




前一段时间,工作内容陷入了瓶颈,不知道自己想干啥了,总会有些重复性较强的工作。虽然也有些空闲时间看看其他东西,但发现看的东西越多,越发感到迷茫。不清楚自己该学什么,该看什么东西,或者说对自己未来的发展道路、发展方向有一点迷茫,不确定未来方向。
顺其自然地,有一些想法,不吐不快罢,也顺便讲下自己的一些心得体会,希望能帮助大家少走些弯路。
个人之言,也不是啥大佬哈,有相似或不同想法的,欢迎各位留言交流。
初识AI
5年前,刚上研究生的时候,AI、深度学习、人工智能刚开始火起来。对深度学习啥也不懂的我,不知从哪儿找了李宏毅那个时候比较火的一个介绍深度学习的PPT,叫做《一天搞懂深度学习》,恐怖如斯。整整300页,我断断续续看了一天,虽然有点蒙逼,总算对深度学习有了一点点了解。

一天搞懂深度学习-李宏毅
当晚回去立马百度了下该学什么,看了很多前辈的帖子,最后从闲鱼上淘了几本书:
- 《周志华的机器学习》
- 《机器学习实战》
- 《TensorFlow实战Google深度学习框架》
- 《深度学习》(大家熟知的圣经)
这几本书之前有介绍过,这里再提下,《周志华的机器学习》都是理论,《机器学习实战》主要是代码实战,这两本书可以配合起来看。然后再看《深度学习》圣经这本书,差不多会对机器学习、深度学习有一定的理解,这些书放到现在都依然合适。

周志华和深度学习圣经
其中最没用的就是《TensorFlow实战Google深度学习框架》,那会Pytorch还不出名,大家都是直接上手TensorFlow,跟着书或者教程学习很费劲,这与TensorFlow静态图的设计有很大关系(不过实话实说TF的静态图设计很优秀,比如dynamic分支的实现),加上TF各种经常变化的API,学起来难度极大。
偶然一个机会看到Pytorch(那会Pytorch刚出来0.2版本),看了下示例代码,感觉很清爽,学了一阵顺利复现了一个基于keras的小项目,就认定Pytorch了。
后来Pytorch出来0.4、1.0,到现在的1.12。无论是在学术界还是工程界,Pytorch相比TensorFlow来说已经很不差了,强烈建议新入门的小伙伴直接上手Pytorch。至于TF1或者TF2好不好用,智者见智仁者见仁,我的建议还是Pytorch。
归根结底,不论是Pytorch还是TensorFlow都只是你学习的一个工具,而且这俩库都很牛逼,哪个你用的舒服,就用哪个就对了。不顺手就扔掉,只不过现在 tf1还是tf2可能都没有Pytorch顺手,所以用Pytorch上手的人更多,更有甚者, import torch as tf
除了上述这些资料,还看了其他的书和资料:
- 程序员的数学系列(线性代数、数学、概率论)
- OpenCV系列(星云大佬、OpenCV3官方文档)
- C++各种乱七八槽的书(primer、effective、more effective)
- 图像处理相关的书

