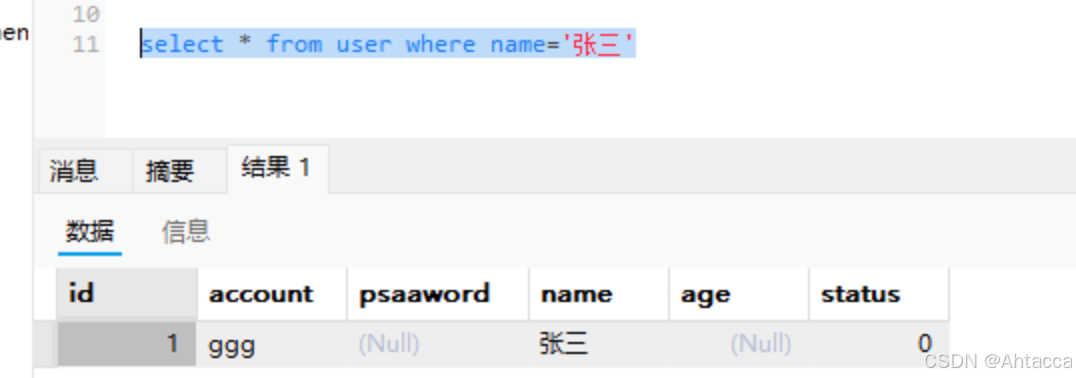
查询id为6的信息
select * from user where id = 6
查询年龄20以上30一下的信息
select * from user where age>20 and age<30
查询年龄大于20或名字是老六的
select * from user where name='老六' || age>20
查询多个
SELECT * FROM student WHERE sid='S_1001' OR sid = 'S_1002' OR sid = 'S_1003'
SELECT * FROM student WHERE sid IN ('S_1001', 'S_1002', 'S_1003')
SELECT * FROM student WHERE sid NOT IN ('S_1001', 'S_1002', 'S_1003')
查询为null的
-- 查询 age 为 NULL 的记录
SELECT * FROM student WHERE age IS NULL;
-- 如果想查询 age 不为 NULL 的记录,则使用:
-- SELECT * FROM student WHERE age IS NOT NULL;
模糊查询
select 字段 from 表名 where 字段名 like ' '
# ' ' 单引号里写知道的内容 未知的用 _ 或 %
# _ :表示任意单个 %:表示任意多个
数据库三大类型
- 整数 int ===> 不加单引号
- 字符
- char (10) ==> 定长 用于身份证 手机号码 固定的
- varchar (10) ===>动长 不固定
- 时间
- datetime

- 打勾在修改时会更新时间 不打勾只会在创建时添加时间
- 根据当前时间戳更新
(CURRENT_TIMESTAMP)
数据库约束
非空
- 必须有值

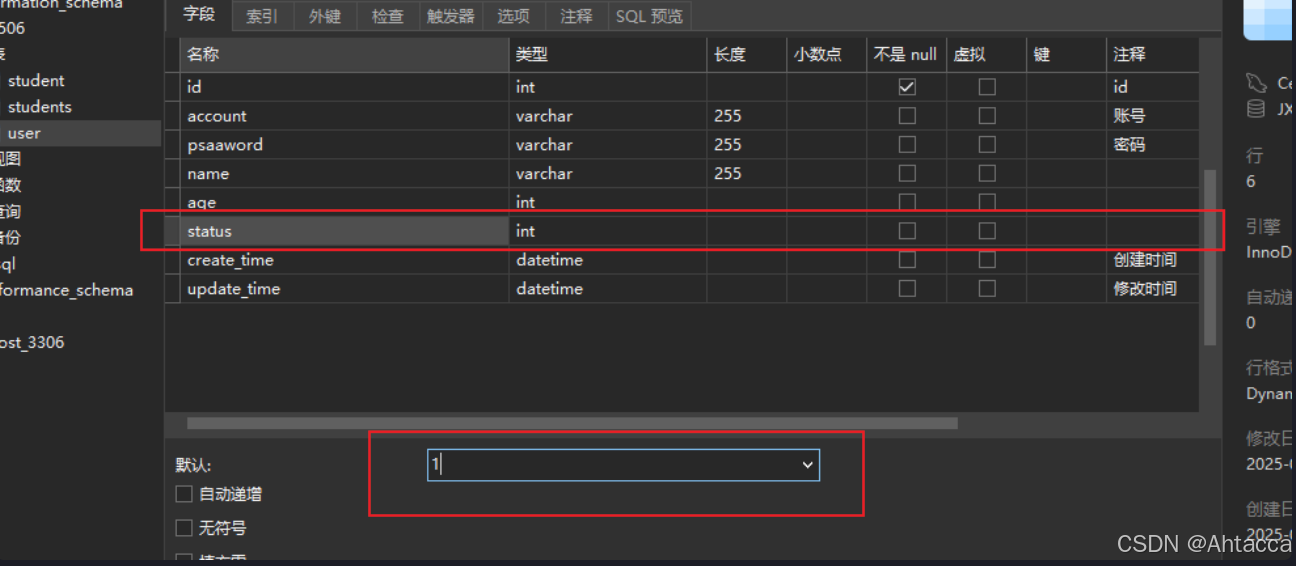
默认值(default 1)
- null时默认值为 1
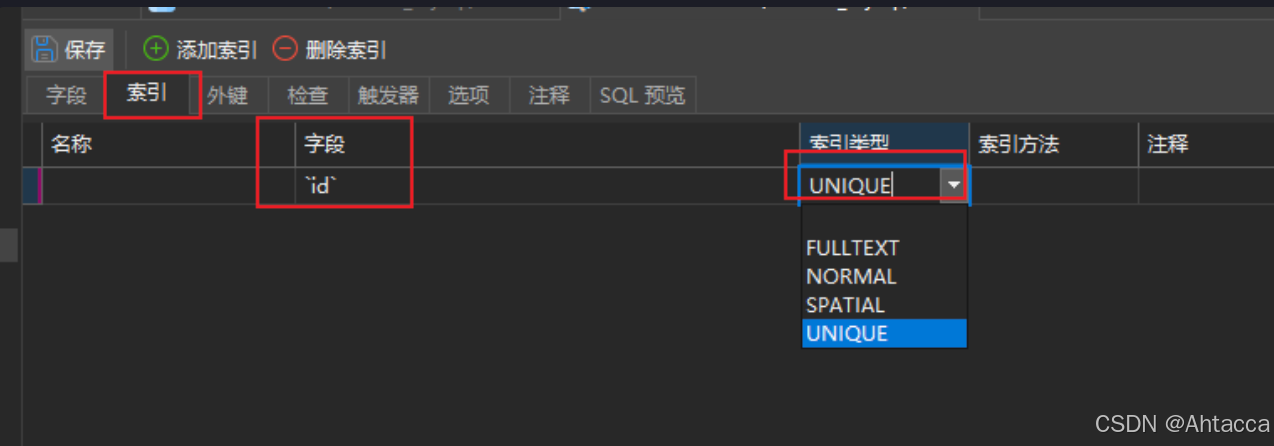
唯一
- id的值不允许重复
