



可能你会好奇,为什么VFX教程会出现ComputeShader。因为要讲的用例会涉及相关代码,原本我也只准备在教程中简单提提,一笔带过的,但因为发现代码占比还是有点大,怕只是提提的话,很多新人不理解,于是就准备花一节的时间专门讲讲这个ComputeShader。因为上一章教程中提到本章教程会继续讲怎么求解位置,但是教程中会包含ComputeShader的相关代码,所以我也正好借此机会整理一下相关知识,并把本要讲解的位置问题移到下一章。
ComputeShader(以下简称CS)可能是你在Unity最少见的一类Shader了,它运行在GPU的常规渲染管线之外。并且可用于大规模并行GPGPU(解释:General-purpose computing on graphics processing units,是利用GPU来计算原本由CPU处理的通用计算任务。这些通用计算任务通常与图形处理没有任何关系。由于现代GPU有强大的并行处理能力和可编程流水线,令GPU也可以处理非图形数据。特别是在面对单指令流多数据流(SIMD)且数据处理的运算量远大于数据调度和传输的需要时,通用GPU在性能上大大超越了传统的CPU应用程序。)算法,或者加速部分游戏渲染。CS是通过HLSL设计实现的,风格相似,如果你对CS感兴趣,可以多学习 DirectCompute、 OpenGL Compute、CUDA 或 OpenCL相关知识,这些都是当前最流行的几款用于大规模并行运算的库。CS充分利用当下GPU高并发的特性,与VFX一样,都是在GPU上处理运算。所以通过CS可以更好的控制VFX的值。
官方VFX教程里面有一篇讲美女与野兽变换的
示例教程