程序员的数学系列
就这样看看学习视频、看看相关的书、看看代码,学一段时间就入门了。
2017年那会资料就挺多了的,现在2022资料只会更多,不过伴随而来的就是不知道看哪个了,可以按照我的建议来看,也可以自己按照自己喜欢的看,其实看啥都能入门,就是是否系统、或者学习时间快慢的问题,没必要纠结非要最好最快的,行动起来才是关键
深度学习 && CV
初步入门之后,决定做图像方向的深度学习,无论是那会还是现在,CV深度学习的热度和资料都比NLP要高不少,虽然学习难度低一些,但学习的人也很多,同样很卷。
所以说选择很重要。一开始选择Pytorch上手算是比较正确的选择;而一开始学CV,最近几年就不是很吃香了,除了CV本来就非常卷,另外因为transformer的大火,很多NLP、语音识别类的应用也随之不断冒出来了,生态都很不错。很多比赛也是搞一些transformer系列的模型,而很多CV类的模型,比如检测场景,做的人太多了,已经有点审美疲劳了。
现在来看,CV方向还是有很多有意思的项目,比如mediapipe,里头集成了很多有意思的CV应用,已经覆盖大部分场景了。NLP的话,我本身也对transformer感兴趣,一直没有时间好好看一个transformer的项目,近期打算好好看下。
话说回来,在入门后,后续又看了些比较有名气的课:
- 吴恩达的机器学习课
- CS231n
可能还看了别的但是不记得了,印象比较深的就这俩,吴恩达的课太偏理论,看的我快睡着了;CS231n的课质量很高,干货超多,作业也很有质量,这个是强烈推荐初学者去过一遍的,不过难度会稍微大一点。
然后也可以跑几个项目,我是先用Pytorch复现了几个用keras搭的项目,然后自己跑了跑一些检测模型(那会比较火的是faster-R-CNN、Mask-R-CNN、YOLOv1-YOLOv3、SSD等),也有一些其他的风格迁移、GAN、图像分割相关任务,总之都过一遍就了解了差不多了。
现在也是一样,无非就是换了一批明星,可能是YOLOX、YOLOv5、Centernet、CornerNet等等。其他任务也是类似,深度学习领域模型发展的也很快,一年一个baseline,但是我对这些设计这些算法不是很感兴趣(虽然人家设计确实巧妙),哪个好就用那个呗。
大概就是这些,我那会没有报任何收费的培训班,好像从闲鱼买过一些盗版课(记得是优达学城的),其他的就都是公开免费的了,再推荐一次CS231N,这门课的质量真的是很高,英文好的建议直接看英文版。
关于算法工程师和训练
在实际业务中,我们会针对场景训练模型,不过大部分的业务场景,比如说你要实现一个检测人的模型,我们要做的其实就三件事儿:
- 收集数据(从公司的query中找,通过脚本或者人力来筛选)
- 整理数据、标注数据、制作label
- 挑选模型进行训练、调优
其实吧,收集数据和整理数据花费的时间最多,而训练在你熟悉或者有自己的一套框架之后,分分钟搞定。所以真实情况就是这样:
- 收集数据和整理数据制作label,每个新任务新场景都会重头来一遍,不过如果这个流程熟悉了,你有脚本可以自动化了,其实也挺快的
- 配环境、解环境bug;一开始配环境比较耗时,配好之后下次就直接用了,或者,人生苦短,我用docker
- 设计模型,做实验,分析loss,再跑几个实验。大部分任务你直接套一个框架(yolo系列、centernet系列、fcos系列),初版没什么问题,剩下的就是根据产品反馈的badcase来针对性优化了
当这套框架定型之后,大部分新的业务来了,直接按照流程来整体进度是很快的,唯一慢的步骤可能是标注,毕竟标注数据是无法完全自动化的。
其实训练这个活,相关领域你熟悉了,之后的大部分任务都可以快速上手,没啥难度。假如遇到个新的任务,直接github上找个开源库clone下来根据实际业务修改下就行了。虽然说可以自己实现吧,但现实中没有时间让你慢慢搞慢慢预研的。怎么快怎么来,如何快速产出才是最重要的。
至于算法能不能搞,行不行,卷不卷,我的看法是一直很卷。而且因为疫情,现在几乎所有岗位都缩减不少,目前找工作来说难度可是真的大(真的大)。算法肯定还是有需求,门槛的话,没有那么高,训练模型这一整套流程,只要有点基础熟悉起来还是很快的。至于开发新的算法,说实话确实很牛逼,只是大部分场景下不需要,很多业务场景算法做到极致还是比较难的,从0-90提升好说,从98-99就难的很了。大部分的瓶颈也在训练数据,模型的改动后期对精度的影响微乎甚微。
相关的话题,感兴趣的可以看我之前写作的两篇:
最近也给我推送了一些新闻,也不知道是真是假。不过可以肯定的是,不管是阿里的达摩院、华为的2012实验室啥的,我问了一些在里头的朋友,搞的和咱们正常算法工程师相差不大。人家可能更注重发paper,搞预研,咱们可能更注重实际业务需求,但都是用Pytorch呀、TF呀,跑一些算法,改改结构、弄弄数据,都差不多。
阿里算法被裁?
总的来说,算法工程师这个需求还是有的,毕竟深度学习在CV和NLP领域都有很多很好的应用。会用、用的好、会根据实际场景选取不同的模型,产出模型并且实际部署应用起来,会这些就可以满足算法工程师的基本要求了。
AI部署
在工作还有在学校的一段时间,我都做了一些部署的工作,也写了几篇关于部署的文章(当然还有有很多坑没填):
AI部署简单来说就是将训练好的模型放在各种平台运行,不过:
- 平台很多(PC端、移动端、服务器、编译端侧、嵌入式)
- 模型种类也很多(检测、识别、NLP、分类、分割、GAN)
- 要求也很多(速度快、稳定、功耗低、占用内存小、延迟度)
- 场景也很多(单模型、多模型分时调用、多模型pipeline、复杂模型前后处理pipeline)
- 会遇到各种问题(结果对不上、动态库ABI不兼容、性能问题)
部署场景多种多样,和算法相比更偏向于实际一点,好的算法能够解决问题,形成一套方案,但是方案的实施,就需要部署了。现在部署的概念我认为其实很杂很泛,你训好了一个模型,用flask + pytorch搭了一个服务给外部调用,就是部署;你把一个模型转化为TensorRT,然后写了个C++服务跑起来,也是部署;你把Pytorch的模型迁移到Caffe中烧录到板子里头,也是部署。
部署不一定非要写C++,也不一定非要使用TensorRT这种高性能库,不过既然你都部署了,性能当然是越高越好嘛。要深入底层去优化模型,那么C++和一些其他的高性能库就少不了了。
部署我认为当下还是很重要的,各种需要部署AI模型的设备:
- 手机(苹果的ANE、高通的DSP、以及手机端GPU)