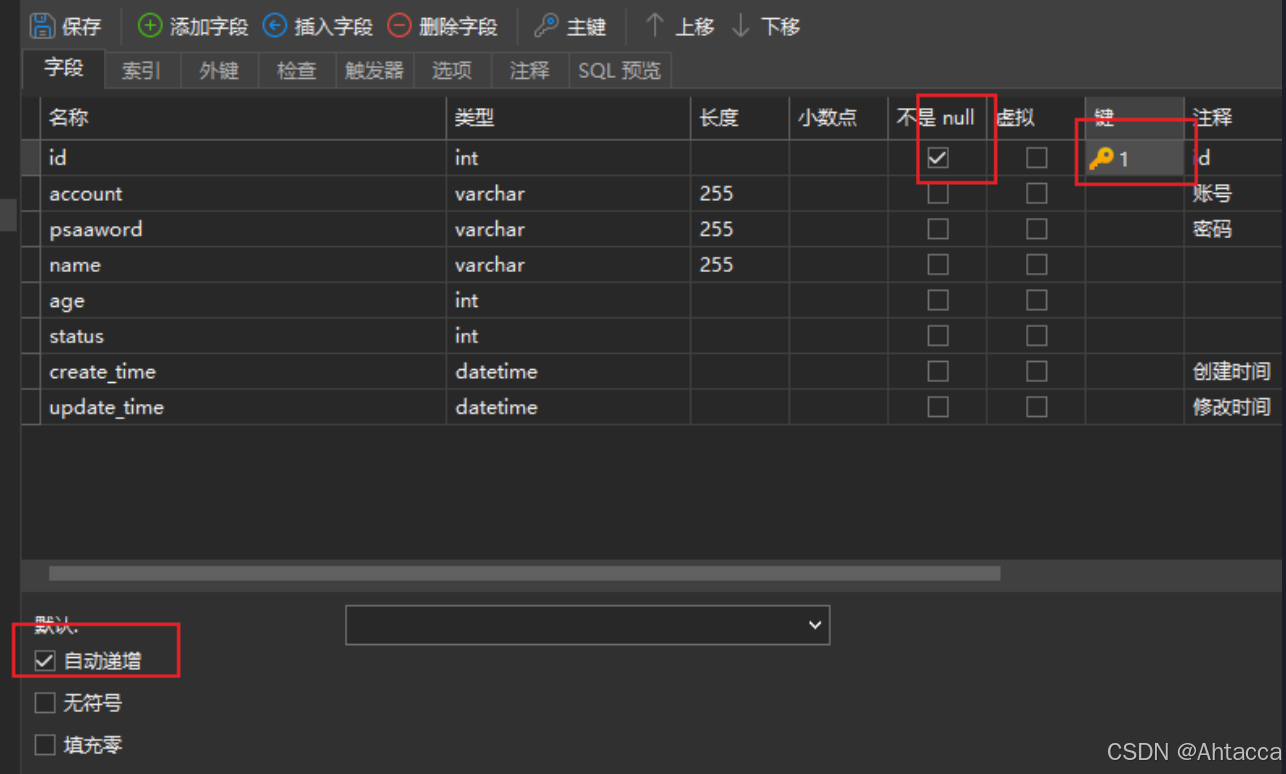
主键(primary key)
- 非空 (not null)
- 自增 (auto increase )
- 唯一 (unique)
外键
多表连接
数据库的设计
数据库的三大范式
三大范式(NF)详解
范式(Normal Form)是数据库设计的规范,目的是消除冗余和异常(插入 / 更新 / 删除异常)。三大范式是最基础且常用的,更高阶的范式(如 BCNF)在一般业务中较少用到。
1. 第一范式(1NF):字段不可再分
定义:数据表中的每个字段(列)必须是不可分割的原子值,不能包含多个值或复合结构。
反例:
在 “用户表” 中设计一个contact字段,存储 “电话,邮箱”(如 “138xxx,xxx@qq.com”),这就违反了 1NF—— 因为contact可以拆分成phone和email两个独立字段。
正例:
| user_id (主键) | username | phone | |
|---|---|---|---|
| 1 | 张三 | 138xxx | zs@qq.com |
| 2 | 李四 | 139xxx | ls@163.com |
开发场景:MyBatis 中如果字段可拆分,会导致ResultMap映射复杂,且查询时需要用字符串切割(如SUBSTRING),效率低。
2. 第二范式(2NF):消除部分依赖
前提:满足 1NF。
定义:表中所有非主键字段必须完全依赖于整个主键,而不是依赖主键的一部分(适用于联合主键的表)。
反例:
订单明细表(联合主键为order_id+product_id):
| order_id (主键) | product_id (主键) | order_date | product_name |
|---|---|---|---|
| 1001 | 2001 | 2023-10-01 | 手机 |
| 1001 | 2002 | 2023-10-01 | 耳机 |
问题:order_date(订单日期)只依赖order_id(主键的一部分),不依赖product_id,属于 “部分依赖”,违反 2NF。
导致的问题:如果订单日期改了,需要更新该订单下所有商品的记录,冗余且容易出错。
正例:拆分表
- 订单表(
