




目录
Chapter 14 Advanced Synchronization
Chapter 15 Advanced Synchronization:Memory Ordering
Chapter 17 Conflicting Visions of the Future
Chapter 18 Looking Forward and Back
Chapter 14 Advanced Synchronization
如果一点知识是一件危险的事情,想想你可以用大量的知识做些什么吧!
未知的
本章介绍了用于无锁算法和并行实时系统的同步技术。
尽管无锁算法在面对极端要求时可以非常有用,但它们并不是灵丹妙药。例如,如第5章末尾所指出的,在考虑无锁算法之前,您应该彻底应用分区、批处理和经过良好测试的打包弱api(参见第8章和第9章)。
但在完成所有这些之后,您仍然会发现自己需要本章中描述的高级技术。为此,第14.1节总结了迄今为止用于避免锁的技术,而第14.2节给出了非阻塞同步的简要概述。内存排序也很重要,但它保证了自己的章节,即第15章。
第二种形式的高级同步为并行实时计算提供了所需的更强的前进-进度保证,这是第14.3节的主题。
14.1 避免锁
我们面临着不可克服的机会。
沃尔特凯利
尽管锁定是生产中并行性的主力,但在许多情况下,性能、可伸缩性和实时响应都可以通过使用无锁技术得到大大改进。这种无锁技术的一个特别令人印象深刻的例子是第5.2节中描述的统计计数器,它不仅避免了锁,还避免了读-修改-写原子操作、内存障碍,甚至计数器增量的缓存丢失。我们所介绍的其他例子包括:
1.在第五章中通过许多其他计数算法的快速路径。
2.在第6.4.3节中,通过资源分配器缓存的快速路径。
3.第6.5节中的迷宫求解器。
4.第8章中的数据所有权技术。
6.第10章中的查找代码路径。
7.第13章中的许多技术。
简而言之,无锁技术非常有用,而且会被大量使用。但是,最好是将无锁技术隐藏在一个定义良好的API后面,比如inc_ count()、memblock_alloc()、rcu_read_lock()等等。这样做的原因是,无序地使用无锁技术是创建困难的bug的一个好方法。如果你认为找到和修复这些错误比避免它们更容易,请重新阅读第11章和第12章。
14.2 非阻塞性同步
只要机器能做它应该做的事,就不要担心理论。
罗伯特·海因莱因
术语非阻塞同步(NBS)[Her90]描述了八类具有不同前进进度保证的线性化算法[ACHS13],如下:
1.有界种群-无等待同步:每个线程都将在特定的有限时间内进行,这段时间与线程的数量无关[HS08]。这个级别被广泛认为甚至比有界的无等待同步更难实现。
2.无限制等待同步:每个线程都将在特定的有限时间段内取得进展[Her91]。这一水平被普遍认为是无法实现的,这可能就是为什么Alitarh等人省略了它的原因[ACHS13]。
3.无等待同步:每个线程都会在有限的时间内取得进展。
4.无锁同步:至少有一个线程将在有限的时间内取得进展。
5.无阻塞同步:在没有争议的情况下,每个线程都将在有限的时间内进行[HLM03]。
6.无冲突同步:在没有竞争的情况下,至少有一个线程将在有限的时间内取得进展[ACHS13]。
7.无饥饿同步:在没有故障的情况下,每个线程都将在有限的时间内进行进展[ACHS13]。
8.无死锁同步:在没有故障的情况下,至少有一个线程将在有限的时间内取得进展[ACHS13]。
NBS第1类是在2015年之前制定的,第2、3、4类是在20世纪90年代初首次制定的,第5类是在21世纪初首次制定的,第6类是在2013年首次制定的。最后两门课已经非正式地使用了几十年,但在2013年被重新制定。

理论上,任何并行算法都可以转换为无等待的形式,但通常有一个相对较小的子集。下一节将列出其中的一些内容。
也许最简单的NBS算法是使用获取-添加(原子_add_返回())原语对整数计数器进行原子更新。本节列出了一些常用的国家统计局算法,大致增加复杂性的顺序。
14.2.1.1 NBS集
一个简单的NBS算法实现了一个数组中的一组整数。在这里,数组索引表示可能是集合成员的值,而数组元素表示该值是否实际上是集合成员。国家统计局算法的线性标准要求读取和更新数组使用原子指令或伴随着内存障碍,但在罕见的情况下,线性并不重要,简单的易失性负载和存储足够,例如,使用READ_ONCE()和WRITE_ONCE()。
NBS集也可以使用位图来实现,其中每个可能是集合成员的每个值对应一个位。读取和更新通常必须通过原子位操作指令来执行,尽管也可以使用比较和交换(cmpxchg()或CAS)指令。
14.2.1.2 NBS计数器
在第5.2节中讨论的统计计数器算法可以被认为是无界等待的,但只能通过使用一个可爱的定义技巧,其中和被认为是近似的而不是精确的。1给定足够宽的误差范围,这是read_count()函数求和计数器的时间长度的函数,那么就不可能证明发生了任何非线性化的行为。这肯定是(如果有点人为的话)将统计计数器算法归类为有界无等待。该算法可能是Linux内核中使用最多的NBS算法。
14.2.1.3半NBS队列
另一个常见的国家统计局算法是原子队列元素排队使用原子交换指令[MS98b],其次是一个存储到下>指针的新元素的前身,如清单14.1所示,显示了userspace-RCU库实现[Des09b]。第9行更新尾指针以引用新元素,同时返回对其前身的引用,该引用存储在本地变量old_tail中。然后,第10行更新前任的->下一个指针以引用新添加的元素,最后,第11行返回关于队列最初是否为空的指示。
尽管删除单个元素需要互斥(这样删除队列就是阻塞),但可以对队列中的整个内容执行非阻塞删除。不可能的是以非阻塞的方式取消任何给定元素的队列:队列者可能在列表的第9行和第10行之间失败,因此有问题的元素只是部分排队。这导致了一个半NBS算法,其中排队是NBS,但去排队是阻塞的。尽管如此,该算法在实践中仍被大量使用,部分原因是大多数生产软件都不需要容忍任意的故障-停止错误。