- 服务端(最出名的英伟达,也有很多国产优秀的GPU加速卡)
- 电脑(intel的cpu,我们平时使用的电脑都可以跑)
- 智能硬件(比如智能学习笔、智能台灯、智能XXX)
- VR/AR/XR设备(一般都是高通平台,比如Oculus Quest2)
- 自动驾驶系统(英伟达和高通)
- 各种开发板(树莓派、rk3399、NVIDIA-Xavier、orin)
- 各种工业装置设备(各种五花八门的平台,不是很了解)
- 其他等等
坑都不少,需要学习的也比较杂,毕竟在某一个平台部署,这个平台的相关知识相关信息也要理解,不过有一些经验是可以迁移的,因此经验也比较重要,什么AI部署、AI工程化、落地都是一个概念。能让模型在某个平台顺利跑起来就行。
部署也不是什么方向,或者说,公司招人的时候也不会搞个“AI部署工程师”的岗位,不像后端、前端这种相对比较固定,职责相对比较专一。而部署呢,相对来说干的活会比较杂一些:
- 中小公司来说,算法工程师也会做部署的事情,毕竟也是工程师嘛
- 大公司来说,会拆的比较细。除了算法工程师,其他岗位,如深度学习工程师、AI-SDK工程师、AI算法系统工程师、端智能应用工程师、AI平台开发工程师、AI框架工程师、高性能计算工程师、AI解决方案工程师等等都会重点做部署的工作,相比于传统的算法工程师,他们一般不训练模型,只会针对模型进行部署或者写一些与模型部署密切相关的组件等等
- 其实不管大公司还是小公司,关于部署的界限也没有那么死,要灵活起来也是非常的灵活
虽然比较杂吧,但这是确确实实的实际落地的工作,不管怎么吹,模型跑到实际的设备上才是最重要的。关于这方面,脏活累活也有很多,比如:
- 模型能不能转成功、能不能跑起来,跑起来之后的速度、精度、占用内存有没有问题
- 模型这个算子在这个平台上没有实现,怎么办,怎么解决,怎么workaround
- 硬件版本、软件版本、SDK版本,匹配不匹配,各种换各种试
- 遇到各种奇奇怪怪的bug,比如多个模型抢占资源,比如某个模型会core
等等等等。
说了这么多,其实我目前也不清楚自己最感兴趣的方法到底是什么,虽然平时的工作也与上面介绍的有一些关系。接下来我也会梳理下自己曾经做过的一些小项目,整理出来,可能是一系列文章,也可能是一个开源库,总之,我再想想。
AI编译器
AI编译器是我一直向往的,原因也很简单,大家都会对未知的、新鲜的东西感兴趣。不过我这辈子可能也就是向往了哈哈。
AI编译器涉及到的技术栈很多,基本的深度学习、编程语言、编译原理、计算机系统原理,再细分C++、编译优化、函数式编程、LLVM等等,需要看的东西很多,没有系统学习过的直接上手学习难度很高。
2022年,AI编译器比之前火了不少,大家听说过的可能有torchscript、Glow、XLA、TVM、MLIR、TensorRT等等。我一开始接触的是TVM,那会并不是很懂AI编译器具体是干啥的,只知道比较牛逼高级一点。简单来说,就是加载一个模型文件(比如ONNX模型),然后输出包含网络结构的序列化好的运行包,我们可以在自己的应用上包含这个和对应AI编译器的运行时so,就可以推理运行了。
再具体点,和编译器类似,AI编译器输入神经网络(前端代码),进行一些优化(计算图优化、公共表达式合并、loop unrolling等),输出可以加载运行的网络文件(可执行文件)。一般来说经过AI编译器优化的神经网络,速度会比直接在原始框架要快一些(Pytorch、TensorFlow),究其原因也是AI编译器所做的一些图优化工作和生成的算子性能要比原生的框架实现要好。
那会也写过两篇介绍TVM的文章:
AI编译器很像黑盒子,一开始用的时候也不管那么多,总之能让自己的模型性能提升就是好事儿,后续渐渐深入研究了一下,学问真的不少。很多算子优化的细节,如果对指令集或者编译器不了解的话,肯定是一头雾水,还是需要花时间研究一下,不需要太深,知道其大致工作原理就可以了,具体的细节什么的,有需要的时候再重点看。
举个简单的例子,TVM在优化模型的时候,会按照设定的规则搜索优化空间,而这个规则我们有必要了解下。可以使用TVM中的TVMScript,类似于python的语法去写kernel(指高性能、手写的CPU或者GPU算子),运行在各种硬件平台,比如我们写一个简单的向量加法:
# 以下是一个简单的向量相加
@tvm.script.ir_module
class Vector:
@T.prim_func
def main(A: T.Buffer[(256,), "float32"], B: T.Buffer[(256,), "float32"], C: T.Buffer[(256,), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
for i0 in T.serial(256):
with T.block("C"):
x = T.axis.spatial(256, i0)
T.reads(A[x], B[x])
T.writes(C[x])
C[x] = A[x] + B[x]
# 写好kernel后,使用tvm.build编译
mod = tvm.build(Vector, target="llvm")
这个kernel使用LLVM进行编译,运行在CPU端。在调用tvm.build后会调用LLVM编译器进行编译,你编译的最终代码性能和你写的这个kernel有很大关系,我们可以通过打印LLVM-IR来查看:
# 查看TVM生成的LLVM-IR
print(mod.get_source())
原始的没有使用vector指令只使用标量指令的IR如下:
; Function Attrs: nofree noinline norecurse nosync nounwind
define internal fastcc void @main_compute_(i8* noalias nocapture align 128 %0, i8* noalias nocapture readonly align 128 %1, i8* noalias nocapture readonly align 128 %2) unnamed_addr #1 {
entry:
%3 = bitcast i8* %2 to <4 x float>*
%wide.load = load <4 x float>, <4 x float>* %3, align 128, !tbaa !113
%4 = getelementptr inbounds i8, i8* %2, i64 16