(这个app里面可以找到)。我原模原样的照着教程做了一遍,示例中,变换的时候,粒子的初始位置是可以跟随模型的动作变化而变化的,其原理是通过代码将模型的网格顶点位置数据写到一个只有一维的Texture2D中(高度为1的Texture2D),然后在模型召唤变化的时候不断刷新该Texture2D的值,并将其不断的传输到VFX中去,从而达到刷新位置的效果。但是众所周知,Texture2D是运行在CPU上的,传入到VFX中去后,系统再将数据传输到GPU的显存中去来达到更新VFX的数据的效果。而用VFX的时候最应该注意的就是尽可能减少CPU的操作,以及分配内存等耗时的问题。再加上模型的顶点数量根据模型精细程度不同和区别很大,小则几百,大则上万。示例中的2个模型的顶点数量一个八千多,另一个接近一万。实时创建刷新Texture2D的方法我认为是非常不可取的,从性能角度上看很差,于是有了这篇文章。
这个翻译过来的官方教程其实槽点很多。我估计翻译的这个人自己应该是没有亲自做它翻译过来的工程的,只是简单翻译了一下。因为教程中,代码很多对应的地方不对,或者说冗余。并且真的就只是个demo,这个demo你跑几次后你的内存就要炸了,它里面启用召唤的时候实时生成mesh,并且不带释放的。再加上刚才说的,它使用的这个刷新数据的办法,效率很低,总体来说只是完成了功能而已。当然,说这些不是说你不用看这个教程了,其实里面可以学习的东西还是很多的,可以学习它里面粒子的运行轨迹等等,大家还是可以把示例下载下来,我这里只是说一下自己的心得,各位学习的时候可以稍加注意。
回到主题,怎么创建CS。和创建其他Shader一样,右键Create->Shader->ComputeShader。然后双击你会看到如图: 这是最原始的CS,我添加些许代码,以方便讲解,变成以下图示: 第一行注释已经讲明,#pragma kernel 告诉需要编译的函数,原始文件就一个,当然你可以在一个文件中写很多个kernel。