14.2.1.4 NBS堆栈
清单14.2显示了LIFO推送算法,该算法拥有无锁推送和无界等待pop(lifo-push.c),形成了一个NBS堆栈。该算法的起源尚不清楚,但它在1975年授予的一项专利中被提及[BS75]。这项专利是在1973年申请的,几个月后,你的编辑看到了他的第一台电脑,它只有一个CPU。
第1-4行显示了node_t结构,它包含一个任意的值和一个指向堆栈上的下一个结构的指针,第7行显示了堆栈最顶部的指针。
list_push()函数跨越了第9-20行。第11行分配一个新节点,并且第14行将其初始化。第17行初始化新分配的节点的->的下一个指针,并且第18行尝试将其推到堆栈上。如果第19行检测到cmpxchg()失败,另一个通过循环重试。否则,新节点已被成功推入,并且此函数返回到其调用者。注意,第19行解决了其中list_push()的两个并发实例试图推到堆栈上的竞争。cmpxchg()将为其中一个成功,而为另一个失败,从而导致另一个重试,从而为堆栈上的两个节点选择任意顺序。
list_pop_all()函数跨越了第23-34行。第25行上的xchg()语句原子地删除了堆栈上的所有节点,将结果列表的头放在局部变量p中,并将顶部设置为NULL。这个原子操作会将并发调用序列化到
list_pop_all():其中一个将得到该列表,另一个将得到一个空指针,至少假设没有对list_push()的并发调用。
一个在p中获得非空列表的list_pop_all()的一个实例在跨越第27-33行的循环中处理这个列表。第28行预取->下一个指针,第30行调用当前节点上的foo()引用的函数,第31行释放当前节点,第32行为下一次通过循环设置p。
但是假设一对list_puss()实例与一个list_ pop_all()同时运行,该列表最初包含一个节点a。以下是这个场景可能发生的一种方式:
1.第一个list_push()实例推送一个新的节点B,通过第17行执行,它刚刚将一个指向节点a的指针存储到节点B的->的下一个指针中。
2.list_pop_all()实例运行完成,将顶部设置为NULL并释放节点A。
3.第二个list_push()实例运行到完成,推送一个新的节点C,但碰巧分配了过去属于节点a的内存。
4.第一个list_push()实例执行第18行执行cmpxchg()。因为新的节点C与新释放的节点A具有相同的地址,所以这个cmpxchg()会成功
并且这个list_push()实例运行到完成。
注意,尽管重用了节点A的内存,推送和弹出都成功运行。这是一个不寻常的特性:大多数数据结构需要保护,防止通常被称为ABA问题。
但是这个属性只适用于用汇编语言编写的算法。可悲的事实是,大多数语言(包括C和C++)不支持指向生命周期结束对象的指针,例如指向节点B的->下一个指针中包含的旧节点A的指针。事实上,编译器有权假设如果从两个不同的调用malloc()返回两个指针(调用它们p和q),那么这些指针不能相等。真正的编译器真的会生成常数假的响应p==q比较。指向已释放的对象,但其内存已为兼容类型的对象重新分配的指针称为僵尸指针。
许多并发应用程序通过仔细地向编译器隐藏内存分配器来避免这个问题,从而防止编译器做出不适当的假设。这种模糊的方法目前在实践中很有效,但很可能有一天会成为越来越激进的优化器的受害者。C和C++标准委员会都在进行一些工作来解决这个问题[MMS19,MMM+ 20]。同时,在编码aba容忍算法时,请非常小心。
![]()
国家统计局最常被引用的好处来自它的进步保证,它对失败阻止错误的容忍度,以及它的线性化。这些内容其中的每一个都将在下面的一节中进行讨论。
14.2.2.1国家银行前进进度保证
国家统计局的进步保证已经使许多人建议在实时系统中使用它,而国家统计局的算法实际上在许多这样的系统中使用。然而,需要注意的是,前进的进度保证在很大程度上与构成实时编程基础的进度保证正交:
1.实时前进进度保证通常有一定的相关时间,例如,“调度延迟必须小于100微秒。”相比之下,最流行的国家统计局的形式只能保证在有限的时间内取得进展,而没有明确的界限。
2.实时前进进度保证通常是概率性的,就像在软实时保证“至少99.9 %的时间下,调度延迟必须小于100微秒一样。”相比之下,国家统计局的许多进步进步保证都是无条件的。
3.实时前进进度保证通常以环境约束为条件,例如,只被尊重: (1)对于最高优先级的任务,
(2)当每个CPU花费至少有一定比例的空闲时间时,以及(3)当I/O速率低于某个指定的最大值时。相比之下,国家统计局的前进进度保证通常是无条件的,尽管最近国家统计局的工作适应了有条件的保证[ACHS13]。
4.实时程序环境的一个重要组成部分是调度器。国家统计局的算法假设一个最坏情况的恶魔调度程序,尽管不管出于什么原因,不是一个恶魔,它只是拒绝运行应用程序
包含NBS算法。相比之下,实时系统假设调度器正在尽最大努力来满足它所知道的任何调度约束,并且,在没有这些约束的情况下,它的级别最好地尊重进程优先级,并为具有相同优先级的进程提供公平的调度。非恶魔调度器允许实时程序使用比NBS更简单的算法[ACHS13,Bra11]。
5.NBS前进进度保证类假设许多底层操作是无锁的,甚至是没有等待的,而实际上这些操作在常见情况的计算机系统上是阻塞的。
6.国家统计局的前进进度保证通常是通过细分业务来实现的。例如,为了避免阻塞脱队列操作,NBS算法可以替代非阻塞轮询操作。这在理论上是很好的,但在实践中对需要一个元素及时地在队列中传播的真实程序没有帮助。
7.实时前进进度保证通常只适用于没有软件错误的情况下。相比之下,许多类的国家统计局保证即使在面对失败阻止错误时也适用。
8.国家统计局的前进进度保证类意味着线性化。相比之下,实时前进进度保证通常独立于排序约束,如线性化。
![]()
重申一下,尽管存在这些差异,但许多国家统计局的算法在实时程序中却非常有用。
14.2.2.2 NBS的基础业务
只有当NBS算法使用的底层操作也是非阻塞的时,它才能真正成为非阻塞。在数量惊人的案例中,实际情况并非如此。
例如,非阻塞算法经常分配内存。理论上,由于存在无锁内存分配器[Mic04b]。但在实践中,大多数环境最终必须从通常使用锁定的操作系统内核中获取内存。因此,除非所有需要的内存都以某种方式预先分配,否则在常见的真实计算机系统上运行时,分配内存的“非阻塞”算法将不是非阻塞的。
这一点显然也适用于执行I/O操作或以其他方式与环境交互的算法。
也许令人惊讶的是,这一点也适用于表面上的非阻塞算法,它们只执行普通加载和存储,如第14.2.1.2节中讨论的计数器。乍一看,那些可以分别编译为单个加载和存储指令的加载和存储,似乎不仅是非阻塞的,而是有限制的人口无关的自由等待。
除了加载和存储指令并不一定是快速的或确定性的。例如,如在第3章中提到的,缓存丢失可能会消耗数千个CPU周期。更糟糕的是,测量的缓存-错过延迟可能是cpu数量的函数,
如图5.1所示。我们只能合理地假设,这些延迟也取决于系统的互连的细节。此外,考虑到硬件供应商通常不会发布缓存错过延迟的上限,在现代计算机系统中假设内存引用指令实际上无需等待似乎是勇敢的。而那些有这种界限的老式系统,总体上却非常缓慢。
此外,硬件并不是内存引用指令运行缓慢的唯一来源。例如,当在典型的计算机系统上运行时,负载和存储都可能导致页面故障。这会导致调用内核内的页面故障处理程序。它可能获得锁,甚至做I/O,甚至可能使用像网络文件系统(NFS)这样的东西。所有这些都是最突出的操作。
页面故障也不是由内核引起的唯一危害。给定的CPU可能在任何时候被中断,中断处理程序可能会运行一段时间。在此期间,表面上非阻塞的用户模式算法将根本不会运行。这种情况提出了一个有趣的问题,即依赖于中断的系统调用所提供的前进进度保证,例如,模态屏障()系统调用。
事情看起来确实很黯淡,但这种算法的非阻塞特性至少可以通过多种方法来部分地弥补:
1.在裸金属上运行,禁用分页。如果您既勇敢又自信地认为您能够编写没有野生指针错误的代码,那么这种方法可能很适合您。
2.运行在非阻塞的操作系统内核上[GC96]。这样的内核非常罕见,部分原因是它们在传统上完全没有提供与基于锁的内核相比,所希望的性能和可伸缩性优势。但也许你应该写一个。
3.使用像()()这样的工具来避免页面故障,同时也确保您的程序预分配了它在启动时所需要的所有内存。这可以很好地工作,但以严重的常见情况下的内存使用不足为代价。在成本有限或功率有限的环境中,这种方法不太可能可行。
4.使用诸如Linux内核的NO_HZ_FULL无标记模式等工具[Cor13]。在Linux内核的最新版本中,这种模式将中断远离指定的cpu。然而,这可能会严重限制在部分操作中受I/O绑定的应用程序的吞吐量。
考虑到这些因素,非阻塞同步在理论上比在实践中更重要也就不足为奇了。
14.2.2.3国家统计局的细分业务
为给定的算法提供NBS排名上更高位置的一个常见技巧是用轮询API替换阻塞操作。例如,与其提供一个可靠的无锁甚至阻塞的脱队列操作,而是提供一个脱队列操作,它将以无等待的方式虚假失败,而不是表现出可怕的无锁或阻塞行为。
这在理论上很好,但在实践中一个常见的效果是仅仅将无锁或锁定行为从特定的算法移到使用该算法的倒霉代码中。在这种情况下,这个技巧不仅没有得到任何好处,而且这个技巧增加了该算法的所有用户的复杂性。
对于其他地方的并行算法,最大化一个特定的度量并不能替代仔细考虑用户的需求。
14.2.2.4 NBS故障-停止容差
在NBS算法的类别中,无等待同步(有界或其他)、无锁同步、无阻塞同步和无冲突同步即使在存在故障停止错误的情况下也能保证向前进展。一个失败停止错误可能会导致一些线程被无限期地抢占。正如我们将看到的,这种故障停止容忍特性可能很有用,但事实是,组成一组故障停止容忍机制并不一定会导致故障停止容忍系统。要了解这一点,请考虑由一系列无等待队列组成的系统,其中元素从系列中的一个队列中删除,进行处理,然后添加到下一个队列中。
如果一个线程在排队操作中被抢占,那么理论上一切都很好,因为该队列的无等待特性将保证向前进行。但是在实践中,正在处理的元素会丢失,因为无等待队列的故障停止容忍特性不会扩展到使用这些队列的代码。
然而,在一些应用程序中,国家统计局相当有限的容错能力是有用的。例如,在一些基于网络或web应用程序中,失败停止事件最终将导致重传,这将重新启动由于失败停止事件而丢失的任何工作。因此,运行此类应用程序的系统可以重载,甚至调度程序不能再提供任何合理的公平保证。相比之下,如果线程在保持锁时失败停止,则可能需要重新启动应用程序。然而,即使在这个限制范围内,国家统计局也不是万灵药,因为纯粹的调度延迟可能会出现虚假的再传输。在某些情况下,减少负载以避免排队延迟可能更有效,这也将提高调度器提供公平访问的能力,减少甚至消除失败停止事件,从而减少重试操作的数量,进而进一步减少负载。
14.2.2.5 NBS Linearizability
需要注意的是,线性化可能非常有用,特别是在分析由严格锁定和完全有序的原子操作组成的并发代码时。2此外,这种对完全有序原子操作的处理自动涵盖了简单的NBS算法。
然而,一个复杂的国家统计局算法的线性化点通常被深埋在该算法中,因此对实现该算法的一部分的库函数的用户不可见。因此,任何声称用户受益于复杂国家统计局算法的线性化性特性的主张都应该被深感怀疑[HKLP12]。
有时会断言,开发人员为其并发代码的正确性证明是必要的。然而,这样的证明是例外,而不是规则,而那些确实在制作证明的现代开发人员经常使用不依赖于线性化的现代证明技术。此外,开发人员经常使用不需要完整规范的现代证明技术
开发人员经常在事后学习他们的规范,一次学习一个错误。在第12.3章中讨论了一些这样的证明技术
人们经常断言,线性性可以很好地映射到顺序规范,这些规范比并发规范更自然[RR20]。但这一断言并不能解释我们这个高度并发的目标宇宙。这个宇宙只能被期望选择应对并发性的能力,特别是对于那些参加团队运动或监督小孩的人。此外,考虑到顺序计算的教学仍然被认为是一种黑色艺术[PBCE20],我们有理由认为并行计算的教学也处于类似的混乱状态。因此,只关注一种证明技术不太可能是一个前进的好方法。
同样,请理解线性化在许多情况下是非常有用的。不过,那把古老的工具,那把锤子也是如此。但在计算领域有一个问题,人们应该放下锤子,拿起键盘。类似地,有时线性化似乎并不是该工作的最佳工具。
值得赞扬的是,有一些线性化的倡导者意识到了它的一些缺点。也有人提出了扩展线性化性的建议,例如,间隔线性化性,它旨在处理需要非零时间来完成[CnRR18]的常见操作情况。这些建议是否会产生能够处理现代并发软件工件的理论还有待观察,特别是考虑到第12章中讨论的一些证明技术已经处理了许多现代并发软件工件。
可以创建完全非阻塞的队列[MS96],但是,这样的队列比上面概述的半nbs算法要复杂得多。这里的教训是要仔细考虑你的实际需求。放松不相关的需求通常可以大大提高其简单性、性能和可伸缩性。
最近的研究指出了另一种放松需求的重要方法。事实证明,提供公平调度的系统可以享受无等待同步的大部分好处,即使运行只提供非阻塞同步的算法,无论是在理论上[ACHS13]还是在实践中[AB13]。因为在生产中使用的大多数调度器实际上都提供了公平性,所以与更简单、更快的非无等待算法相比,更复杂的提供无等待同步的算法通常没有提供实际优势。
有趣的是,公平的日程安排只是在实践中经常得到尊重的一个有益的约束条件。其他的约束集可以允许阻塞算法来实现确定性的实时响应。例如,给定:(1)在给定优先级级别内以FIFO顺序授予的公平锁,(2)优先级反转避免(例如,优先级继承[TS95,WTS96]或优先级上限),(3)有界的线程数,(4)有界关键段持续时间,(5)有界负载,以及(6)没有故障停止错误,基于锁的应用程序可以提供确定性的响应时间[Bra11,SM04a]。这种方法当然模糊了阻塞之间的区别
以及无等待的同步,这一切都是好的。希望理论框架能够继续提高它们描述在实践中实际使用的软件的能力。
那些认为理论应该引领潮流的人指的是独一无二的彼得·丹宁,他说:“理论遵循实践”[Den15],或著名的托尼·霍尔,他说整个工程:“在工程科学的所有分支,工程在科学之前开始;事实上,没有工程的早期产品,科学家就没有什么可研究的!”[Mor07].当然,一旦有了一个合适的理论体系,利用它是明智的。然而,请注意,第一个适当的理论体系通常是一件事,而第一个被提出的理论体系则完全是另一回事。
![]()
国家统计局算法的支持者有时认为实时计算是国家统计局的重要受益者。下一节将更深入地探讨实时系统的向前发展的需求。
14.3 并行实时计算
如果应用得好,人们总是有足够的时间。
约翰沃尔夫冈冯戈特
并行实时计算是计算的一个重要新兴领域。第14.3.1节介绍了“实时计算”的一些定义,超越通常的声音,转向更有意义的标准。第14.3.2节调查了需要实时响应的应用程序的类型。第14.3.3notes节介绍了并行实时计算,并讨论了并行实时计算何时以及为什么会有用。第14.3.4gives节简要概述了如何实现并行实时系统,并分别使用第14.3.5节和第14.3.6focusing节介绍了操作系统和应用程序。最后,第14.3.7outlines节,如何决定您的应用程序是否需要实时工具。
一种传统的实时计算分类方法是分为硬实时和软实时分类,在这两种分类中,大规模庞大的硬实时应用程序永远不会错过它们的截止日期,但软弱的软实时应用程序经常错过它们的截止日期。
14.3.1.1软实时
应该很容易看到软实时定义的问题。首先,根据这个定义,任何一个软件都可以说是一个软实时应用程序:“我的应用程序在半皮秒内计算出百万点傅里叶变换。”决不!!这个系统上的时钟周期超过了300皮秒!”“啊,但这是一个软的实时应用程序!”如果术语“软实时”有任何用处,那么显然需要一些限制。