order_id为主键):存储order_id、order_date等订单级信息 - 订单明细表(
order_id+product_id为联合主键):存储order_id、product_id、product_name等商品级信息
开发场景:SpringBoot 中,合理拆分后可以用@OneToMany关联订单和订单明细,MyBatis 的collection标签也能更清晰地映射一对多关系。
3. 第三范式(3NF):消除传递依赖
前提:满足 2NF。
定义:表中所有非主键字段必须直接依赖于主键,不能存在 “传递依赖”(A 依赖 B,B 依赖主键,导致 A 间接依赖主键)。
反例:
员工表(emp_id为主键):
| emp_id (主键) | emp_name | dept_id | dept_name |
|---|---|---|---|
| 101 | 王五 | D01 | 研发部 |
| 102 | 赵六 | D01 | 研发部 |
问题:dept_name(部门名称)依赖dept_id,而dept_id依赖主键emp_id,形成 “传递依赖”(dept_name间接依赖emp_id),违反 3NF。
导致的问题:如果研发部改名为 “技术部”,所有该部门的员工记录都要改,冗余且易出错。
正例:拆分表
- 员工表:
emp_id、emp_name、dept_id(关联部门表) - 部门表:
dept_id(主键)、dept_name
开发场景:这种设计对应 MyBatis 中的association标签(多对一映射),查询员工时可以通过dept_id关联查询部门名称,避免数据冗余。
范式的 “度”:不是越严格越好
三大范式是设计指导,但实际开发中不必盲目追求最高范式,有时为了查询效率会适当 “反范式化”(允许少量冗余)。
例如:订单表中冗余user_name(用户姓名)
- 违反 3NF(
user_name依赖user_id,user_id依赖订单主键) - 但好处是:查询订单时无需关联用户表,直接获取用户名,提高效率(适合订单列表这种高频查询场景)。

















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