%5 = bitcast i8* %4 to <4 x float>*
%wide.load2 = load <4 x float>, <4 x float>* %5, align 16, !tbaa !113
%6 = bitcast i8* %1 to <4 x float>*
%wide.load3 = load <4 x float>, <4 x float>* %6, align 128, !tbaa !116
%7 = getelementptr inbounds i8, i8* %1, i64 16
# 省略很多 类似的读取+加法+赋值操作
store <4 x float> %443, <4 x float>* %447, align 16, !tbaa !119
ret void
}
如这时候使用TVM的Schedule,来将我们刚才写的这个script中的重要loops进行向量化,也就是将这个操作的C维向量化:
# TensorIR 使用schedule
sch = tvm.tir.Schedule(Vector)
# 得到那个名称为 C 的loop
block_c = sch.get_block("C")
# 获取loop的维度
(i,) = sch.get_loops(block_c)
# 向量化这个维度
sch.vectorize(i)
向量化之后的TVMScript为:
@tvm.script.ir_module
class Module:
@T.prim_func
def main(A: T.Buffer[(256,), "float32"], B: T.Buffer[(256,), "float32"], C: T.Buffer[(256,), "float32"]) -> None:
# function attr dict
T.func_attr({"global_symbol": "main", "tir.noalias": True})
# body
# with T.block("root")
for i0 in T.vectorized(256): # 这里使用了向量化命令
with T.block("C"):
x = T.axis.spatial(256, i0)
T.reads(A[x], B[x])
T.writes(C[x])
C[x] = A[x] + B[x]
调用向量指令后,打印的LLVM-IR如下,可以看到LLVM-IR按照你的要求将这个操作向量化了:
; Function Attrs: mustprogress nofree noinline norecurse nosync nounwind willreturn
define internal fastcc void @main_compute_(i8* noalias nocapture align 128 %0, i8* noalias nocapture readonly align 128 %1, i8* noalias nocapture readonly align 128 %2) unnamed_addr #1 {
entry:
%3 = bitcast i8* %2 to <256 x float>*
%4 = load <256 x float>, <256 x float>* %3, align 128, !tbaa !113
%5 = bitcast i8* %1 to <256 x float>*
%6 = load <256 x float>, <256 x float>* %5, align 128, !tbaa !127
%7 = fadd <256 x float> %4, %6
%8 = bitcast i8* %0 to <256 x float>*
store <256 x float> %7, <256 x float>* %8, align 128, !tbaa !141
ret void
}
使用这个LLVM-IR最终生成的汇编代码,就会使用该CPU上的的向量指令,比如SSE、AVX2等等,相比原始的标量操作会快不少。
这只是其中一部分的细节,涉及到的知识已经有很多,比如LLVM、CPU指令集等等,想要好好深入的话,是需要花费一定的精力的。
对于AI编译器,我了解的也不是很深,不过通过这几年的尝鲜到常用,发现这些工具确实在某些场景下是有一定用处的。比如某些corner case,常见的卷积shape已经有很多人工写的kernel库去做(cudnn、cublas),但是不常见的卷积shape直接使用这些kernel库性能就差些了,这个时候就可以使用AI编译器设定shapes自动搜索,比自己写的话,人力和时间成本都要低很多。
当然AI编译器还有很多其他的用法,很多初创公司使用TVM作为自家硬件的编译器,通过修改中端、后端去适配自己的硬件,快速搭建一套适合自家硬件的AI编译器给客户使用。通过AI编译器生成的op算子,对于刚开始出生的硬件来说,可能比人工手写性能好的概率更高一些。
AI编译器,之前花了不少时间去研究,之后也会花些时间研究,不过也不是专职commit的,之后会尝试更多地向开源社区贡献下,写一些关于TVM的文章。
之前也有很多小伙伴想和我一起学TVM,但因为种种原因没有坚持下来(我也是),毕竟自身时间是有限,学习期间会被各种东西干扰,尤其是还有工作。其实学习这个东西大部分人不可能一直有大把时间投入的,我们只要坚持学就好,慢慢来,有时间就看看。
硬件底层
本科时我是搞嵌入式的,那会学51、学stm32,也参加一些乱七八槽的电子类比赛。后来研究生时期选择了深度学习方向,出于对硬件的兴趣,除了训练也会做一些工程类的项目,搞过的板卡有树莓派、jetson-TX2、FPGA等。
依稀记得本科那会,51是89C51、stm32是stm32f103zet6(或者c8t6),一个8位、一个32位。学习嵌入式对理解计算机原理有大的帮助,51或者stm32都是小型计算机了,只不过缺少运行os的必要单元,只能跑跑RTOS(ucos-ii这种的)。后来更高级点的树莓派系列就可以跑Ubuntu了。
抛开这些比较简单的单片机,现在我们使用的GPU,比如NVIDIA的显卡,结构就复杂不少,指令集更多、寄存器也更多,支持的功能也相应更多,想要实现极致的性能,就需要对芯片架构特别了解,通过intrinsics或者汇编实现应用的性能。不过做到这一点,门槛和难度大的不是一点半点。
