




 文章介绍了在使用CUDA和TensorRT进行深度学习推理时遇到的速度变慢问题,特别是在Yolov5模型下。作者分析了因摄像头速度跟不上推理速度导致的问题,并提供了通过Nvidia控制面板设置高性能模式和调整显卡频率来提升推理效率的解决方案。此外,还提到了相机FPS对推理速度的影响。
文章介绍了在使用CUDA和TensorRT进行深度学习推理时遇到的速度变慢问题,特别是在Yolov5模型下。作者分析了因摄像头速度跟不上推理速度导致的问题,并提供了通过Nvidia控制面板设置高性能模式和调整显卡频率来提升推理效率的解决方案。此外,还提到了相机FPS对推理速度的影响。
前言
各位朋友,好久不见,距离上一次更博已经过去三月有余。这段时间里博主基于LabVIEW探索开发了一些工具包,包括OpenVIN工具包、TensoRT工具包以及一键训练工具包,这几天会整理一下分享给大家,今天要和大家分享的是好多朋友私信问我的深度学习推理过程中cuda或tensorRT变慢的问题。
一、场景再现
场景一
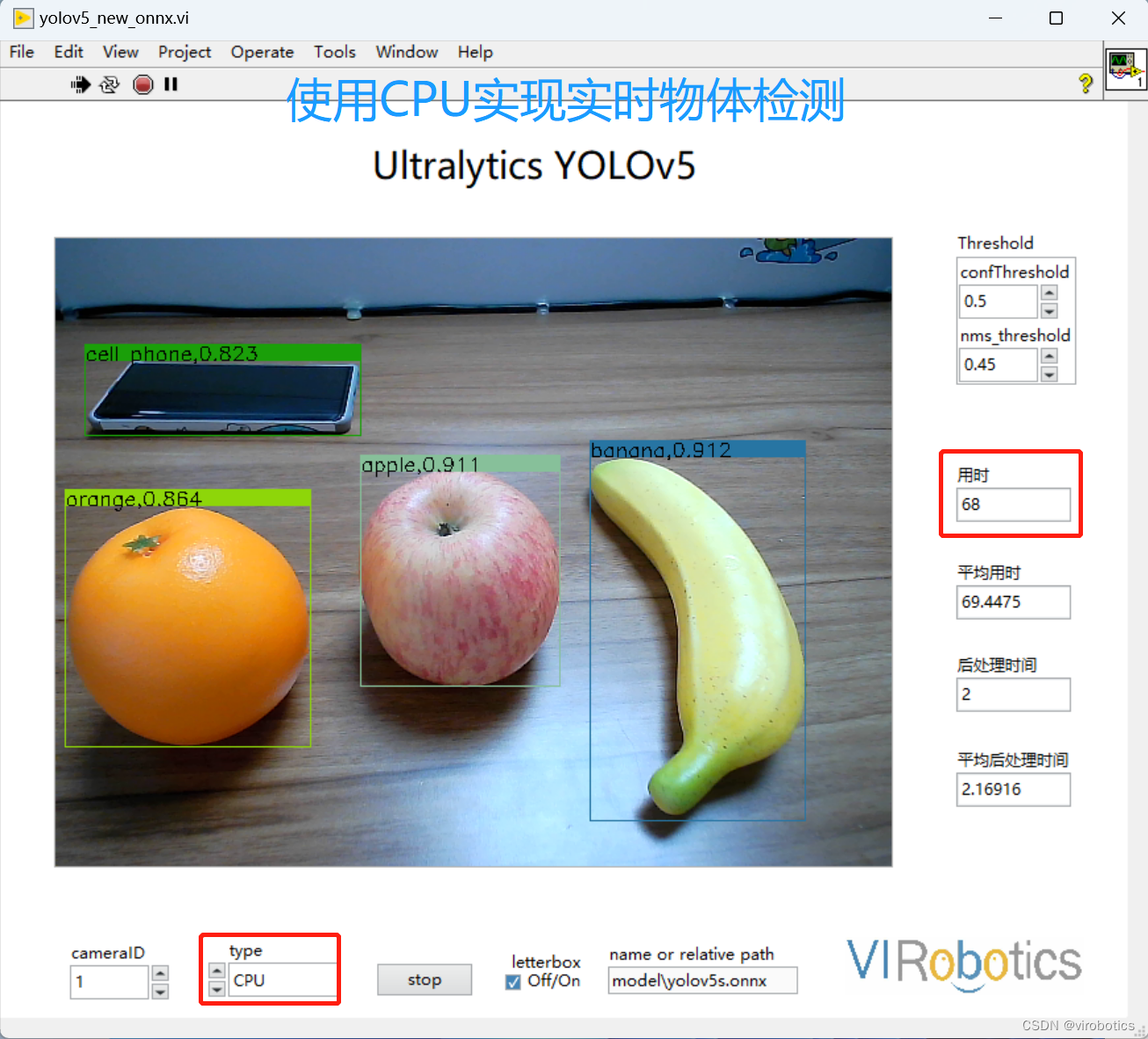
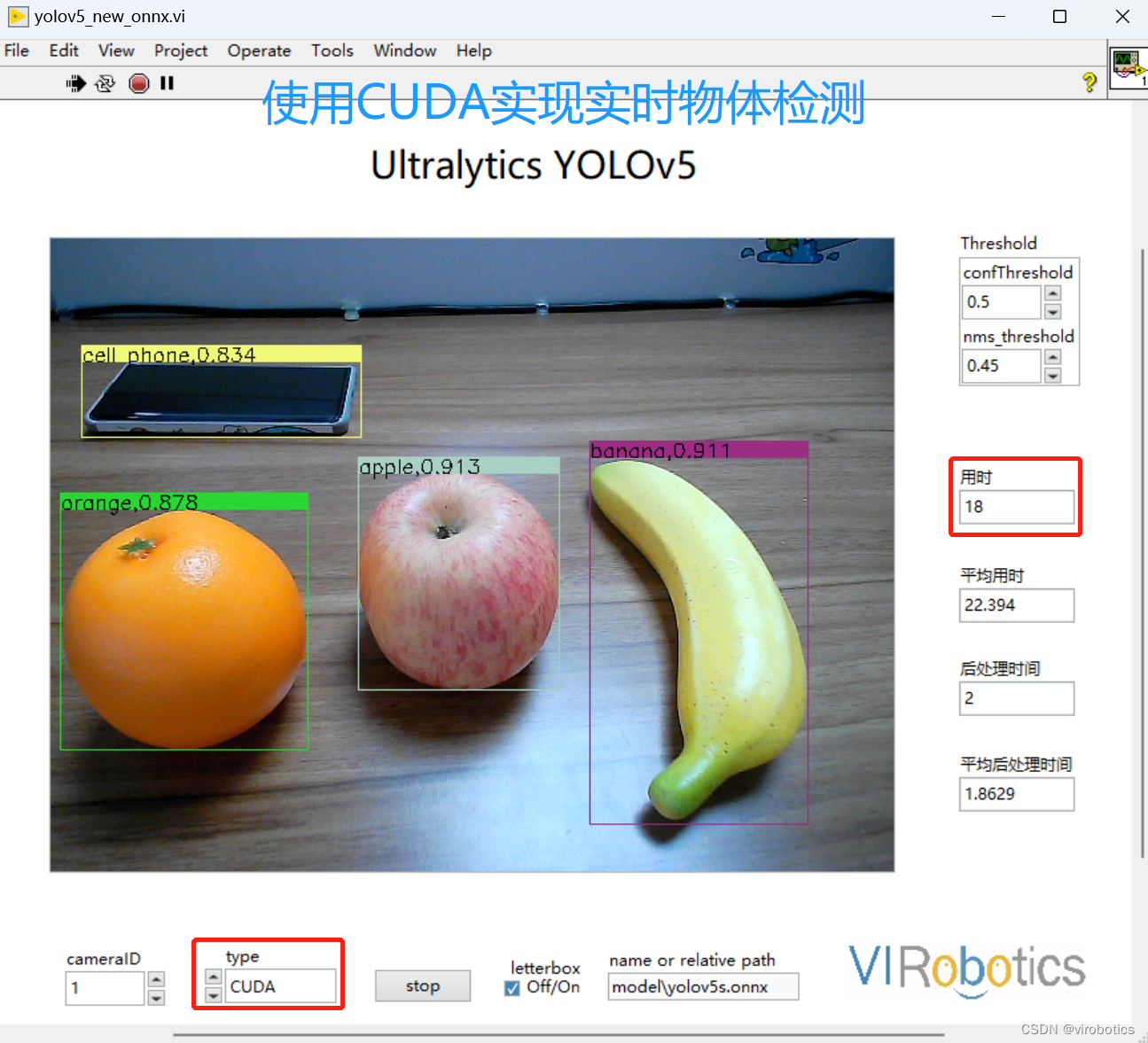
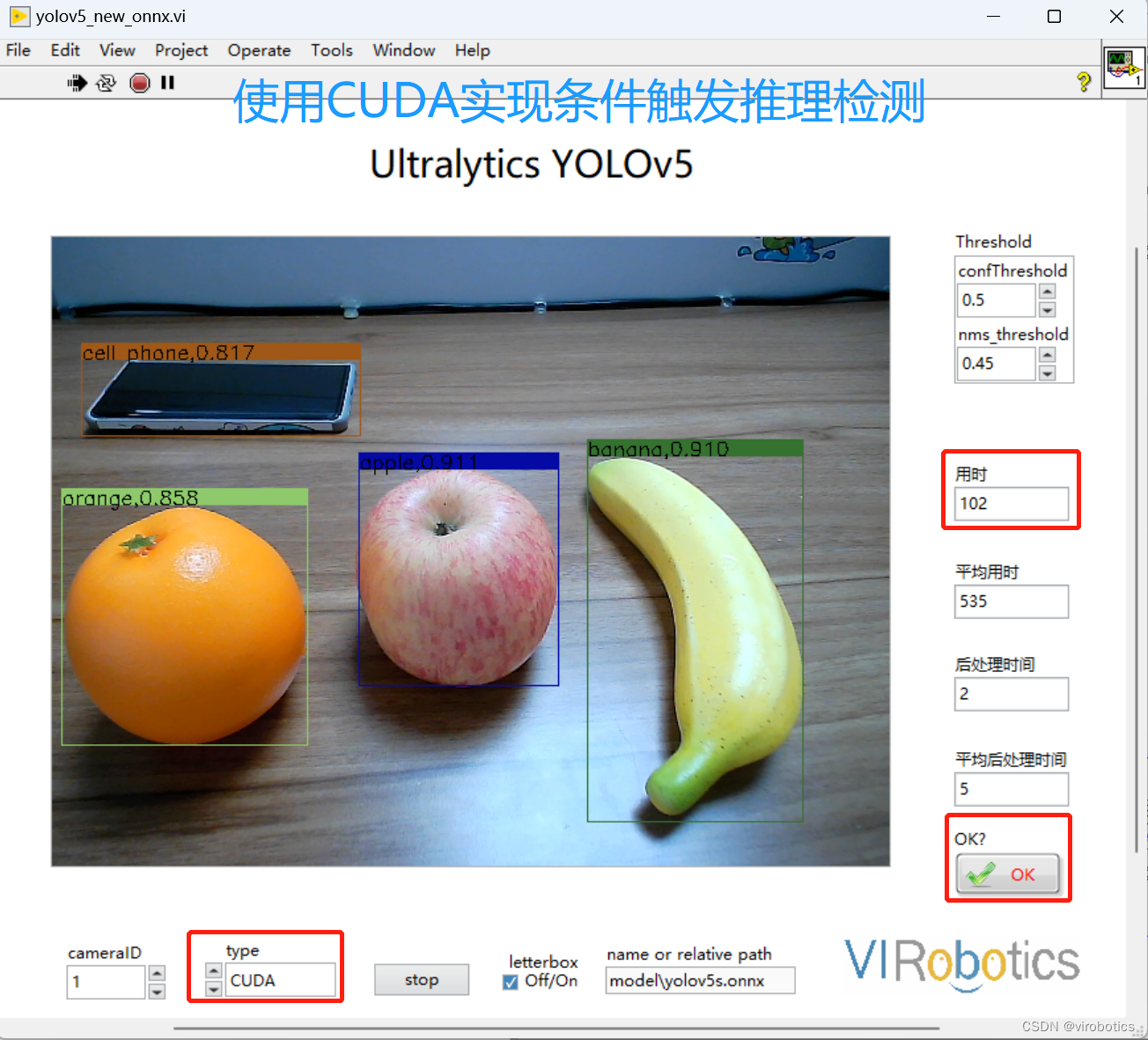
以yolov5为例,为了节省开销,深度学习模型导入后,相机实时抓图,条件触发推理检测,也就是只有满足某个条件,才进行推理检测。在该场景下,发现使用CUDA加速推理检测的速度竟然比使用CPU实时循环抓图检测的速度都要慢,如下图所示,分别为使用CPU实现加速推理,使用CUDA实现加速推理,条件触发使用CUDA实现加速推理所用时间(同一个程序在同一个电脑检测相同场景物体)。