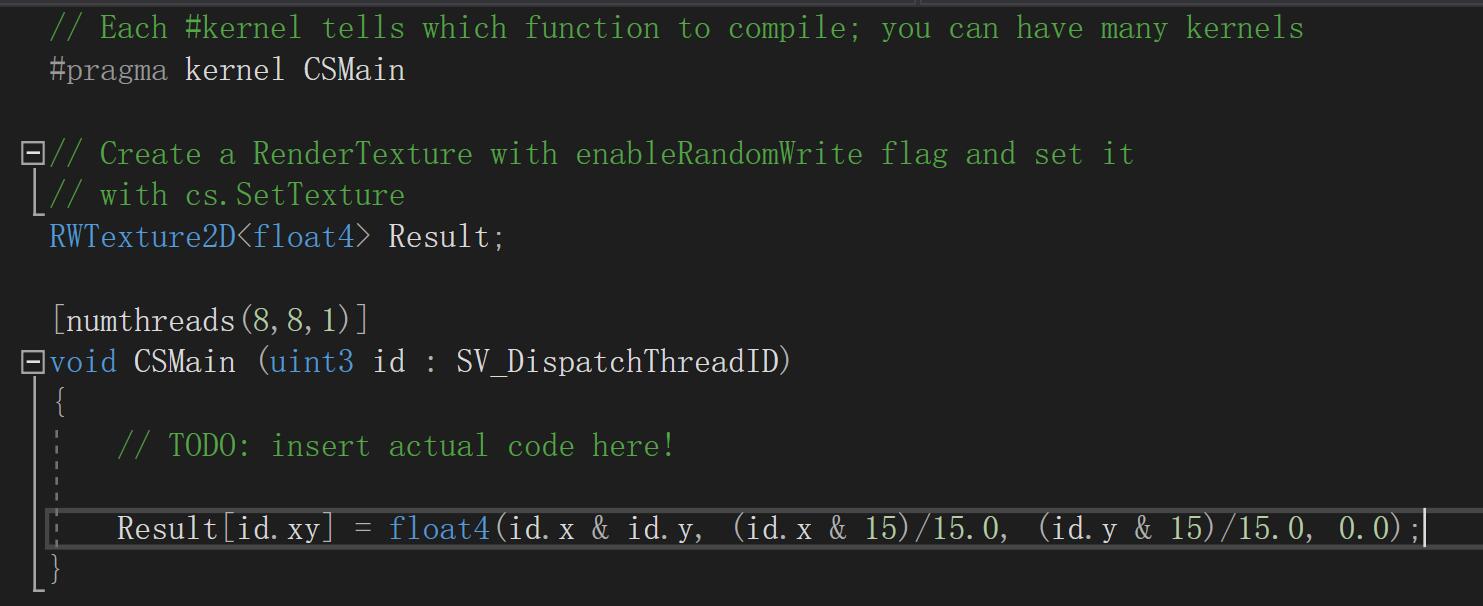
RWTexture2D<float4> Result。上面注释也已经写明,这个是和RenderTexture相关联的,并且会被当做输出的结果值。前面RW是Read和Write的缩写,代表可读写,如果不加RW,则代表只读。这里还要介绍一下RWStructuredBuffer<Data>,这里Data可以是个结构体,也可以填写基本类型,比如float等等。它通常用来接收CPU端传来的数据,以供主函数来计算用的,前缀也可以加RW,含义同上。
【numthreads】是你想要运行在GPU上线程块中线程的数量。大家应该都清楚,CPU的线程数量和GPU没法比,现在市面上大部分用户的PC的CPU最大并行线程数不过十几,而GPU则上千。但是CPU的线程可以处理相当复杂的运算,这是GPU做不到的,GPU的线程只能处理比较简单的运算法则。下图是MSDN中标出的一个线程块中线程最大的数量。 也就是根据你的Shader版本,numthreads后面的三个数之积不得大于图中的数字。当然现在绝大部分系统都支持5.0版本了。你也可以用supportsComputeShaders这个静态接口检测当前系统是否支持CS。由于低版本的shader限制第三个值为1,也或者z值本身就用不上,故将z值设置为1。在选择参数x、y的时候要根据自己处理数据的大小尺寸来决定。很多时候,开发者用CS处理图片,搞滤波、找特征点之类的,专用一个线程处理一个像素,所以x、y最好是你处理图片的相应维度的公约数。官方文档中举例说明,如果你有一个4x4的矩阵做加法运算,则可以分配4x4x1的形式,这样矩阵的每个元素分一个线程做加法运算,并且方便通过id直接获取元素在相应的矩阵上的准确位置。