不过所幸NVIDIA提供了很强大的编译器NVCC,提供了用于并行异构计算的编程模型CUDA (Compute Unified Device Architecture) ,也就是我们熟知的GPU编程。通过编写C++和C语言代码就可以实现性能很不错的CUDA代码,我们目前使用的CUDA代码大部分也不需要嵌入汇编,这与CUDA的优秀脱不了关系。
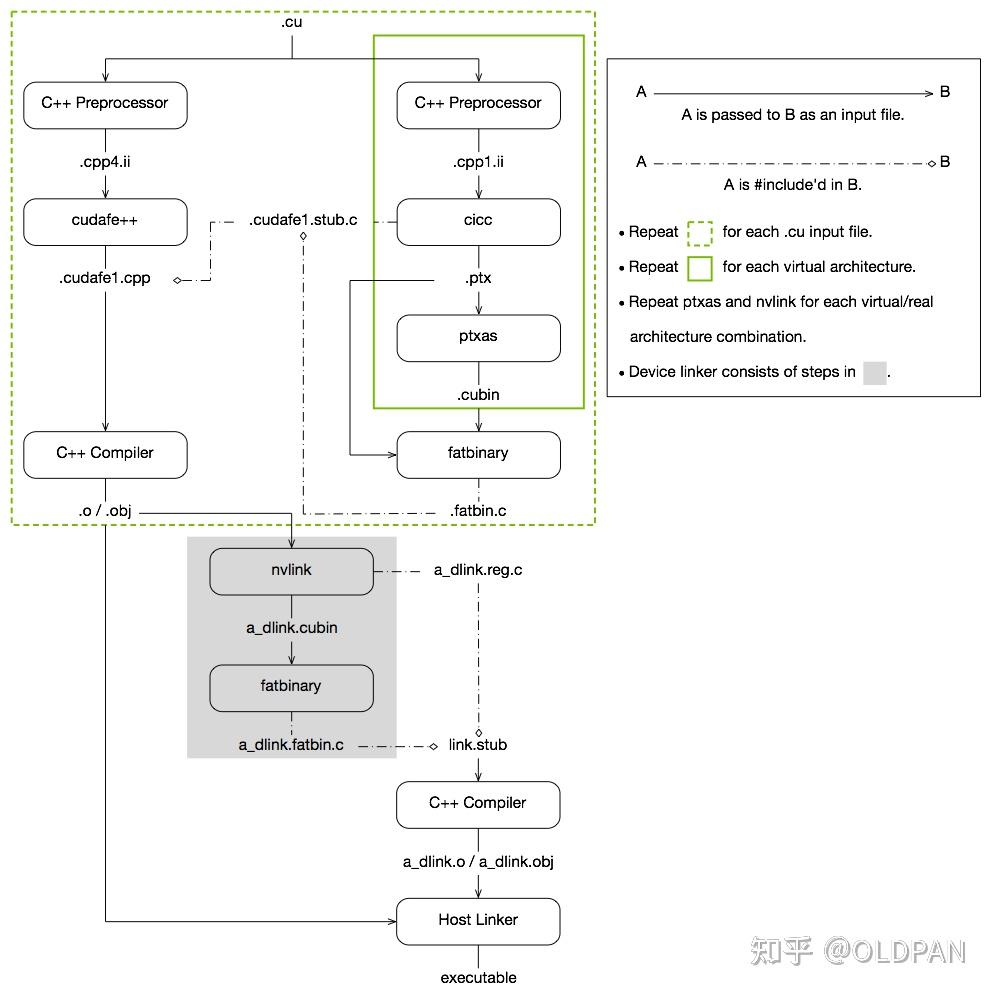
NVCC编译流程
硬件是挺有意思的,各式各样的硬件,CPU、GPU、NPU、VPU、DSP,每个硬件架构设计也各不相用。比如CPU的向量化是SIMD,而GPU的多线程是SIMT,hexagon DSP则使用VLIW超长指令集去实现并行...
精通其中某一方向都是需要大把时间努力的,想要写出极致性能的算子就需要对使用的硬件特别的了解。不过现在比较好的是深度学习编译器的发展,自动生成的算子大概能满足80%的场景,很多场景不需要手动去写intrinsics或者汇编,利用生成的算子差不多能达到与纯手工优化媲美的性能。
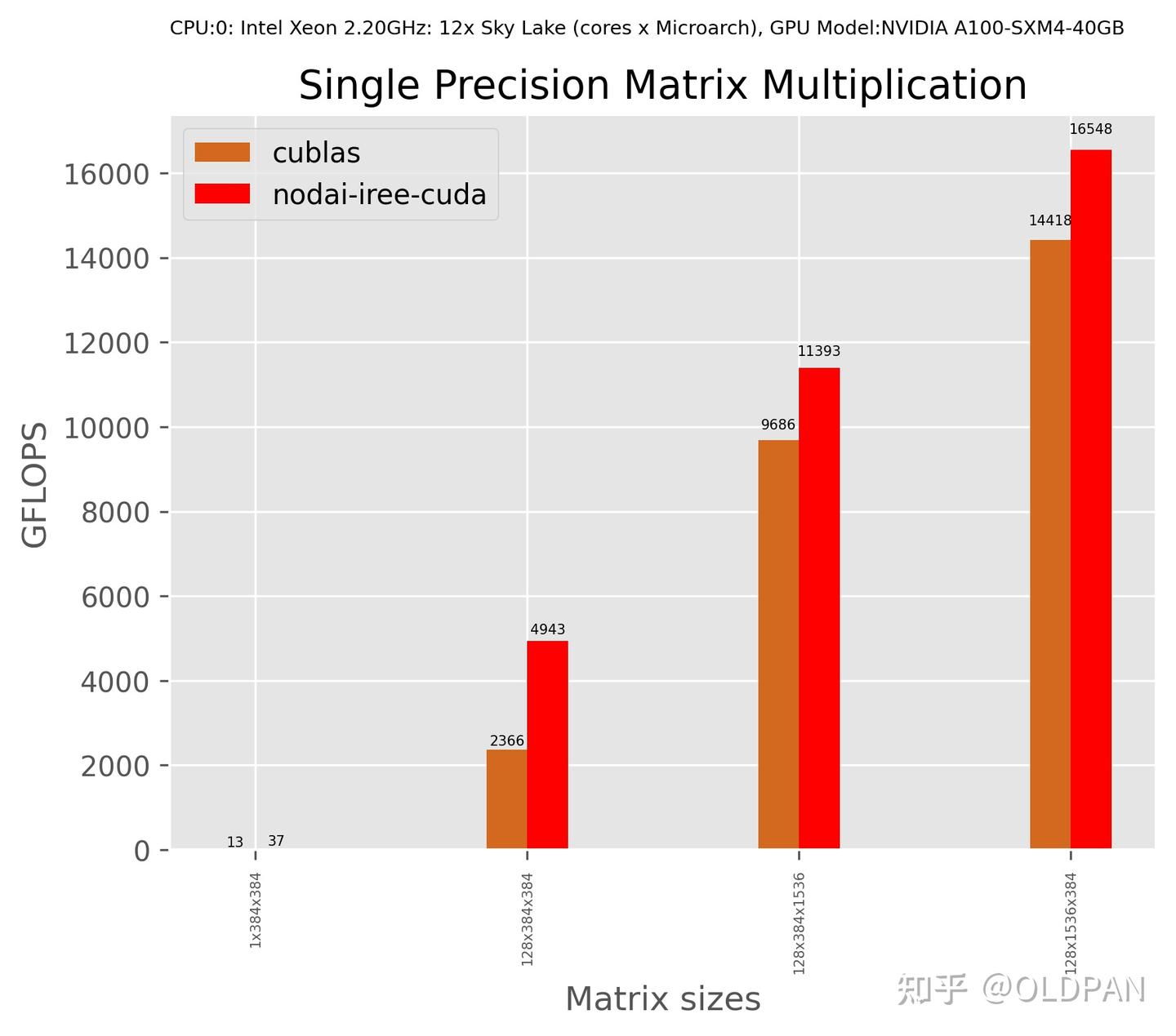
cublasVSiree-cuda
硬件底层这个方向,个人感觉如果基础打好,很多知识是可以迁移的,最近也在抽空看一本《计算机体系结构——量化研究方法》的书。看的比较吃力,但是偶尔看看发现很多硬件都有相似的地方,比如GPU的一个warp32个thread的硬件线程,和DSP的一个cluster两个硬件线程有类似的地方。
手机这种移动端AI部署落地也是目前需求较高的一个方向,毕竟手机芯片也是年年要更新的,关于这方面要学习的有很多,算法SDK、算法移植、算法op优化、甚至具体到芯片层面,arm的指令、gpu、npu、dsp的优化等等要做的东西很多很多,
计算机原理、计算机组成原理、汇编原理、深入理解计算机原理...这些基础看看看完对于大部分的硬件都会有个直观的印象。
哎,要看的东西太多,慢慢看吧。
就业方向
很多小伙伴问我,老潘我该学什么啊,我这样做对不对啊,我学这个对以后找工作有没有帮助啊等等。我只能这个说看情况,面试要准备什么要问什么问题这个分公司,不同公司不同jd侧重点也不一样。而且这个很看个人,每个人喜欢的也不一样,比如说我喜欢的大概方向是部署,对于训练没有那么热衷,喜欢一些比较实际的东西。
所以也看个人的兴趣爱好,想做哪些点,比如部署的方向也有很多,如果不知道方向可以先把基础打好,C++基础、深度学习基础、计算机原理、编译原理、硬件什么的基础打好吧。可以先慢慢来,一般一开始也不清楚自己喜欢什么想要什么,还是要慢慢看才会明白自己到底对什么感兴趣。
之后在深入,可以根据自己的兴趣方向选择以下几个学习点:
- 对算法、特征、业务、实际算法场景感兴趣,可以专注深度学习各种算法知识(识别、检测、分类、校准、损失函数),然后基于这些知识解决实际的问题,可以训练模型,也可以结合传统图像或者其他方法一起解决。现实生活中的问题千奇百怪,一般只使用一个模型解决不了,可能会有多个模型一起上,解决方法也多种多样
- 对AI落地、部署、移植、算法SDK感兴趣,可以多看工程落地的一些知识(C++、Makefile、cmake、编译相关、SDK),多参与一些实际项目攒攒经验,多熟悉一些常见的大厂造的部署轮子(libtorch、TensorRT、openvino、TVM、openppl、Caffe等),尝试转几个模型(ONNX)、写几个op(主要是补充,性能不要最优)、写几个前后处理、debug下各种奇葩的错误,让模型可以顺利在一些平台跑起来,平台可以在PC、手机、服务器等等;
- 对算子优化、底层硬件实现实现感兴趣的,可以重点看某一平台的硬件架构(CPU、GPU、NPU、VPU、DSP),然后学学汇编语言,看看内存结构,看看优化方法等等,做一些算子的优化,写一些OP啥的,再者涉及到profile、算子优化、内存复用等等。
- 当然还有模型压缩、模型剪枝、量化、蒸馏,这些其实也是部署的一部分,根据需要掌握即可。
以上只是不完全概括,差不多是这个样子。很多情况下上述几个都可以参与都可以做,没有分那么绝对。去了公司你就是解决问题的人,来什么问题就解决什么问题,对于很多业务场景也不需要每一项都很牛逼,掌握80%就够用了。
另外,除了工程技术这些硬能力,个人感觉还需要一些软实力,随着我们慢慢地成长,有时候会发现技术并不能解决所有事,或者说靠自己一个人并不能完成一个比较大的任务。因此也需要考虑下这些点:
- 了解产品需求。如何将需求转化为实际的产品,咱们不能光知道开发,贴近实际的使用者是最好的,虽然在公司有PM来弄了,但是如果你可以以用户的角度来设计工具的话,或许会更好
- 和各种人打交道的能力,开发代码不是一个人的事儿,一个大的项目肯定是好几个人共同努力的结果,需要沟通联调各个部门,协商一些问题,合作开发代码等等
- 影响力,个人品牌,多写写文章、多帮助帮助他人、多参与一下开源、参与一下贡献,都是不错的
想躺平,还是走出舒适区,还得看你自己。
后记
偶然在知乎上看到程序员35岁这个梗,这个看到过好多次,对此目前也没有什么想法。能做的,也就是提前想想路子,同时学习学习。虽然未来五年、或者未来两年技术会发展成什么样,我们是无法预测的,但我们可以把自身的基础打好,然后再适应接下来的挑战。
加油吧!
看到这里了,感谢你听老潘的唠叨,你说我文章又臭又长也罢、废话也多也罢,总之我是把我的想法都写出来了,赞同的,点个赞,不赞同的,欢迎留言哦。
参考资料
- https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
- the-future-of-hardware-is-software
- https://blog.youkuaiyun.com/shungry/article/details/89715468
- 算法工程师的落地能力具体指的是什么?
原文发于公众号,欢迎关注交流:
原文来源于老潘的博客:
Hello我是老潘,好久不见各位。
最近在复盘今年上半年做的一些事情,不管是训练模型、部署模型搭建服务,还是写一些组件代码,零零散散是有一些产出。
虽然有了一点点成果,但仍觉着缺点什么。作为深度学习算法工程师,训练模型和部署模型是最基本的要求,每天都在重复着这个工作,但偶尔静下心来想一想,还是有很多事情需要做的:
- 模型的结构,因为上线业务需要,更趋向于稳定有经验的,未探索一些新的结构
- 模型的加速仍然不够,还没有压榨完GPU的全部潜力
深感还有很多很多需要学习的地方啊。