因此,我们可以说一个给定的软实时应用程序必须至少满足一定比例的时间的响应时间要求,例如,我们可以说它必须在99.9 %的时间内执行不到20微秒。
这当然提出了一个问题:当应用程序不能满足其响应时间要求时,应该做什么。答案随应用程序的不同而不同,但有一种可能性是,被控制的系统具有足够的稳定性和惯性,从而使偶尔发生的后期控制动作变得无害。另一种可能性是,该应用程序有两种计算结果的方法,一种是快速、确定性但不准确的方法,另一种是非常准确的、计算时间不可预测的方法。一种合理的方法是同时启动这两种方法,如果准确的方法不能及时完成,那就杀死它,使用快速但不准确的方法的答案。快速但不准确的方法的一个候选方法是在当前时间段内不采取控制操作,另一个候选是采取与前一个时间段内采取相同的控制操作。
简而言之,如果没有软度,谈论软实时是没有意义的。
14.3.1.2硬实时
相反,硬实时性的定义是相当明确的。毕竟,一个给定的系统要么总是在最后期限内完成,要么就没有完成。
不幸的是,严格应用这一定义将意味着永远不可能有任何困难的实时系统。在图14.1中可以幻想地描述了其原因。尽管你总是可以构建一个更健壮的系统,也许有冗余,你的对手总是可以得到一个更大的锤子。但不要相信我的话:问问恐龙吧。
不过话说回来,把显然不仅仅是硬件问题,而是真正的大型硬件问题归咎于软件,也许是不公平的。这表明,我们将硬实时软件定义为能够在最后期限前完成的软件,但只有在没有硬件故障的情况下。不幸的是,失败并非总是如此


一个选项,如图14.2所示。我们根本不能指望图中描述的可怜的先生放心,我们说:“放心,如果错过最后期限导致你的悲惨死亡,这肯定不是由于软件问题!”硬实时响应是整个系统的特性,而不仅仅是软件的特性。
但如果我们不能要求完美,也许我们可以通过通知,类似于前面提到的软实时方法。如果图14.2中的Life-a-Tron即将错过最后期限,它可以提醒医院工作人员。
不幸的是,这种方法有图14.3中想象中所描述的简单解决方案。一个总是立即发出通知,表示它不能满足其最后期限的系统符合法律条文,但它是完全无用的。显然,还必须要求系统在一定的时间内满足其最后期限,或者可能禁止它在超过一定数量的连续操作中错过其最后期限。
我们显然不能采取硬实时或软实时的可靠的方法。因此,下一节将采用更真实的方法。
14.3.1.3现实世界的实时
尽管像“硬实时系统总是在最后期限前完成!”吸引人,容易记住,现实世界的实时系统需要其他东西。尽管生成的规范很难记住,但它们可以通过对环境、工作负载和实时应用程序本身施加约束来简化实时系统的构建。
环境限制对环境的限制解决了对“硬实时”所隐含的开放式响应时间承诺的反对意见。这些约束条件可能规定允许的工作温度、空气质量、电磁辐射水平和类型,以及图14.1的点,冲击和振动水平。
当然,有些约束比其他约束更容易满足。很多人都已经意识到,商品电脑部件往往拒绝在低于零度的温度下运行,这表明了一套气候控制要求。
一位大学里的老朋友曾经遇到过一个挑战,即在具有一些相当具有攻击性的氯化合物的环境中操作实时系统,他明智地将这一挑战交给了设计硬件的同事。实际上,我的同事对计算机周围的环境施加了大气成分约束,硬件设计师通过使用物理密封来满足这一约束。
另一位大学老朋友研究一个计算机控制系统,该系统在真空中使用工业强度弧溅射钛锭。弧线有时会决定它厌倦了穿过钛锭的路径,并选择一条更短、更有趣的地面路径。正如我们在物理课上学到的,电子流的突然变化会产生电磁波,大电子流的大变化会产生高功率的电磁波。在这种情况下,由此产生的电磁脉冲足以在400米外的一个小“橡胶导管”天线的引线上产生四分之一的伏特电位差。这意味着附近的导体经历了更高的电压,这多亏了相反的平方定律。这包括那些组成计算机的控制溅射过程的导体。特别是,在计算机的重置线上产生的电压足以实际重置计算机,让所有参与的人都感到困惑。这种情况是通过硬件来解决的,包括一些复杂的屏蔽和一个我所听说过的比特率最低的光纤网络,即9600波特。不太壮观的电磁环境通常可以通过软件通过使用错误检测和校正码来处理。也就是说,重要的是要记住,尽管错误检测和校正代码可以降低故障率,但它们通常不能将它们一直降低到零,这可能是实现硬实时响应的另一个障碍。
也有一些情况下,需要最低水平的能量,例如,通过系统的电源引线,通过系统与外部世界的一部分进行通信。

许多系统旨在在具有令人印象深刻的冲击和振动水平的环境中运行,例如,发动机控制系统。当我们从连续的振动转向间歇性的冲击时,可能会发现更剧烈的要求。例如,在我的本科学习期间,我遇到了一台旧的雅典娜弹道学计算机,它被设计成即使附近的手榴弹爆炸,也能继续正常运行。最后,飞机中使用的“黑匣子”必须在坠毁前、期间和之后继续运行。
当然,也有可能使硬件更能抵御环境冲击和侮辱。任意数量的巧妙的机械减震装置都可以减少冲击和振动的影响,多层屏蔽可以减少低能电磁辐射的影响,纠错编码可以减少高能辐射的影响,各种盆栽和密封技术可以降低空气质量的影响,任何数量的加热和冷却系统都可以抵消温度的影响。在极端情况下,三重模冗余可以降低系统某一部分的故障导致整个系统的错误行为的可能性。然而,所有这些方法都有一个共同点:尽管它们可以降低失败的概率,但它们不能将其降低到零。
这些环境挑战通常通过健壮的硬件来解决,但是,接下来两个部分中的工作负载和应用程序约束通常在软件中处理。
工作量限制就像对人一样,通常可以通过超载来阻止实时系统达到最后期限。例如,如果系统被中断得太频繁,那么它可能没有足够的CPU带宽来处理其实时应用程序。解决此问题的硬件解决方案可能会限制将中断传递到系统的速率。可能的软件解决方案包括:如果中断接收得太频繁,则禁用中断一段时间,重置设备产生太频繁的中断,甚至完全避免中断以支持轮询。
由于排队效应,过载也会降低响应时间,因此实时系统过度提供CPU带宽并不罕见,因此正在运行的系统(例如)有80 %的空闲时间。这种方法也适用于存储和网络设备。在某些情况下,可能会保留单独的存储和网络硬件,以便单独使用实时应用程序的高优先级部分。简而言之,考虑到实时系统中的响应时间比吞吐量更重要,这个硬件大多是空闲的并不罕见。

当然,在整个设计和实现过程中,保持足够低的利用率需要良好的纪律。没有什么比一个小功能爬行更能破坏最后期限的了。
应用程序约束为某些操作比为其他操作更容易提供有限的响应时间。例如,看到响应时间是很常见的
针对中断和唤醒操作的规范,但对于(例如)文件系统卸载操作则非常罕见。这样做的一个原因是,很难绑定卸载文件系统操作可能需要做的工作量,因为需要卸载才能将该文件系统的所有内存数据刷新到大容量存储中。
这意味着实时应用程序必须被限制在能够合理地提供有限延迟的操作中。其他操作必须要么推送到应用程序的非实时部分,要么完全放弃。
对应用程序的非实时部分也可能存在限制。例如,非实时应用程序是否被允许使用拟用于实时部分的cpu?是否有一段时间段内应用程序的实时部分将异常繁忙,如果是,应用程序的非实时部分是否允许在这些时间内运行?最后,应用程序的实时部分允许用多少量来降低非实时部分的吞吐量?
从前面几节中可以看出,真实世界的实时规范需要包括对环境、工作负载和应用程序本身的约束。此外,对于允许应用程序的实时部分使用的操作,必须对实现这些操作的硬件和软件有限制。
对于每个这样的操作,这些约束可能包括最大响应时间(也可能还包括最小响应时间)和满足该响应时间的概率。100 %的概率表示相应的操作必须提供硬实时服务。
在某些情况下,响应时间和满足它们的所需概率可能会根据相关操作的参数而有所不同。例如,在本地局域网上的网络操作比在100微秒内完成的同一网络操作更有可能在跨大陆广域网内完成。此外,在铜或光纤局域网上的网络操作可能有极高的概率完成没有耗时的重传输,而在有损的WiFi网络上的同样的网络操作可能有更高的概率错过紧迫的截止日期。类似地,从紧密耦合的固态磁盘(SSD)读取可以比从老式usb连接的旋转锈磁盘驱动器读取速度快得多。6
一些实时应用程序会通过不同的操作阶段。例如,一个实时系统控制胶合板车床,从旋转原木上剥离一张薄薄的木头(称为“贴面”)必须: (1)将原木载入车床,(2)将原木放在车床的卡盘上,使原木中包含的最大圆柱暴露于叶片,(3)开始旋转原木,(4)不断改变刀的位置,将原木剥成单板,(5)去除剩余的原木太小,(6)等待下一个原木。这六个操作阶段的每一个都可能有自己的期限和环境限制,例如,人们预计第四阶段的期限会比阶段6的期限严重得多,即毫秒而不是秒。因此,人们可能期望,低优先级的工作将在阶段6中进行,而不是在阶段4中进行。无论如何,仔细的选择
这种分阶段开发的方法的一个关键优点是,可以分解延迟预算,这样就可以独立开发应用程序的各个组件,每个组件都有自己的延迟预算。当然,与任何其他类型的预算,可能会有偶尔的冲突,组件得到整体预算的一部分,和任何其他类型的预算,强大的领导和共享目标可以帮助及时解决这些冲突。同样,与其他类型的技术预算一样,还需要进行强有力的验证工作,以确保适当地关注延迟,并对延迟问题提供早期预警。一个成功的验证工作几乎总是包括一个好的测试套件,这可能使理论家们不满意,但也有帮助完成工作的优点。事实上,截至2021年初,大多数现实世界的实时系统都使用了验收测试,而不是正式的证明。
然而,广泛使用测试套件来验证实时系统确实有一个非常真实的缺点,即实时软件只在硬件和软件的特定配置上进行验证。添加额外的配置需要额外的昂贵和耗时的测试。也许正式核查领域将充分进展到足以改变这种情况,但到2021年初,还需要相当大的进展。