这个索引可以通过SV_GroupThreadID来获取到(注意,这里不是CSMain上默认的那个SV_DispatchThreadID),这2个索引的类型稍后会提到,这里先暂且略过,但是如果你在CSMain函数中需要用到SV_GroupThreadID的索引,则可以手动添加到CSMain的参数列表中去。如上面代码示例图片。

在CSMain函数中,把你传进到buffer的数据进行运算,并将最终结果给Result。
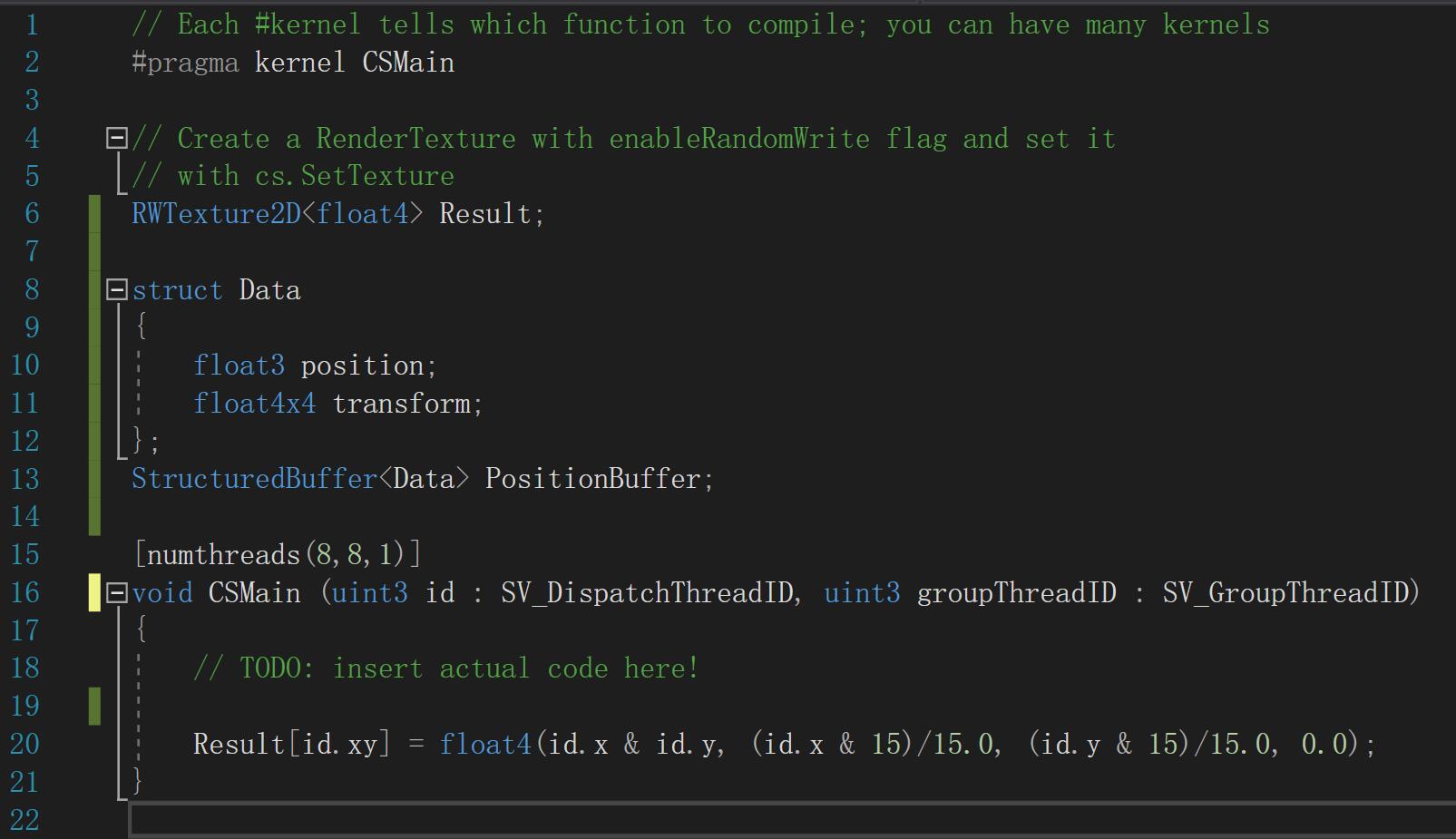
那么如何将我们的脚本和计算着色器联系起来呢? 新建一个脚本,将此脚本添加以下内容。本脚本纯属介绍接口,无实际意义,如图: 先定义好你需要传入到GPU的数据的数据结构Data,保持与CS文件中的结构体一致。
然后定义一个ComputeShader,设为Public方便将.compute拖动到Inspector上,以绑定CS文件。
下面的positionRenderTexture是在外部创建的RenderTexture文件,此处是为了下篇教程而设。其用处是与VFX文件相关联。
接下来的RenderTexture则是用于CS交互用的。
下面的positionbuffer是你想传入GPU的数据缓存。
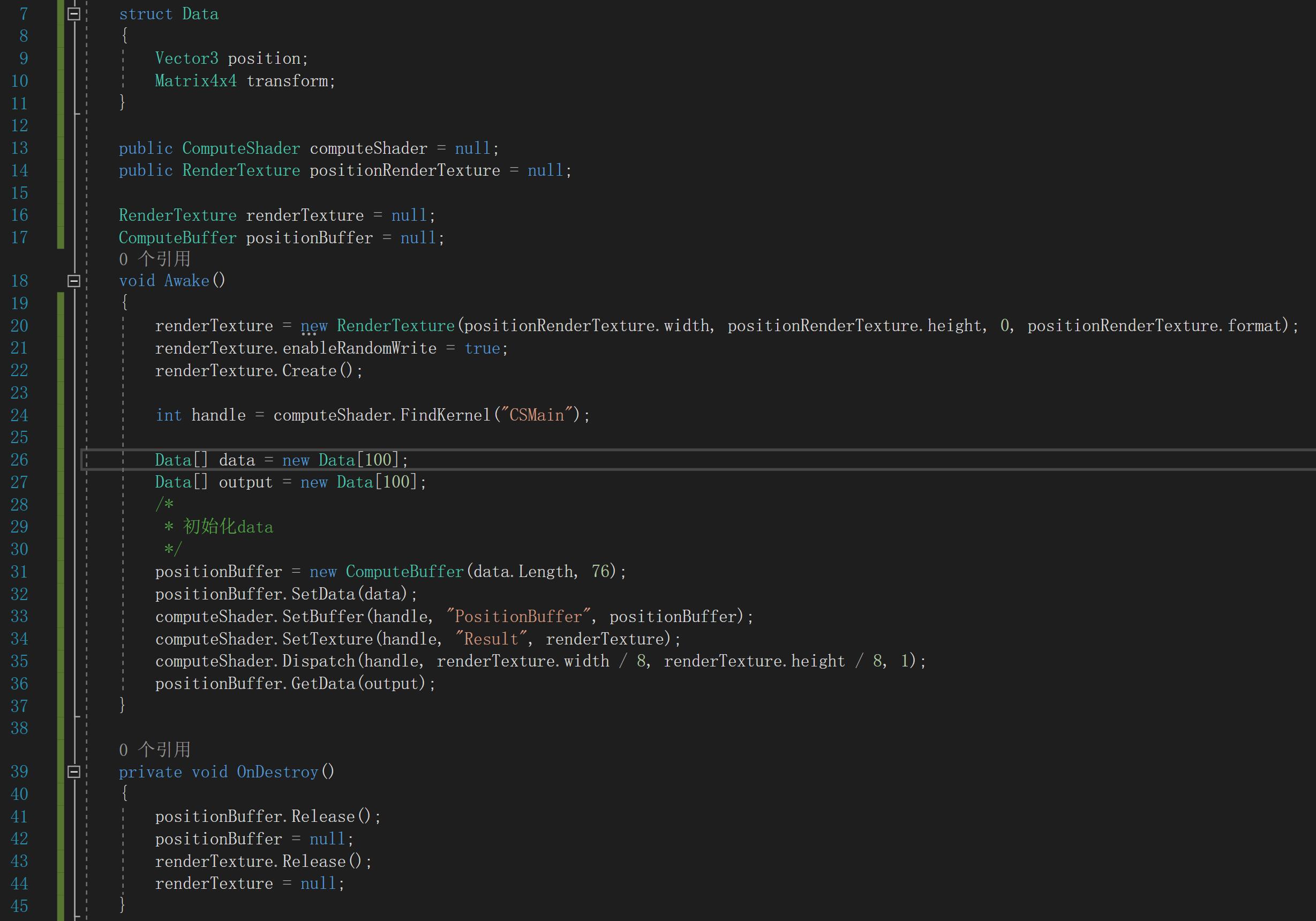
Awake中先初始化将要和CS交互的RenderTexture,并保持与VFX绑定的RenderTexture各项参数一致。
再通过FindKernel获取CS的主函数句柄。
然后再初始化你要传入的数据,这里简单说明一下。我的CS文件中并未对StructureBuffer加RW,所以输入和输出结果是一样的,因为buffer是不允许修改的,这里只是为了演示,后面还会取出值,请各位忽略一下。