既然要学习,那么学习路线就显得比较重要了。
本文重点谈谈学习AI部署的一些基础和需要提升的地方。这也是老潘之前学习、或者未来需要学习的一些点,这里抛砖引玉下,也希望大家能够提出一点意见。
AI部署
AI部署这个词儿大家肯定不陌生,可能有些小伙伴还不是很清楚这个是干嘛的,但总归是耳熟能详了。

近些年来,在深度学习算法已经足够卷卷卷之后,深度学习的另一个偏向于工程的方向--部署工业落地,才开始被谈论的多了起来。当然这也是大势所趋,毕竟AI算法那么多,如果用不着,只在学术圈搞研究的话没有意义。因此很多AI部署相关行业和AI芯片相关行业也在迅速发展,现在虽然已经2021年了,但我认为AI部署相关的行业还未到头,AI也远远没有普及。
简单收集了一下知乎关于“部署”话题去年和今年的一些提问:



提问的都是明白人,随着人工智能逐渐普及,使用神经网络处理各种任务的需求越来越多,如何在生产环境中快速、稳定、高效地运行模型,成为很多公司不得不考虑的问题。不论是通过提升模型速度降低latency提高用户的使用感受,还是加速模型降低服务器预算,都是很有用的,公司也需要这样的人才。
在经历了算法的神仙打架、诸神黄昏、灰飞烟灭等等这些知乎热搜后。AI部署工业落地这块似乎还没有那么卷...相比AI算法来说,AI部署的入坑机会更多些。