除了对应用程序的实时部分的延迟要求外,对应用程序的非实时部分可能还有性能和可伸缩性要求。这些额外的需求反映了这样一个事实,即通常可以通过降低可伸缩性和平均性能来实现最终的实时延迟。
软件工程需求也可能很重要,特别是对于必须由大型团队开发和维护的大型应用程序。这些要求通常有利于增加模块化和故障隔离。
这仅仅是为生产实时系统规定最后期限和环境限制所需的工作的大纲。希望这个大纲清楚地说明了基于声音咬合的实时计算方法的不足。
可以说,所有的计算实际上都是实时计算。例如,当你在网上购买生日礼物时,你期望礼物在收件人的生日之前到达。事实上,甚至即使是千年之交的web服务也观察到了亚秒的响应约束[Boh01],而且需求并没有随着时间的推移而得到缓解[DHJ+07]。然而,关注那些通过非实时系统和应用程序无法直接实现响应时间需求的实时应用程序是很有用的。当然,随着硬件成本的降低、带宽和内存大小的增加,实时和非实时之间的界限将继续改变,但这种进展绝不是一件坏事。

实时计算用于工业控制应用,从制造到航空电子设备;科学应用,也许最引人注目的是大型地球望远镜使用的自适应光学;军事应用,包括上述航空电子设备;以及金融服务应用,第一台识别出机会的计算机可能会获得大部分利润。这四个领域可以被描述为“寻找生产”、“寻找生命”、“寻找死亡”和“寻找金钱”。
金融服务应用程序与其他三类应用程序有细微的不同,因为金钱是非物质的,这意味着非计算延迟相当小。相比之下,其他三个类别中固有的机械延迟提供了一个非常真实的收益递减点,超过这个点,应用程序的实时响应的进一步减少将提供很少或没有好处。这意味着金融服务应用程序和其他实时信息处理应用程序将面临一场军备竞赛,而延迟最低的应用程序通常会获胜。尽管由此产生的延迟需求仍然可以按照第460页的“真实世界实时规范”段落中的描述来指定,但这些需求的不寻常性质导致一些人将金融和信息处理应用程序称为“低延迟”而不是“实时”。
不管我们到底选择叫它什么,对实时计算都有巨大的需求[Pet06,Inm07]。
目前还不太清楚谁真的需要并行实时计算,但低成本多核系统的出现却使它更加突出。不幸的是,传统的实时计算的数学基础假设是单cpu系统,只有少数例外证明了这一规则[Bra11]。幸运的是,有几种方法来调整现代计算硬件,以适应实时数学循环,一些linux内核黑客一直在鼓励学者进行这种转变[dOCdO19,Gle10]。
一种方法是认识到许多实时系统类似于生物神经系统,其反应范围从实时反射到非实时策略和规划,如图14.4所示。硬实时反射,从传感器和控制执行器中读取,在单个CPU或特殊用途的硬件上实时运行,如FPGA。应用程序的非实时策略和规划部分将在其余的cpu上运行。战略和规划活动可能包括统计分析、定期校准、用户界面、供应链活动和准备工作。对于高计算负载的准备活动的一个例子,请考虑

回到第460页“真实世界实时规范”段落中讨论的贴面剥离应用。当一个CPU正在处理剥离一个日志所需的高速实时计算时,其他CPU可能会分析下一个日志的大小和形状,以确定如何定位下一个日志,以获得最大的圆柱体的高质量木材。结果表明,许多应用程序都有非实时和实时的组件[BMP08],因此这种方法经常可以用于允许传统的实时分析与现代多核硬件相结合。
另一个简单的方法是只关闭一个硬件线程,以便返回到单处理器实时计算的既定数学过程中。然而,这种方法放弃了潜在的成本和能源效率优势。也就是说,获得这些优势需要克服第3章中所涵盖的并行性能障碍,而不仅仅是平均而言,而是在最坏的情况下。
因此,实现并行实时系统可能是一个相当大的挑战。在下一节中概述了应对这一挑战的方法。
我们将研究两种主要类型的实时系统,事件驱动系统和轮询。事件驱动的实时系统大部分时间都保持空闲状态,并实时响应通过操作系统传递给应用程序的事件。或者,系统可以运行后台非实时工作负载。轮询实时系统的特点是一个受CPU绑定的实时线程,在一个紧密的循环中运行,轮询输入和更新输出。这个紧密的轮询循环通常完全在用户模式下执行,读写到已经映射到用户模式应用程序地址空间的硬件寄存器。或者,一些应用程序将轮询循环放置到内核中,例如,使用可加载的内核模块。
无论选择何种风格,用于实现实时系统的方法都将取决于截止日期,例如,如图14.5所示。从这个图的顶部开始,如果您可以忍受响应时间超过一秒钟,您很可能可以使用脚本语言来实现您的实时应用程序——而且脚本语言实际上经常使用,我不一定推荐这种做法。如果所需的延迟超过几十毫秒,则可以使用旧的2.4Linux内核的版本,但我也不一定推荐这种做法。特殊的实时Java实现可以提供实时响应延迟

只有几毫秒,即使使用了垃圾收集器。Linux2.6。x和3。如果在实时友好的硬件上进行精心配置、调整和运行,x内核可以提供几百微秒的实时延迟。如果小心地避免使用垃圾收集器,特殊的实时Java实现可以提供低于100微秒的实时延迟。(但是请注意,避免垃圾收集器也意味着要避免Java的大型标准库,因此也也避免了Java的生产力优势。)Linux4。x和5。x内核可以提供亚100微秒的延迟,但有与2.6相同的警告。x和3。x内核。包含-rt补丁集的Linux内核可以提供远低于20微秒的延迟,而在没有mmu的情况下运行的专业实时操作系统(RTOSes)可以提供不到10微秒的延迟。实现亚微秒的延迟通常需要手工编码的组装,甚至需要特殊用途的硬件。
当然,在堆栈中一直都需要仔细的配置和调整。特别是,如果硬件或固件不能提供实时延迟,那么软件就无法弥补损失的时间。更糟糕的是,高性能硬件有时会牺牲最坏情况下的行为,以获得更大的吞吐量。事实上,来自已禁用中断的紧密循环运行的计时可以为高质量的随机数生成器提供基础[MOZ09]。此外,一些固件会通过窃取循环来执行各种内务管理任务,在某些情况下,它试图通过重新编程受害者CPU的硬件时钟来掩盖其轨迹。当然,循环窃取在虚拟环境中是预期的行为,但人们仍然是在虚拟环境中努力进行实时响应[Gle12,Kis14]。因此,评估硬件和固件的实时功能至关重要。
但是,对于合格的实时硬件和固件,堆栈上的下一层是操作系统,这将在下一节中介绍。
有许多策略可以用于实现一个实时系统。一种方法是将通用的非实时操作系统移植到专用的实时操作系统(RTOS)之上,如图14.6所示。绿色的“Linux进程”框表示运行在Linux内核上的非实时进程,而黄色的“RTOS进程”框表示运行在RTOS上运行的实时进程。
在Linux内核获得实时功能之前,这是一种非常流行的方法,并且仍在使用中[xen14,Yod04b]。但是,这种方法要求将应用程序分成一个在RTOS上运行的部分和另一个在Linux上运行的部分。虽然可以使这两个环境看起来相似,例如,通过将POSIX系统调用从RTOS转发到运行在Linux上的实用程序线程,但总是有粗糙的边。
此外,RTOS必须同时与硬件和Linux内核进行接口,因此需要对硬件和内核上的更改进行重大维护。此外,每个这样的RTOS通常都有自己的系统调用接口和一组系统库,它们可以简化生态系统和开发人员。事实上,这些问题似乎是推动RTOSes与Linux结合的原因,因为这种方法允许访问RTOS的全部实时功能,同时允许应用程序的非实时代码完全访问Linux的开源生态系统。
尽管在Linux内核具有最小的实时功能期间,将RTOSes与Linux内核配对是一个聪明而有用的短期响应,但它也促使人们向Linux内核添加实时功能。实现这个目标的进展情况如图14.7所示。上面一行显示了禁用抢占的Linux内核的图,因此基本上没有实时功能。中间一行显示了一组图表,显示了启用了抢占的主线Linux内核不断增强的实时能力。最后,最下面一行显示了一个应用了-rt补丁集的Linux内核的图表,从而最大化了实时功能。来自-rt补丁集的功能被添加到主线上,因此随着时间的推移,主线Linux内核的功能也会不断增强。然而,要求最高的实时应用程序继续使用-rt补丁集。
图14.7顶部所示的不可抢占内核是使用CONFIG_抢占=n构建的,因此在Linux内核中的执行不能被抢占。这意味着内核的实时响应延迟受Linux内核中最长代码路径的限制,这确实很长。但是,用户模式执行是可抢占的,因此在用户模式下执行时,右上角显示的一个实时Linux进程可以抢占左上角显示的任何非实时Linux进程。
Figure14.7shows的中间行在Linux的可抢占内核的开发中有三个阶段(从左到右)。在所有这三个阶段中,Linux内核中的大多数进程级代码都可以被抢占。这当然大大提高了实时响应延迟,但是在RCU读侧临界部分、自旋锁临界部分、中断处理程序、中断禁用的代码区域和抢占禁用的代码区域中,抢占仍然被禁用,如图中间一行最左边的图中的红色框所示。抢占RCU的出现允许RCU读侧临界部分被抢占,如中央图所示,线程中断处理程序的出现允许设备中断处理程序被抢占,如最右边的图所示。当然,在这段时间内还添加了许多其他的实时功能,但是,它不能在这个图中那样容易地表示出来。它将在第14.3.5.1节中进行讨论。



