







 超级会员免费看
超级会员免费看
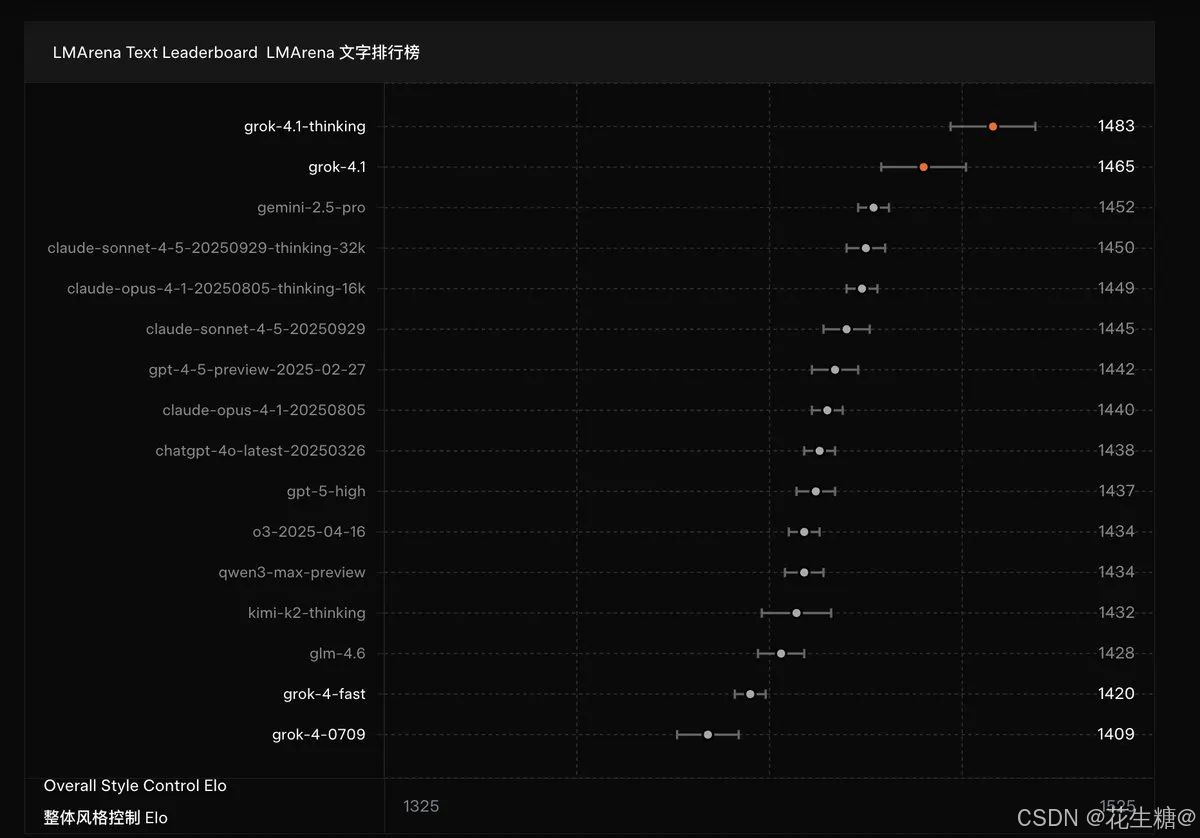 2025年11月,xAI 团队正式推出 Grok 系列最新版本——Grok 4.1。作为 Grok 4 的重要迭代,Grok 4.1 在保持原有大规模强化学习(RLHF)框架的基础上,引入创新的“前沿智能推理模型作奖励模型”机制,显著提升模型在事实一致性、上下文理解与情感连贯性方面的表现。据 LMArena 文本竞技场最新数据显示,Grok 4.1 的 Thinking 版本以 1483 Elo 分高居榜首;而在专注于情感与社交智能评估的 EQ-Bench3 基准中,更是以 1586 Elo 分拔得头筹,展现出其在“走心”交互上的领先优势。
2025年11月,xAI 团队正式推出 Grok 系列最新版本——Grok 4.1。作为 Grok 4 的重要迭代,Grok 4.1 在保持原有大规模强化学习(RLHF)框架的基础上,引入创新的“前沿智能推理模型作奖励模型”机制,显著提升模型在事实一致性、上下文理解与情感连贯性方面的表现。据 LMArena 文本竞技场最新数据显示,Grok 4.1 的 Thinking 版本以 1483 Elo 分高居榜首;而在专注于情感与社交智能评估的 EQ-Bench3 基准中,更是以 1586 Elo 分拔得头筹,展现出其在“走心”交互上的领先优势。
技术亮点:从“能答”到“懂你”
1. 强化学习框架升级:用更强模型做奖励信号
Grok 4.1 沿用了 Grok 4 成熟的大规模强化学习训练架构,但关键突破在于将前沿智能推理模型(如具备强逻辑与事实核查能力的内部模型)作为动态奖励模型。传统 RLHF 通常依赖人类标注或静态评分模型,而 Grok 4.1 通过让高阶推理模型实时评估生成内容的事实准确性、逻辑严密性与语境适配度,实现更精细、更智能的反馈闭环。这一机制有效抑制了“幻觉”(hallucination)问题,在保持创造力的同时大幅提升回答可靠性。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