当然,AI落地部署和神经网络深度学习的关系是分不开的,就算你是AI算法工程师,也是有必要学习这块知识的。并不是所有人都是纯正的AI算法研究员。
聊聊AI部署
AI部署的基本步骤:
- 训练一个模型,也可以是拿一个别人训练好的模型
- 针对不同平台对生成的模型进行转换,也就是俗称的parse、convert,即前端解释器
- 针对转化后的模型进行优化,这一步很重要,涉及到很多优化的步骤
- 在特定的平台(嵌入端或者服务端)成功运行已经转化好的模型
- 在模型可以运行的基础上,保证模型的速度、精度和稳定性
就这样,虽然看起来没什么,但需要的知识和经验还是很多的。

因为实际场景中我们使用的模型远远比ResNet50要复杂,我们部署的环境也远远比实验室的环境条件更苛刻,对模型的速度精度需求也比一般demo要高。
对于硬件公司来说,需要将深度学习算法部署到性能低到离谱的开发板上,因为成本能省就省。在算法层面优化模型是一方面,但更重要的是从底层优化这个模型,这就涉及到部署落地方面的各个知识(手写汇编算子加速、算子融合等等);对于软件公司来说,我们往往需要将算法运行到服务器上,当然服务器可以是布满2080TI的高性能CPU机器,但是如果QPS请求足够高的话,需要的服务器数量也是相当之大的。这个要紧关头,如果我们的模型运行的足够快,可以省机器又可以腾一些buffer上新模型岂不很爽,这个时候也就需要优化模型了,其实优化手段也都差不多,只不过平台从arm等嵌入式端变为gpu等桌面端了。
作为AI算法部署工程师,你要做的就是将训练好的模型部署到线上,根据任务需求,速度提升2-10倍不等,还需要保证模型的稳定性。
是不是很有挑战性?
需要什么技术呢?
需要一些算法知识以及扎实的工程能力。
老潘认为算法部署落地这个方向是比较踏实务实的方向,相比设计模型提出新算法,对于咱们这种并不天赋异禀来说,只要肯付出,收获是肯定有的(不像设计模型,那些巧妙的结果设计不出来就是设计不出来你气不气)。
其实算法部署也算是开发了,不仅需要和训练好的模型打交道,有时候也会干一些粗活累活(也就是dirty work),自己用C++、cuda写算子(预处理、op、后处理等等)去实现一些独特的算子。也需要经常调bug、联合编译、动态静态库混搭等等。
算法部署最常用的语言是啥,当然是C++了。如果想搞深度学习AI部署这块,C++是逃离不了的。