图14.7的底部一行显示了-rt补丁集,它为许多设备提供了线程化(因此是可抢占的)中断处理程序,这也允许这些驱动程序的相应的“中断禁用”区域被抢占。这些驱动程序反而使用锁定来协调每个驱动程序的进程级部分及其线程化的中断处理程序。最后,在某些情况下,禁用优先购买权将被禁用迁移所取代。这些度量在许多运行-rt补丁集的系统中产生了极好的响应时间[RMF19,dOCdO19]的响应时间。
最后一种方法是简单地清除实时进程中的所有内容,清除该进程需要的任何cpu中的所有其他处理,如图14.8所示。这是在3.10 Linux内核中通过CONFIG_NO_HZ_全Kconfig参数实现的[Cor13,Wei12]。需要注意的是,这种方法需要至少一个内务管理CPU来进行后台处理,例如运行内核守护进程。然而,当在一个给定的非内务化CPU上只有一个可运行的任务时,该CPU上的调度时钟中断将被关闭,从而消除了干扰和操作系统抖动的一个重要来源。除了少数例外,内核不会强制执行非内务CPU的其他处理,而只是在给定CPU上只有一个可运行任务时提供更好的性能。任意数量的用户空间工具都可以用来强制一个给定的CPU不再有一个可运行的任务。如果配置正确,这是一项重要的任务,CONFIG_NO_HZ_FULL提供了接近裸金属系统的实时线程性能水平[ACA+ 18]。弗雷德里克·魏斯贝克制作了CONFIG_NO_ HZ_FULL配置的实用指南[魏22d、魏22b、魏22e、魏22c、魏22a、魏22f]。
当然,关于这些方法中哪一种最适合实时系统,一直有很多争论,这场争论已经持续了很长一段时间[Cor04a,Cor04c]。和往常一样,答案似乎是“视情况而定”,正如下面几节所讨论的那样。Section14.3.5.1considers事件驱动的实时系统和使用与cpu绑定的轮询循环的Section14.3.5.2considers实时系统。
事件驱动的实时应用程序所需的操作系统支持非常广泛,但是,本节将只关注几个项目,即计时器、线程中断、优先级继承、抢占RCU和抢占自旋锁。
计时器显然对实时操作至关重要。毕竟,如果你不能指定在特定的时间做某件事,那么到那时你将如何回应呢?即使在非实时系统中,也会产生大量的计时器,因此必须非常有效地处理它们。示例包括TCP连接的重传定时器(几乎总是在有机会触发之前被取消)、7个定时延迟(如在睡眠中(1),很少被取消)和轮询()系统调用的超时(通常在有机会触发之前被取消)。因此,这些计时器的良好数据结构将是一个优先队列,该队列的添加和删除原语是快速的,并且发布的计时器数量为O (1)。
为此目的的经典数据结构是日历队列,它在Linux内核中被称为计时器轮。这种古老的数据结构也被大量用于离散事件模拟。其思想是时间是量化的,例如,在Linux内核中,时间量子的持续时间是调度-时钟中断的周期。一个给定的时间可以用一个整数来表示,任何在某个非积分时间发布计时器的尝试都将被四舍五入到一个方便的附近的积分时间量子。
一个简单的实现是分配一个数组,按时间的低阶位进行索引。这在理论上是可行的,但在实践中,系统产生了大量的长时间超时(例如,TCP会话的两小时保持活动超时),这些超时几乎总是被取消。这些长时间超时会导致小阵列造成问题,因为浪费了大量时间跳过尚未过期的超时。另一方面,一个足够大,能够优雅地容纳大量长时间超时的阵列将消耗太多的内存,特别是考虑到性能和可伸缩性问题,每个CPU都需要一个这样的阵列。
解决此冲突的一种常见方法是在一个层次结构中提供多个数组。在此层次结构的最低级别上,每个数组元素代表一个时间单位。在第二层,每个数组元素代表N个时间单位,其中N是每个数组中的元素数量。在第三层,每个数组元素代表n2个时间单位,以此类推。这种方法允许单个数组按不同的位进行索引,如图14.9所示,对于一个不现实的小8位时钟。这里,每个数组有16个元素,因此低阶4位(当前0xf)索引低阶(最右边)数组,后续4位(当前0x1)索引下一级。因此,我们有两个数组,每个数组都有16个元素,总共有32个元素,它们加在一起,比单个数组所需的256个元素数组要小得多。
这种方法非常适用于基于吞吐量的系统。每个计时器操作是O (1)和小常数,每个计时器元素最多被触摸m + 1次,其中m是级别数。
不幸的是,计时器轮不能很好地运行实时系统,有两个原因。第一个原因是在计时器精度和计时器开销之间存在一个严格的权衡,图14.10和14.11充分说明了这一点。在图14.10中,计时器处理每毫秒只发生一次,这是可接受的开销



对很多人来说都很低(但不是全部!)工作负载,但这也意味着不能为超过1毫秒的粒度设置超时。另一方面,图14.11显示了每10微秒进行一次的计时器处理,这为大多数人(但不是所有的人!)提供了可接受的精细计时器粒度工作负载,但它处理计时器如此频繁,系统可能没有时间做其他事情。
第二个原因是需要将计时器从较高级级联到较低级。参考图14.9,我们可以看到,在上(最左)数组中的元素1x上排队的任何计时器都必须级联到下(最右)数组,以便在它们的时间到达时可以调用。不幸的是,可能会有大量的超时等待级联,特别是对于具有更多级别的计时器轮。统计数据的威力使得这种级联对于面向吞吐量的系统来说不是一个问题,但是级联可能会导致实时系统中延迟的有问题的下降。
当然,实时系统可以简单地选择一种不同的数据结构,例如,某种形式的堆或树,放弃插入和删除操作的O (1)边界,以获得数据结构维护操作的O(logn)限制。这对于特殊用途的RTOSes来说是一个很好的选择,但是对于像Linux这样的通用系统时效率低下,它通常支持大量的计时器。
为Linux内核的-rt补丁集选择的解决方案是区分安排稍后活动的计时器和安排TCP包丢失等低概率错误的超时。一个关键的观察结果是,错误处理通常不是特别的时间关键性,因此计时器轮的毫秒级粒度是好的和足够的。另一个关键的观察结果是,错误处理超时通常很早就被取消,通常是在它们可以级联之前。此外,系统通常比处理计时器事件有更多的错误处理超时,因此O(logn)数据结构应该为计时器事件提供可接受的性能。
然而,也有可能做得更好,即通过简单地拒绝级联计时器。而不是级联,否则就会在日历队列中一直被级联的计时器会被适当地处理。这确实会导致在持续时间内出现高达百分之几的错误,但在少数情况出现问题的情况下,可以使用基于树的高分辨率计时器(hr计时器)。

简而言之,Linux内核的-rt补丁集使用计时器轮来进行错误处理超时,使用树来用于计时器事件,为每个类别提供所需的服务质量。
线程中断用于解决降级的实时延迟的一个重要来源,即长时间运行的中断处理程序,如图14.12所示。对于能够通过单个中断传递大量事件的设备来说,这些延迟尤其成问题,这意味着中断处理程序将长时间处理所有这些事件。更糟糕的是,可以将新事件传递到仍在运行的中断处理程序的设备,因为这样的中断处理程序很可能无限期地运行,从而无限期地降低实时延迟。
解决这个问题的一种方法是使用图14.13中所示的线程中断。中断处理程序在可抢占IRQthead上下文中运行,该进程以可配置优先级运行。然后,设备中断处理程序只运行很短的时间,刚好足以使IRQ线程知道新事件。如图所示,线程中断可以大大改善实时延迟,部分原因是在IRQ线程上下文中运行的中断处理程序可能会被高优先级的实时线程抢占。
然而,没有免费的午餐,线程中断也有缺点。其中一个缺点是中断延迟的增加。而不是立即运行中断处理程序,该处理程序的执行将被延迟,直到IRQ线程开始运行它。当然,这不是一个问题,除非生成中断的设备是在实时应用程序的关键路径上。

另一个缺点是,编写得糟糕的高优先级实时代码可能会饿死中断处理程序,例如,阻止网络代码运行,从而使调试问题变得非常困难。因此,开发人员在编写高优先级的实时代码时必须非常小心。这被称为蜘蛛侠原则:巨大的力量会带来巨大的责任。
优先级继承用于处理优先级反转,优先级反转可能是由可抢占中断处理程序获取的锁引起的[SRL90]。假设一个低优先级的线程持有一个锁,但被一组中等优先级的线程抢占,每个CPU至少有一个这样的线程。如果发生中断,一个高优先级的IRQ线程将优先于其中一个中优先级的线程,但只有在它决定获得低优先级线程所持有的锁之前。不幸的是,低优先级的线程在它开始运行之前不能释放锁,而中等优先级的线程阻止它这样做。因此,高优先级的IRQ线程只有在中优先级的一个线程释放其CPU后才能获得锁。简而言之,中等优先级的线程间接地阻塞了高优先级的IRQ线程,这是优先级反转的一个经典情况。
请注意,这种优先级反转不会发生在非线程中断中,因为低优先级线程必须在保持锁时禁用中断,这将防止中优先级线程抢占它。
在优先级继承解决方案中,试图获取锁的高优先级线程将其优先级提供给持有锁的低优先级线程,直到锁被释放,从而防止了长期的优先级倒置。
当然,优先级继承确实有其局限性。例如,如果您可以设计应用程序以完全避免优先级反转,那么您可能会获得更好的延迟[Yod04b]。这并不奇怪,因为优先级继承将一对上下文切换到最坏情况的延迟。也就是说,优先级继承可以将无限期延迟转换为有限的延迟时间的增加,并且在许多应用程序中,优先级继承的软件工程好处可能超过其延迟时间的成本。
另一个限制是,它只处理给定操作系统上下文中的基于锁的优先级倒置。它无法解决的一个优先级反转场景是一个高优先级线程等待网络套接字,等待消息,该低优先级进程被一组cpu绑定的中优先级进程抢占写入。此外,图14.14还幻想地描述了对用户输入应用优先级继承的一个潜在缺点。
最后一个限制涉及到读写器锁定。假设我们有大量的低优先级线程,甚至数千个线程,每个线程读取一个特定的读写器锁。假设所有这些线程都被一组中等优先级的线程所抢占,每个CPU至少有一个中等优先级的线程。最后,假设一个高优先级的线程唤醒并尝试写-获取相同的读写器锁。无论我们多么积极地提高读程读取的优先级——保持这个锁,高优先级线程完成其写获取很可能需要很长一段时间。
对于这个读写锁优先级反转难题,有许多可能的解决方案:
1.一次只允许对一个给定的读写器锁进行一次读取。(这是Linux内核的-rt补丁集传统上采用的方法。)
2.一次只允许N个读写器锁的读取,其中N是cpu的数量。
3.一次只允许N个读获取给定的读写器锁,其中N是开发人员以某种方式指定的数字。
4.禁止高优先级线程来自写获取的读写器锁,这些锁曾经被以较低优先级运行的线程读取。(这是优先级上限协议[SRL90]的一个变体。)