再通过new ComputeBuffer创建buffer,第一个参数是你数据长度,第二个为数据大小,我这里有4x4+3=19个float,故写76。
通过buffer.setdata方法设置buffer数据。再用SetBuffer和SetTexture将数据传入到GPU的缓存。
最后Dispatch开始运行。Dispatch的第一个参数为函数句柄,后面3个数则为线程组数量,也就是包含numthreads的数量。这个参数怎么得来的呢?举个例子,假设你现在要处理一张图片,但是numthread所能定义的长宽明显是远远不够的,所以需要求出多少个在CS文件中定义的numthreads线程组来处理该图片。如果numthreads.x
dispatch.x 正好等于图片的宽,numthreads.y
dispatch.y 正好等于图片的高,那么你的CS文件的每个线程则正好覆盖该图片上的每一个像素点。这里再放一张图,让你进一步了解dispatch和numthreads的层次关系。每个Dispatch的box中包含一个numthreads线程组。 注意看红框里面的内容。这就是上面说的参数类型。
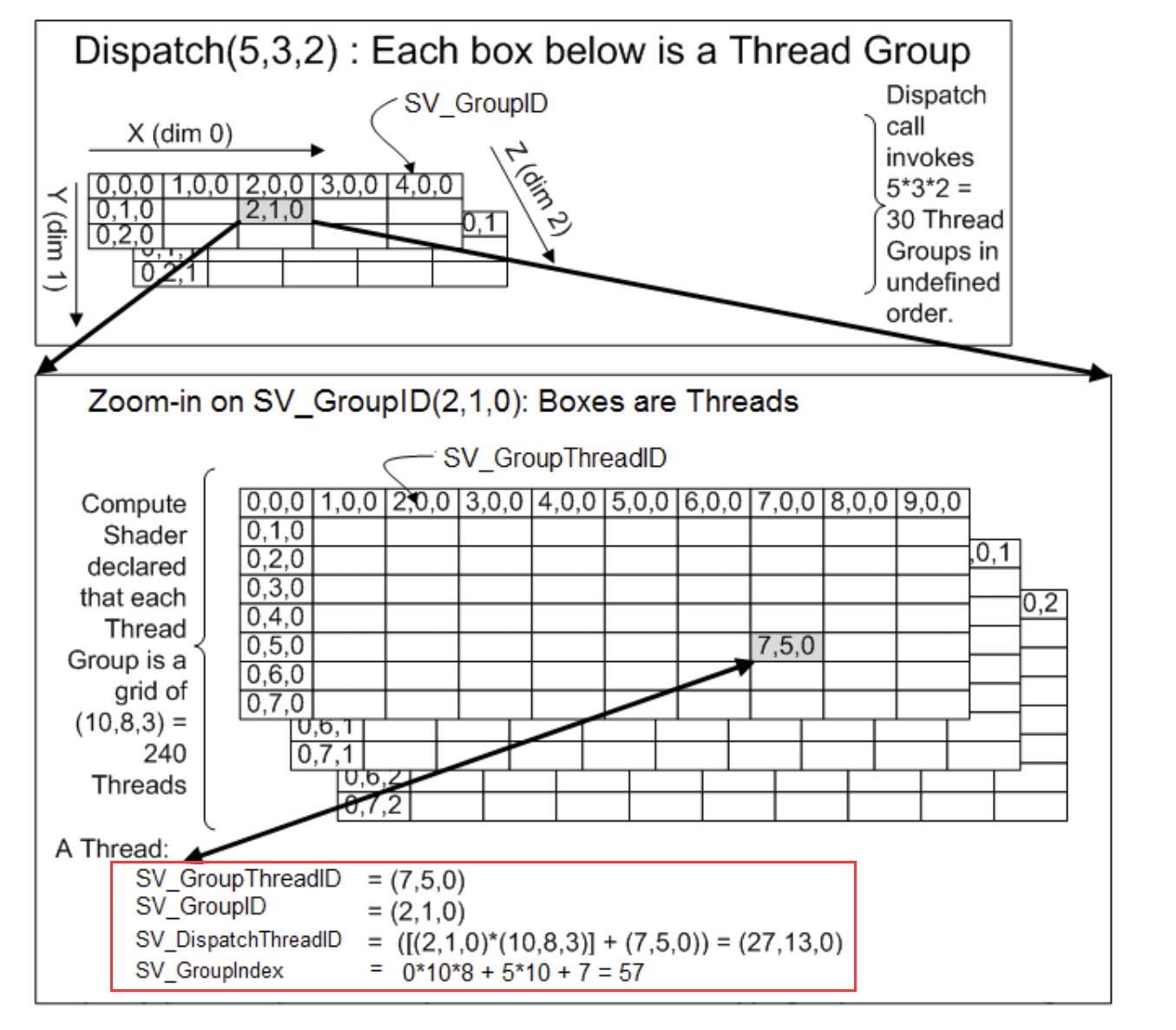
很明显SV_DispatchThreadID是你该图片上像素的唯一id号,通过这个id,你可以准确的找到那个你想要找的唯一线程的绝对位置。而SV_GroupThreadID是你numthread定义的线程组内部的相对位置,这个相对位置用于矩阵运算等,比较强调元素局部位置的功能的地方的时候就变得非常有用了。这里图中SV_GroupID也很明显,指代Dispatch内的相对位置,而SV_GroupIndex则指代当前线程相对于当前所属线程组的位置(也就是和当前线程组0,0,0的顺序间距)。