- 使用CPU实现实时物体检测,检测一帧大概68ms
- 使用CUDA实现实时物体检测,检测一帧大概18ms
- 使用CUDA实现实时物体检测,但选择条件触发进行检测,检测一帧大概100多ms
场景二
依旧以yolov5为例,同一个程序在同一台电脑上使用同一个相机相机进行实时采集并检测的过程中,相机设置不同FPS,CUDA或者TensoRT加速推理的速度不同,相机FPS越高,CUDA或者TensoRT推理的速度越快,相反,相机FPS越低,CUDA或者TensoRT推理的速度越慢。
二、原因分析
摄像头速度或者采集到的图片输送速度跟不上推理速度,导致cuda"偷懒",从而使得整个推理变慢。那我们该如何解决cuda或tensorRT推理速度变慢呢?设置”显卡频率“。
三、解决办法
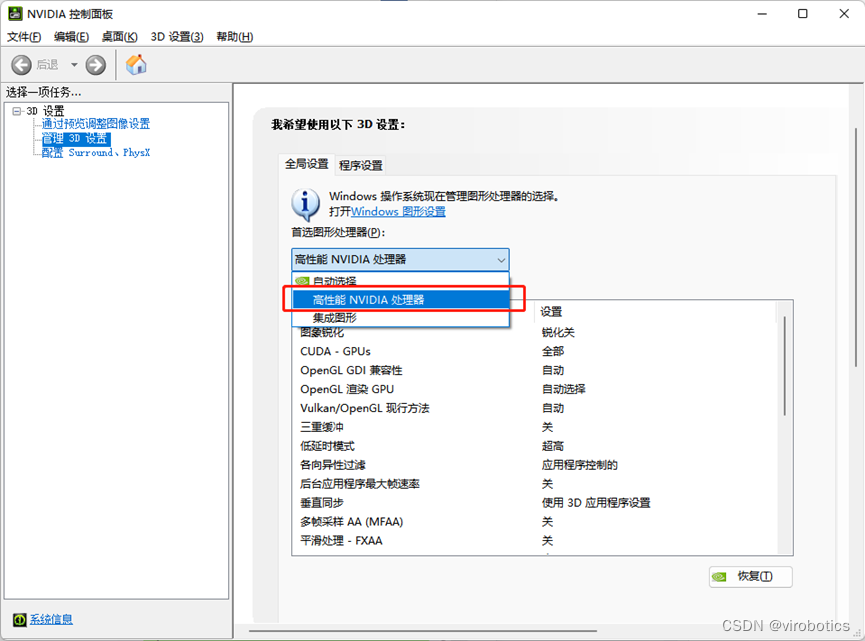
第1步:打开Nvidia控制面板,首选图形处理器里面选“高性能Nvidia处理器”
第2步:低延时模式选“超高”,“电源管理模式”选“最高性能优先”。
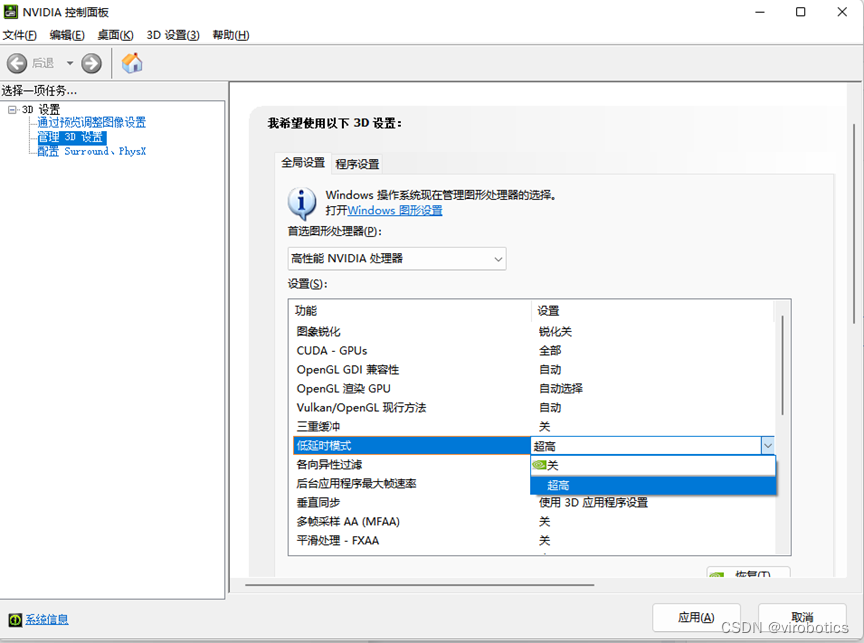
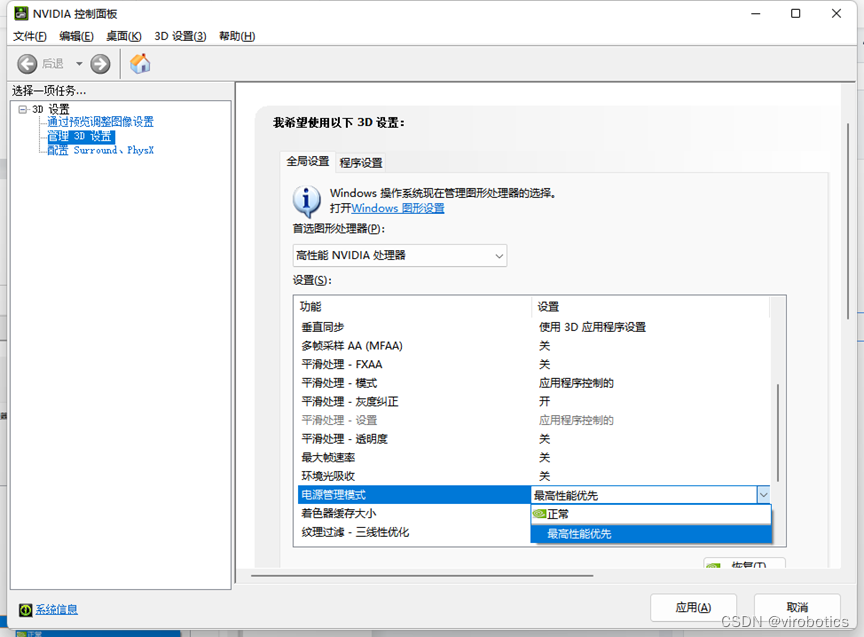
第3步:管理员模式打开cmd,输入nvidia-smi -q -d SUPPORTED_CLOCKS
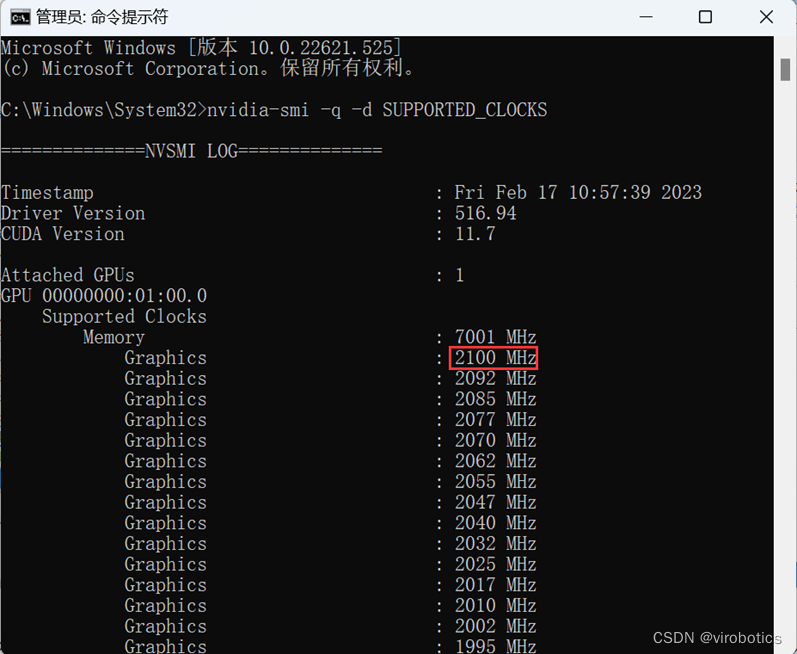
第4步:nvidia-smi -lgc "显卡频率”,其中显卡频率设置为第一步中获取的最大值,如博主电脑显卡频率最大值为2100,则输入如下:

第5步:重启电脑,打开相关LabVIEW程序,即可解决上述所说的深度学习推理过程cuda或tensorRT推理速度变慢
注:如要恢复原来状态,cmd里输入:nvidia-smi -rgc,nvidia控制面板的选项调整到原来状态并重启电脑!
总结
以上就是今天要给大家分享的内容。如果有问题可以在评论区里讨论。觉得内容不错,可点赞收藏哦,如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群。
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏




















 2187
2187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