无并发读取器的限制最终变得无法忍受,因此-rt开发人员更仔细地研究了Linux内核是如何使用读取器-编写器的自旋锁的。他们了解到,时间关键代码很少使用内核中写获取读者-作者锁的部分,因此作者饥饿的前景并不会阻碍显示。因此,他们构建了一个实时的读-写器锁,在这个锁中,写端获取彼此之间使用优先级继承,但读端获取绝对优先于写端获取。这种方法在实践中工作得很好,这是清楚了解用户真正需要的重要性的另一个教训。
这个实现的一个有趣的细节是,rt_read_lock()和rt_write_lock()函数都进入一个RCU读侧临界部分,而rt_read_unlock()和rt_write_unlock()函数都退出该临界部分。这是必要的,因为非实时内核的读-写锁定函数禁用了其关键部分的抢占,而且确实有读-写锁定用例依赖于synchronize_rcu()将等待所有已存在的读-写-锁关键部分完成。让这给你一个教训:了解用户真正需要什么对正确操作至关重要,而不仅仅是对性能。不仅如此,用户真正需要改变的东西也会随着时间的推移而改变。
这样做的一个副作用是,所有的a -rt内核的读写器锁定关键部分都受到RCU优先级的提升。这至少为读写器锁定阅读器被抢占很长一段时间的问题提供了部分解决方案。
还可以通过将读写锁转换为RCU来避免读写锁优先级反转,下一节将简要讨论。
优先使用的RCU有时可以用作替代读写器锁定[MW07,MBWW12,McK14f],如第9.5节中所讨论的。在可以使用它的地方,它允许阅读器和更新器并发运行,从而防止低优先级阅读器对高优先级更新器施加任何类型的优先级反转场景。然而,为了实现这一点,有必要能够抢占长期运行的RCU读侧临界部分[GMTW08]。否则,长RCU读侧临界部分将导致过多的实时延迟。
因此,向Linux内核中添加了一个可抢占的RCU实现。该实现通过保留在当前RCU读端关键部分中已被优先处理的任务列表,该实现避免了单独跟踪内核中每个任务的状态的需要。宽限期是允许结束: (1)一旦所有cpu完成任何RCU读边关键部分生效前当前宽限期和(2)一旦所有任务抢占在那些预先存在的关键部分从列表中删除。此实现的一个简化版本如清单14.3所示。__rcu_read_lock()函数跨越第1-5行,而__rcu_read_unlock()函数跨越第7-15行。
__rcu_read_lock()的第3行增加了嵌套rcu_read_lock()调用数量的每个任务计数,第4行防止编译器将RCU读侧关键部分中的后续代码重新排序到rcu_read_lock()之前。
__rcu_read_unlock()的第9行可以防止编译器使用此函数的其余部分重新排序关键部分中的代码。第10行减少了嵌套计数,并检查了它是否已经变为零,换句话说,这是否对应于一个嵌套集的最外层的rcu_read_unlock()。如果是,第11行防止编译器通过第12行检查重新排序嵌套更新。如果需要特殊处理,则在第13行呼叫rcu_read_unlock_special()。
可能需要几种特殊处理类型,但是当RCU读侧关键部分被抢占时,我们将关注所需的处理。在这种情况下,任务必须从其RCU读端关键部分中首次抢占时添加到的列表中删除自己。但是,需要注意的是,这些列表受到锁的保护,这意味着rcu_read_unlock()不再是无锁的。但是,最高优先级的线程将不会被抢占,因此,对于那些最高优先级的线程,rcu_read_unlock()将永远不会尝试获取任何锁。此外,如果仔细实施,锁定可以用于同步实时软件[Bra11,SM04a]。

RCU的另一个重要的实时特性,无论是否具有可抢占性,都是能够将RCU回调执行卸载到内核线程中。要使用这个,您的内核必须使用CONFIG_RCU_NOCB_CPU=y构建,并使用rcu_nocbs=内核引导参数指定要卸载的cpu。或者,由第14.3.5.2will节中描述的nohz_full=内核引导参数指定的任何CPU也都会卸载其RCU回调。
简而言之,这种可抢占的RCU实现允许对读取数据结构——主要是实时响应,不会出现大量读取器优先级提升所固有的延迟,也不会由于回调调用而产生的延迟。
由于Linux内核中存在长时间的基于自旋锁的关键部分,可抢占的自旋锁是-rt补丁集的一个重要部分。这个功能还没有达到主流:尽管它们是一个概念上简单的替代品,但它们已经被证明是相对有争议的。此外,主线Linux内核中的实时功能满足了许多用例,这减缓了2010年代早期-rt补丁集的开发速度[Edg13,Edg14]。然而,抢占自旋锁对于实现数十微秒的实时延迟是绝对必要的。幸运的是,Linux基金会组织了一项努力,以资助将剩余的代码从-rt补丁集转移到主线。
出于性能原因,在Linux内核中大量使用每个cpu变量。不幸的是,对于实时应用程序,每个cpu变量的许多用例需要协调更新多个这样的变量,这通常是通过禁用抢占来提供的,这反过来会降低实时延迟。实时应用程序显然需要其他方式来协调每个cpu变量更新。
一种替代方法是提供每个cpu的自旋锁,如上所述,它们实际上是光滑的,以便它们的关键部分可以被抢占,从而提供优先级继承。在这种方法中,每个CPU变量的代码更新组必须获得当前CPU的自旋锁,执行更新,然后释放任何获得的锁,请记住,抢占可能导致迁移到其他CPU。但是,这种方法同时引入了开销和死锁。
另一种替代方案,即在2021年初开始在-rt补丁集中使用,是将抢占禁用转换为迁移禁用。这确保了一个给定的内核线程在每个CPU变量更新的过程中一直保持在其CPU上,但也可以允许其他一些内核线程对这些相同的变量进行自己的更新。在一些情况下,比如统计数据收集,这不是一个问题。在令人惊讶的罕见情况下,这种中间更新抢占是一个问题,手头的用例必须正确地同步更新,可能通过一组特定于该用例的每个cpu锁。尽管引入锁再次引入了死锁的可能性,但这些锁的每个用例性质使任何此类死锁都更容易管理和避免。
关闭事件驱动的备注。当然,还有许多其他的linux内核组件对于实现世界级的实时延迟至关重要,
例如,截止日期调度[dO18b,dO18a],但是,本节中列出的那些调度对由-rt补丁集增强的Linux内核的工作方式有了一种很好的感觉。
乍一看,使用轮询循环似乎似乎避免了所有可能的操作系统干扰问题。毕竟,如果一个给定的CPU从未进入内核,那么内核就完全消失了。让内核远离内核的传统方法就是没有内核,许多实时应用程序确实可以在裸金属上运行,特别是那些运行在8位微控制器上的应用程序。
人们可能希望通过在给定的CPU上运行单个CPU绑定的用户模式线程,就可以在现代操作系统内核上获得裸金属性能,避免所有干扰原因。虽然现实当然更为复杂,但由于弗雷德里克·韦斯贝克领导的NO_HZ_FULL实现[Cor13],Wei12],该实现已被接受到Linux内核的3.10版本中。然而,正确地设置这样的环境需要相当小心,因为有必要控制许多可能的操作系统抖动来源。下面的讨论涵盖了对操作系统抖动的几个来源的控制,包括设备中断、内核线程和守护进程、调度器的实时限制(这是一个特性,而不是一个bug!),计时器、非实时设备驱动程序、内核内全局同步、调度时钟中断、页面故障,最后,还有非实时硬件和固件。
中断是大量OS抖动的一个极好的来源。不幸的是,在大多数情况下,为了与外部世界通信,绝对需要中断。解决操作系统抖动和与外部世界保持联系之间的冲突的一种方法是保留少量的内务cpu,并强制执行对这些cpu的所有中断。Linux源代码树中的文档/irq关联.txt文件描述了如何将设备中断定向到指定的cpu,截至2021年初,该cpu涉及以下内容
| $ echo 0f > /proc/irq/44/smp_affinity |
这个命令将把中断#44限制为cpu0-3。请注意,调度时钟中断需要特殊处理,这将在本节后面进行讨论。
操作系统抖动的第二个来源是由于内核线程和守护进程。单个内核线程,如RCU的宽限期内核线程(rcu_bh、rcu_preempt和rcu_sched),可以使用任务集命令、sched_setaffinity()系统调用或cgroups强制到任何所需的cpu上。
每个cpu的k线程通常更具挑战性,有时会限制硬件配置和工作负载布局。防止操作系统抖动这些kshowes要求某些类型的硬件不附加到实时系统,所有中断和I/O启动发生在管家cpu,特殊的内核Kconfig或引导参数被选择为了直接工作远离工作cpu,或者工作cpu永远不会进入内核。具体的每个k线程的建议可以在Linux内核源文档目录中的每个cpu-k线程的内核.txt中找到。
对于以实时优先级运行的cpu绑定线程,Linux内核中操作系统抖动的第三个来源是调度程序本身。这是一个有意的调试特性,旨在确保重要的非实时工作每秒至少分配50毫秒,即使在实时应用程序中存在无限循环的bug。但是,当您正在运行一个轮询循环风格的实时应用程序时,您将需要禁用此调试功能。该操作的方法如下:
| $echo-1>/proc/sys/内核/sched_rt_runtime_us |
当然,您需要作为根目录运行来执行此命令,而且您还需要仔细考虑前面提到的蜘蛛侠原则。最小化风险的一种方法是从正在运行与cpu绑定的实时线程的所有cpu中卸载中断和内核线程/守护进程,如上述段落所述。此外,您应该仔细阅读文档/调度程序目录中的材料。sched-rt-group .rst文件中的材料特别重要,特别是当您正在使用由CONFIG_RT_GROUP_SCHED Kconfig参数启用的c组实时特性时。
操作系统抖动的第四个来源来自计时器。在大多数情况下,将给定的CPU排除在内核之外将防止计时器被安排在该CPU上。一个重要的例外是重复计时器,即给定的计时器处理程序会发布稍后出现的同一计时器。如果这样的计时器在给定的CPU上启动,该计时器将继续在该CPU上定期运行,无限期地造成操作系统抖动。卸载循环计时器的一个粗糙但有效的方法是使用CPU热插头离线所有运行CPU绑定的实时应用程序线程的工作CPU,在线这些相同的CPU,然后启动你的实时应用程序。
操作系统抖动的第五个来源是由不打算实时使用的设备驱动程序提供的。对于一个旧的规范示例,在2005年,VGA驱动程序将通过在禁用中断的帧缓冲器来空白屏幕,这导致数十毫秒的操作系统抖动。避免设备驱动程序引起的操作系统抖动的一种方法是仔细选择在实时系统中大量使用,因此修复了实时错误的设备。另一种方法是将设备的中断和使用该设备的所有代码限制在指定的内务cpu中。第三种方法是测试该设备支持实时工作负载和修复任何实时错误的能力。8
操作系统抖动的第六个来源是由一些内核内的全系统同步算法提供的,也许最显著的是全局TLB-flush算法。这可以通过避免内存解映射操作,特别是避免内核内的解映射操作来避免。到2021年初开始,避免内核内解映射操作的方法是避免卸载内核模块。
操作系统抖动的第七个源是由调度时钟中断和RCU回调调用提供的。可以通过构建启用了NO_HZ_ FULL Kconfig参数的内核,然后使用nohz_full=参数指定要运行实时线程的工作cpu列表来避免这些问题。例如,nohz_full=2-7将cpu2、3、4、5、6和7指定为工作cpu,从而将cpu0和1留为内务cpu。只要在每个工作CPU上不存在超过一个可运行的任务,工作CPU就不会发生调度时钟中断,并且每个工作CPU的RCU回调将在其中一个内务管理CPU上被调用。由于CPU上只有一个可运行任务而抑制调度时钟中断的CPU被称为自适应滴答模式或nohz_full模式。重要的是要确保您指定了足够的管理cpu来处理系统其他部分施加的管理负载,这需要仔细的基准测试和调优。
操作系统抖动的第八个来源是页面故障。因为大多数Linux实现都使用MMU来保护内存,所以在这些系统上运行的实时应用程序
8如果你采取这种方法,请提交你的修复程序上游,以便其他人可以受益。毕竟,当您需要将应用程序移植到以后的Linux内核版本时,您将成为那些“其他版本”之一。
| 1 cd /sys/kernel/debug/tracing |
|
| 2 |
回声1 > max_graph_depth |
| 3 |
|
| 4 |
#运行工作量 |
| 5 |
猫per_cpu/cpuN/跟踪 |
可能会出现页面故障。使用mlock()和所有()系统调用将应用程序的页面锁定到内存中,从而避免重大页面故障。当然,蜘蛛侠原理也适用,因为锁定太多的内存可能会阻止系统完成其他工作。
不幸的是,操作系统抖动的第九个来源是硬件和固件。因此,使用已经为实时使用而设计的系统是很重要的。
不幸的是,这个操作系统抖动源的列表永远不会完整,因为它会随着内核的每个新版本而改变。这使得有必要能够跟踪OS抖动的其他源。给定一个运行一个CPU绑定的用户模式线程的CPU N,清单14.4中所示的命令将生成一个包含该CPU进入内核的所有时间的列表。当然,第5行的N必须用有问题的CPU的数量来替换,而第2行的1可以增加以显示内核内额外级别的函数调用。生成的跟踪可以帮助跟踪操作系统抖动的来源。
和往常一样,这里没有免费的午餐,NO_HZ_FULL也不例外。如前所述,NO_HZ_FULL使内核/用户转换更加昂贵,因为需要将转换通知内核子系统(如RCU)。作为一个粗略的经验法则,NO_HZ_FULL有助于处理许多类型的实时和重计算的工作负载,但会损害其他具有高系统调用和I/O [ACA+ 18]率的工作负载。其他的限制、权衡和配置建议可以在文档/计时器/no_hz.rst中找到。
正如您所看到的,在Linux等通用操作系统上运行cpu绑定的实时线程时,要获得裸金属性能,就需要认真关注细节。自动化当然会有所帮助,而且一些自动化已经被应用,但考虑到用户数量相对较少,自动化可能会看起来相对缓慢。然而,在运行通用操作系统时获得几乎裸金属性能的能力承诺可以简化某些类型的实时系统的构建。
开发实时应用程序是一个范围广泛的主题,本节只能涉及以下几个方面。为此,第14.3.6.1looks节介绍了实时应用程序中常用的一些软件组件,第14.3.6.2provides节简要概述了可能是如何实现基于轮询循环的应用程序的,第14.3.6.3节给出了类似的流媒体应用程序的概述,第14.3.6.4节简要介绍了基于事件的应用程序。
在工程的所有领域中,一组健壮的组件对生产率和可靠性至关重要。本节并不是实时软件组件的完整目录。目录将填充多本书,而是对可用组件类型的简要概述。
寻找实时软件组件的一个自然位置将是提供无等待同步的算法[Her91],事实上,无锁算法对实时计算非常重要。然而,无等待同步只能保证在有限的时间内向前进行。虽然一个世纪是有限的,但当你的截止日期以微秒为单位测量时,这是没有帮助的,更不用说毫秒了。
然而,有一些重要的无等待算法确实提供了有限制的响应时间,包括原子测试和设置、原子交换、原子获取和添加、基于循环数组的单生产者/单消费者FIFO队列,以及大量的每线程分区算法。此外,最近的研究证实了一个观察结果,即具有无锁保证的算法在实践中也提供相同的延迟(在无等待的意义上),假设一个随机公平的调度器和没有失败停止bug[ACHS13]。这意味着许多非无等待的堆栈和队列仍然适合实时使用。