代码最后通过buffer.GetData获取数据,当然前面也说了,CS文件中Buffer的RW没设,此处仅作为API介绍之用。如果想查看RenderTexture的效果可以将其值给到材质的maintexture上,然后就可以在场景中查看了。最后在Destroy中释放资源。
好了,整一个CS的流程就讲完了,看完这篇教程,你应该能写一些简单的CS文件了,下一篇中,掌握这些知识就能看懂CS如何与VFX互相交互的了。
因为以前搞过一段时间的CUDA,虽然时间有点久远,忘得差不多了,但还是想给大家提一点性能上优化的建议: 1.GPU的大规模并行运算中,CPU向GPU传输的过程是非常耗时的,因为CPU->GPU的数据传输速率远远低于GPU->VRAM和CPU->RAM这个很多CS教程里都有提到,但是给的说法比较抽象,就是让你尽量减少数据传输。但是CUDA的官方也说了尽量减少数据传输,但是!同时强调如果你非传不可,那么尽量把小的分散的数据搞成一个大的数据包,一次性传输,而非一个个的分开传输。 2.如果数据只需要读没有写的操作的话,不要随意加RW,因为系统会对只读的变量进行优化。
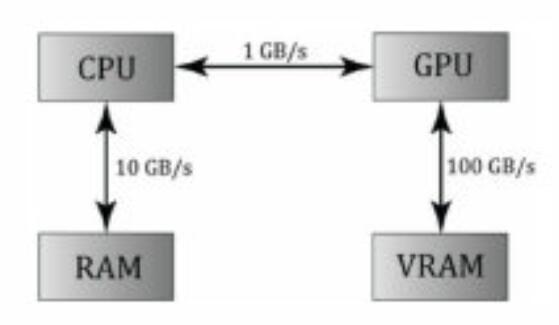
因为此文暂时没有涉及到同步等其他问题,暂时就想到这2点,以后可能会写一篇用CS搞体积雾效的文章,毕竟URP没这功能,届时会把性能优化的问题尽可能的都罗列出来,并进一步深入对CS的应用理解。

















 2476
2476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









