







 超级会员免费看
超级会员免费看
 本文介绍了RAG(检索增强生成)如何克服大型语言模型的知识限制,通过整合外部数据来提升上下文理解。RAG利用外部数据源,通过检索器和生成器的结合,改善了幻觉和知识截止问题。LangChain是一个用于构建大型语言模型应用的开源框架,简化了RAG的工作流程,包括文档加载、文本嵌入和向量存储等组件。通过LangChain和Hugging Face,开发者可以更高效地实现信息检索和模型增强。
本文介绍了RAG(检索增强生成)如何克服大型语言模型的知识限制,通过整合外部数据来提升上下文理解。RAG利用外部数据源,通过检索器和生成器的结合,改善了幻觉和知识截止问题。LangChain是一个用于构建大型语言模型应用的开源框架,简化了RAG的工作流程,包括文档加载、文本嵌入和向量存储等组件。通过LangChain和Hugging Face,开发者可以更高效地实现信息检索和模型增强。
Introduction 介绍
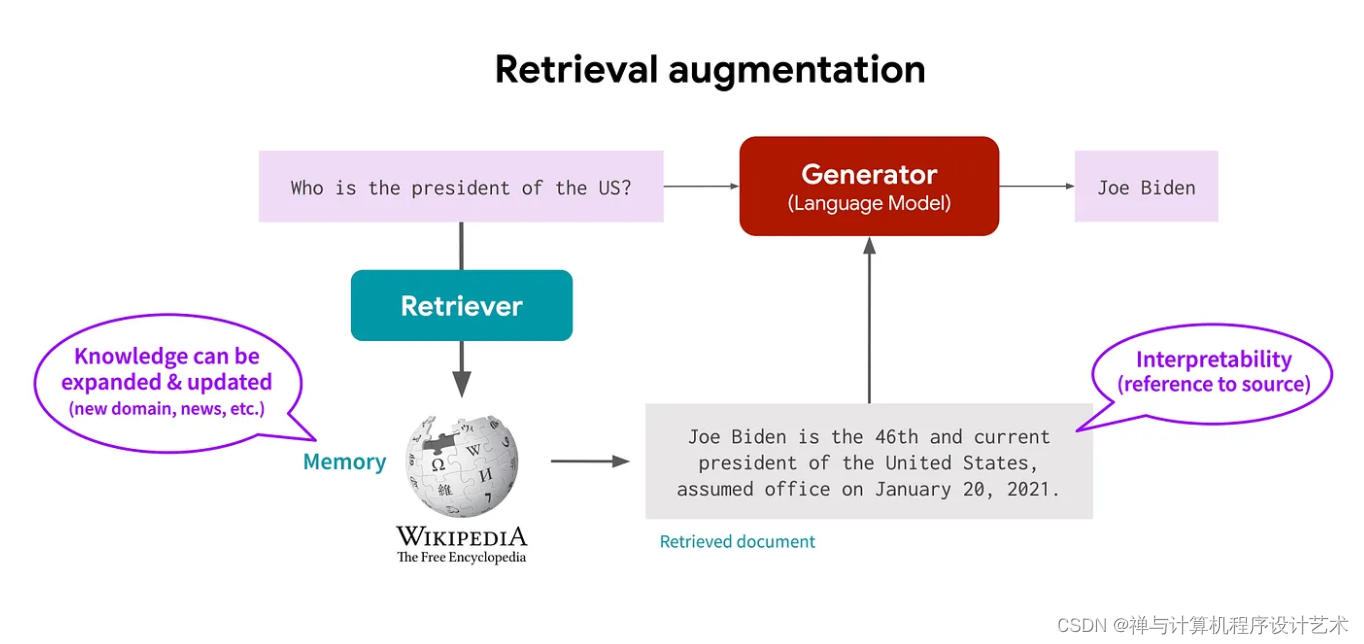
Retrieval Augmented Generation (RAG) breaks free from knowledge limitations, incorporates external data, and enhances contextual understanding.
检索增强生成(RAG)突破知识限制,整合外部数据,增强上下文理解。
Its popularity is soaring due to its efficiency in integrating external data without continuous fine-tuning.
由于其无需持续微调即可高效集成外部数据,其受欢迎程度飙升。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 3472
3472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