在实践中,锁定经常用于实时程序,理论上是不成立的。然而,在更严格的约束下,基于锁的算法也可以提供有限的延迟[Bra11]。这些限制条件包括:
1.公平的调度程序。在固定优先级调度器的常见情况下,有限的延迟只提供给最高优先级的线程。
2.有足够的带宽来支持工作负载。支持这一约束的实现规则可能是“在正常运行期间,所有cpu上至少有50 %的空闲时间”,或者,更正式地说,“提供的负载将足够低,允许工作负载随时可调度。”
3.没有故障停止错误。
4.FIFO锁定原语带有获取、切换和释放延迟的限制。同样,在优先级内的FIFO锁定原语的常见情况下,限制延迟只提供给最高优先级的线程。
5.一种防止无界优先级反转的一些方法。本章前面提到的优先级上限和优先级继承学科就足够了。
6.锁获取的边界嵌套。我们可以有一个无限数量的锁,但只要一个给定的线程一次不能获得超过一些锁(理想情况下只有一个)。
7.线程数。与前面的约束相结合,这个约束意味着在任何给定的锁上都将有有限数量的线程等待。
8.在任何给定的关键部分所花费的限定时间。给定在任何给定锁上等待的线程数量和临界部分持续时间,等待时间将是有限的。

这一结果为实时软件中提供了大量的算法和数据结构,并验证了长期的实时实践。
当然,一个仔细和简单的应用程序设计也非常重要。世界上最好的实时组件无法弥补一个不经过深思熟虑的设计。对于并行实时应用程序,同步开销显然必须是设计的一个关键组成部分。
许多实时应用程序由一个单个cpu绑定的循环组成,该循环读取传感器数据,计算控制律,并写入控制输出。如果提供传感器数据和获取控制输出的硬件寄存器被映射到应用程序的地址空间中,则此循环可能完全没有系统调用。但是要注意蜘蛛侠的原则:强大的力量就会带来巨大的责任,在这种情况下,就有责任避免通过不适当地引用硬件寄存器来损坏硬件。
这种安排通常运行在裸金属上,没有任何好处(或来自)操作系统的干扰。然而,硬件能力的提高和自动化水平的提高推动了软件功能的增加,例如,用户界面、日志记录和报告,所有这些都可以从操作系统中获益。
在裸金属上运行的同时,还可以访问通用操作系统的全部功能的一种方法是使用Linux内核的NO_HZ_FULL功能,如第14.3.5.2节所述。
一种大数据实时应用程序从许多来源获取输入,在内部处理它,并输出警报和摘要。这些流媒体应用程序通常是高度并行的,可以同时处理不同的信息源。
实现流媒体应用程序的一种方法是使用密集阵列循环FIFOs来连接不同的处理步骤[Sut13]。每个这样的FIFO只有一个线程,以及一个(可能不同的)单线程。扇入和扇出点使用线程而不是数据结构,所以如果需要合并几个FIFO的输出,一个单独的线程将从它们输入并输出到另一个FIFO,这个单独的线程是唯一的生产者。类似地,如果一个给定的FIFO的输出需要被拆分,则一个单独的线程将从该FIFO中输入,并根据需要输出到几个FIFO。
这个规程可能看起来很有限制,但它允许以最小的同步开销在线程之间进行通信,并且在试图满足严格的延迟约束时,最小的同步开销非常重要。当每个步骤的处理量很小时,尤其如此,因此同步开销比处理开销更大。
单个线程可能是cpu绑定的,在这种情况下,将适用于第14.3.6.2节中的建议。另一方面,如果单个线程阻塞了等待从其输入的fifo中获得的数据,则适用下一节的建议。
| 清单14.5:定时等待测试程序 |
|
| 如果2,则为1 3 4 } 5如果6 7 8 } 9如果10 11 12 } |
(clock_gettime(CLOCK_REALTIME,和时间启动)!=0){ 错误(“clock_gettime 1”);退出(-1); (纳米睡眠(&时间等待,空)!=0){perror(“纳米睡眠”); 出口(-1); (clock_gettime(CLOCK_REALTIME,和时间结束)!=0){ 错误(“clock_gettime 2”);退出(-1); |
我们将使用燃料喷射到一个中型工业发动机作为事件驱动应用的一个奇特的例子。在正常工作条件下,该发动机要求在顶部死区中心周围的一度间隔内注入燃料。如果我们假设1500转的转速,我们每秒有25个旋转,或者大约每秒9000度,即每秒111微秒。因此,我们需要将燃油喷射安排在大约100微秒的时间间隔内。
假设一个定时等待将被用来启动燃油喷射,尽管如果你正在建造一个发动机,我希望你提供一个旋转传感器。我们需要测试定时等待功能,也许可以使用清单14.5中所示的测试程序。不幸的是,如果我们运行这个程序,我们可能会得到不可接受的计时器抖动,即使是在a -rt内核中。
奇怪的是,一个问题是,POSIX CLOCK_REALTIME并不能实时使用。相反,它的意思是“实时”,而不是进程或线程所消耗的CPU时间。对于实时使用,您应该使用CLOCK_MONOTONIC。然而,即使有了这种变化,结果仍然是不可接受的。
另一个问题是,必须通过使用sched_setscheduler()系统调用将线程提升到实时优先级。但即使是这种改变也是不够的,因为我们仍然可以看到页面错误。我们还需要使用锁定()系统调用来锁定应用程序的内存,防止页面故障。有了所有这些变化,结果可能最终是可以接受的。
在其他情况下,可能需要进行进一步的调整。可能有必要将时间关键的线程亲和到它们自己的cpu上,也可能有必要亲和中断远离这些cpu。可能需要仔细选择硬件和驱动程序,而且很可能需要仔细选择内核配置。
从这个例子中可以看出,实时计算可能是相当不可原谅的。
假设您正在编写一个并行的实时应用程序,它需要访问可能发生逐渐变化的数据,这可能是由于温度、湿度和气压的变化。这个程序上的实时响应约束是如此严重,以至于不允许旋转或阻塞,因此排除了锁定,也不允许使用重试循环,从而排除了序列锁和危险指针。幸运的是,温度和压力通常是受到控制的,因此一个默认的硬编码数据集通常就足够了。
然而,温度、湿度和压力偶尔会偏离默认值,在这种情况下,有必要提供替代默认值的数据。因为温度、湿度和压力是逐渐变化的,所以提供更新的值并不是一个紧急事项,尽管它必须在几分钟内发生。该程序将使用一个名为cur_cal的全局指针,它通常引用default_cal,这是一个静态分配和初始化的结构,包含了名为a、b和c的字段中的默认校准值。否则,cur_cal指向一个提供当前校准值的动态分配的结构。
清单14.6显示了如何使用RCU来解决这个问题。查找是确定性的,如第9-15行上的calc_control()所示,与实时需求一致。更新更为复杂,如update_cal()在第17-35行所示。

这个示例展示了RCU如何提供对实时程序的确定性读端数据结构访问。

在实时计算和实时快速计算之间的选择可能是一个很困难的问题。因为实时系统经常会对非实时计算造成吞吐量损失,所以在不需要时使用实时计算是不明智的,如图14.15所示。
另一方面,在需要时不使用实时操作也会导致问题,如图14.16所示。这几乎足以让你为老板感到难过了!
其中一个经验法则是使用以下四个问题来帮助你进行选择:
1.平均长期吞吐量是唯一的目标吗?
2.是否允许重负载降低响应时间?
3.是否存在高内存压力,排除使用()()系统调用?
4.应用程序的基本工作项是否需要超过100毫秒才能完成?
如果这些问题的答案都是“是”,你应该选择实时快速而不是实时,否则,实时可能会适合你。
明智地选择,如果你选择实时,确保你的硬件,固件和操作系统的工作!
Chapter 15 Advanced Synchronization:Memory Ordering
进步的艺术是在变化中保持秩序,在秩序中保持变化。
怀德海
因果关系和排序是非常直观的,黑客通常对这些概念有很强的把握。这些直觉在编写、分析和调试顺序代码时不仅非常有用,而且在使用诸如锁定等标准互斥机制的并行代码时也非常有用。不幸的是,这些直觉在代码中完全崩溃,而是使用弱有序的原子操作和内存障碍。这类代码的一个示例实现了标准互斥机制,而另一个示例实现了使用较弱同步的快速路径。尽管侮辱了直觉,但有些人认为弱点是一种美德。美德或缺点,这一章将帮助您理解内存顺序,通过实践,这将足以实现同步原语和性能关键的快速路径。
第15.1节将演示真实的计算机系统可以重新排序内存参考,给出它们这样做的一些原因,并提供一些关于如何防止不希望的重新排序的信息。第15.2节和第15.3节将分别涵盖硬件和编译器可能给粗心的并行程序员带来的痛苦类型。第15.4节概述了在更高的抽象级别上建模内存排序的好处。第15.5节随后将详细介绍一些具有代表性的硬件平台。最后,第15.6节提供了一些可靠的直觉和有用的经验法则。

15.1 订购:为什么和如何?
除非人们控制它,没有什么是有序的。创造中的一切都是松散的。
亨利沃德比彻,更新
内存排序的一个动机可以在清单15.1(C-SB+o-o+o-o.litmus)中看似简单的试金石中看到,乍一看似乎可以保证
纯粹主义者会坚持存在条款永远不会被满足,但我们在这里使用“触发”来类比断言。
2,即线程P0()的局部变量r2的实例等于零。试金石命名法的文件见第12.2.1节。
3请注意,结果对确切的硬件配置、系统加载的程度以及其他许多方面都很敏感。所以为什么不在你自己的系统上尝试一下呢?
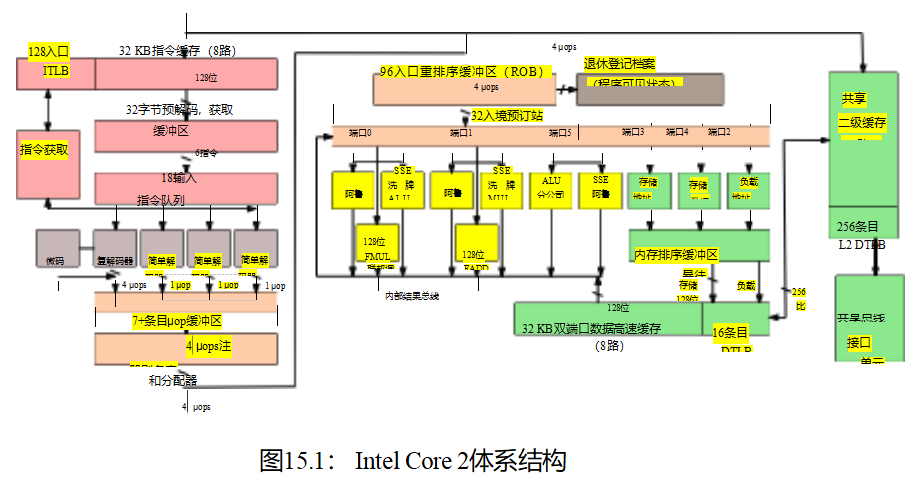
但是为什么记忆排序首先会发生错误呢?难道cpu就不能自己跟踪订购情况吗?这难道不是我们最初就有电脑来记录事情的原因吗?
许多人确实希望他们的电脑能跟踪事情,但也有许多人坚持认为他们要快速跟踪事情。事实上,对性能的关注是如此强烈,以至于现代cpu非常复杂,这从图15.1中的简化方框图中可以看出。那些需要从他们的系统中挤出最后几个百分点的性能的人,反过来,在调整他们的软件时,也需要密切关注这个数字的细节。除了这种对细节的密切关注意味着当一个给定的CPU随着年龄的增长而退化时,软件将不再在它上快速运行。例如,如果最左边的ALU失败,经过调优以充分利用所有ALU的软件可能比未调优的软件运行得更慢。解决这个问题的一个方案是,一旦系统的任何cpu开始退化,就停止服务。
另一种选择是回顾第3章的经验教训,特别是对于许多重要的工作负载,主内存无法跟上现代cpu,而现代cpu可以在从内存中获取单个变量所需的时间内执行数百个指令。对于这样的工作负载,CPU的详细内部结构是无关的,
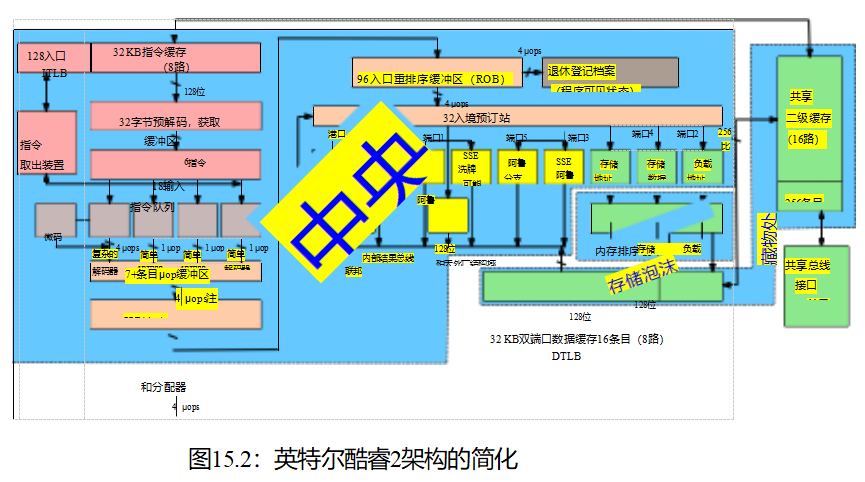
CPU可以用图15.2中标记的CPU、存储缓冲区和缓存来近似。
因为这些数据密集型工作负载,CPU运动越来越大的缓存,如图3.11,这意味着尽管第一个加载由给定的CPU从一个给定的变量将导致一个昂贵的缓存错过3.1.6节中讨论,随后重复加载变量,CPU可能很快执行,因为初始缓存错过将变量加载到CPU的缓存。
但是,也需要容纳从多个cpu到一组共享变量的频繁并发存储。在缓存相干系统中,如果缓存包含给定变量的多个副本,则该变量的所有副本必须具有相同的值。这对于并发加载工作得非常好,但对于并发存储却不那么好:每个存储必须对旧值的所有副本做一些事情(另一个缓存丢失!),考虑到有限的光速和物质的原子性质,这将比急躁的软件黑客所希望的要慢。而这些存储字符串则是在图15.2中使用蓝色块标记的存储缓冲区的原因。
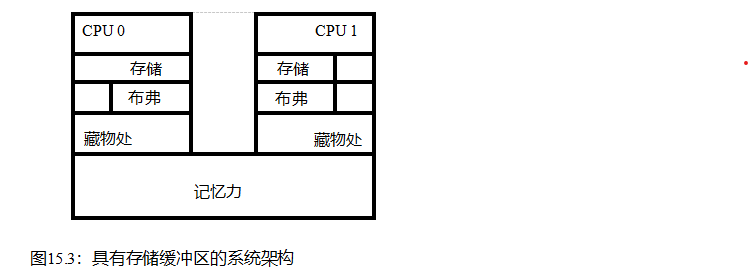
从图15.2中删除内部CPU复杂度,添加第二个CPU,并在图15.3中显示主内存结果。当给定的CPU存储到该CPU缓存中不存在的变量时,那么新值将被放置在该CPU的存储缓冲区中。然后,CPU可以立即继续操作,而不必等待存储区对位于其他CPU缓存中的该变量的所有旧值进行处理。
尽管存储缓冲区可以极大地提高性能,但它们可能会导致指令和内存引用的执行异常,从而导致严重的混乱,如图15.4所示。

特别是,存储缓冲区会导致如清单15.1所示的内存排序错误。
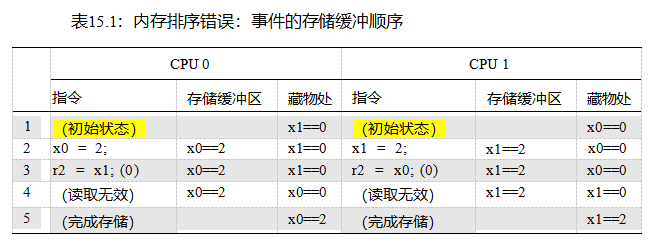
表15.1显示了导致这种错误排序的步骤。第1行显示了初始状态,其中CPU 0在缓存中有x1,CPU1在缓存中有x0,这两个变量的值都为零。第2行显示了由于每个CPU的存储区而引起的状态变化(清单15.1中的第9行和第17行)。因为两个CPU在缓存中都没有存储到变量,所以两个CPU都在各自的存储缓冲区中记录它们的存储。

第3行显示了两个加载项(清单15.1中的第10行和第18行)。因为每个CPU加载的变量在该CPU的缓存中,所以每个加载立即返回缓存值,在这两种情况下都为零。
但是cpu还没有完成:它们迟早必须清空存储缓冲区。
因为缓存移动数据在相对较大的块称为数据线,因为每个数据线可以持有几个变量,每个CPU必须得到数据线到自己的缓存,这样它可以更新的部分数据线对应的变量的存储缓冲区,但不干扰任何数据线的其他部分。每个CPU还必须确保弹轴线不存在于任何其他CPU的缓存中,为此使用读取无效操作。如第4行所示,在两个读取无效操作完成后,两个CPU交换了粗线,因此CPU0的缓存现在包含x0,而CPU1的缓存现在包含x1。一旦这两个变量进入了它们的新家,每个CPU就可以将其存储缓冲区刷新到相应的缓存行中,并保留每个变量的最终值,如第5行所示。

总之,需要存储缓冲区来允许cpu有效地处理存储指令,但它们可能会导致违反直觉的内存排序错误。
但是如果你的算法真的需要它的内存引用,你会怎么做呢?例如,假设您正在使用一对标志与一个驱动程序进行通信,一个标志表示驱动程序是否在运行,另一个标志表示是否在运行
| 1 C C-SB+o-mb-o+o-mb-o 2 3 {} 4 5 P0(int *x0, int *x1) 6 { 7 int r2; 8 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