所以,学好C++很重要,起码能看懂各种关于部署精巧设计的框架(再列一遍:Caffe、libtorch、ncnn、mnn、tvm、OpenVino、TensorRT,不完全统计,我就列过我用过的)。当然并行计算编程语言也可以学一个,针对不同的平台而不同,可以先学学CUDA,资料更多一些,熟悉熟悉并行计算的原理,对以后学习其他并行语言都有帮助。
系统的知识嘛,还在整理,还是建议实际中用到啥再看啥,或者有项目在push你,这样学习的更快一些。
可以选择上手的项目:
- 好用的开源推理框架:Caffe、NCNN、MNN、TVM、OpenVino
- 好用的半开源推理框架:TensorRT
- 好用的开源服务器框架:triton-inference-server
- 基础知识:计算机原理、编译原理等
需要的深度学习基础知识
AI部署当然也需要深度学习的基础知识,也需要知道怎么训练模型,怎么优化模型,模型是怎么设计的等等。不然你怎会理解这个模型的具体op细节以及运行细节,有些模型结构比较复杂,也需要对原始模型进行debug。
关于深度学习的基础知识,可以看这篇:
常用的框架
这里介绍一些部署常用到的框架,也是老潘使用过的,毕竟对于某些任务来说,自己造轮子不如用别人造好的轮子。

并且大部分大厂的轮子都有很多我们可以学习的地方,因为开源我们也可以和其他开发者一同讨论相关问题;同样,虽然开源,但用于生产环境也几乎没有问题,我们也可以根据自身需求进行魔改。
这里老潘介绍一些值得学习的推理框架,不瞒你说,这些推理框架已经被很多公司使用于生成环境了。
Caffe
Caffe有多经典就不必说了,闲着无聊的时候看看Caffe源码也是受益匪浅。我感觉Caffe是前些年工业界使用最多的框架(还有一个与其媲美的就是darknet,C实现)没有之一,纯C++实现非常方便部署于各种环境。
适合入门,整体构架并不是很复杂。当然光看代码是不行的,直接拿项目来练手、跑起来是最好的。
第一次使用可以先配配环境,要亲手来体验体验。
至于项目,建议拿SSD来练手!官方的SSD就是拿Caffe实现的,改写了一些Caffe的层和组件,我们可以尝试用SSD训练自己的数据集,然后部署推理一下,这样才有意思!
相关资料:
Libtorch (torchscript)
libtorch是Pytorch的C++版,有着前端API和与Pytorch一样的自动求导功能,可以用于训练或者推理。

Pytorch训练出来的模型经过torch.jit.trace或者torch.jit.scrpit可以导出为.pt格式,随后可以通过libtorch中的API加载然后运行,因为libtorch是纯C++实现的,因此libtorch可以集成在各种生产环境中,也就实现了部署(不过libtorch有一个不能忽视但影响不是很大的缺点,限于篇幅暂时不详说)。
libtorch是从1.0版本开始正式支持的,如今是1.9版本。从1.0版本我就开始用了,1.9版本也在用,总的来说,绝大部分API和之前变化基本不大,ABI稳定性保持的不错!
libtorch适合Pytorch模型快速C++部署的场景,libtorch相比于pytorch的python端其实快不了多少(大部分时候会提速,小部分情况会减速)。在老潘的使用场景中,一般都是结合TensorRT来部署,TensorRT负责简单卷积层等操作部分,libtorch复杂后处理等细小复杂op部分。
基本的入门教程:
官方资料以及API:
libtorch的官方资料比较匮乏,建议多搜搜github或者Pytorch官方issue,要善于寻找。
一些libtorch使用规范附:
TensorRT
TensorRT是可以在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。速度提升的比例是比较可观的。
在GPU服务器上部署的话,TensorRT是首选!
TensorRT老潘有单独详细的教程,可以看这里:
OpenVINO
在英特尔CPU端(也就是我们常用的x86处理器)部署首选它!开源且速度很快,文档也很丰富,更新很频繁,代码风格也不错,很值得学习。

在我这边CPU端场景不是很多,毕竟相比于服务器来说,CPU场景下,很多用户的硬件型号各异,不是很好兼容。另外神经网络CPU端使用场景在我这边不是很多,所以搞得不是很多。
哦对了,OpenVino也可以搭配英特尔的计算棒,亲测速度飞快。
详细介绍可以看这里:
NCNN/MNN/TNN/TVM
有移动端部署需求的,即模型需要运行在手机或者嵌入式设备上的需求可以考虑这些框架。这里只列举了一部分,还有很多其他优秀的框架没有列出来...是不是不好选?
个人认为性价比比较高的是NCNN,易用性比较高,很容易上手,用了会让你感觉没有那么卷。而且相对于其他框架来说,NCNN的设计比较直观明了,与Caffe和OpenCV有很多相似之处,使用起来也很简单。可以比较快速地编译链接和集成到我们的项目中。

TVM和Tengine比较复杂些,不过性能天花板也相比前几个要高些,可以根据取舍尝试。
相关链接:
PaddlePaddle
PaddlePaddle作为国内唯一一个用户最多的深度学习框架,真的不是盖。
很多任务都有与训练模型可以使用,不论是GPU端还是移动端,大部分的模型都很优秀很好用。
如果想快速上手深度学习,飞浆是不错的选择,官方提供的示例代码都很详细,一步一步教你教到你会为止。
最后说一句,国产牛逼。
还有很多框架
当然除了老潘这里介绍的这些,还有很多更加优秀的框架,只不过我没有使用过,这里也就不多评论了。

AI部署中的提速方法
老潘这一年除了训练模型,也部署了不少模型。虽然模型速度有提升,但仍然不够快,仍然还有很多空间去提升。
我的看法是,部署不光是从研究环境到生产环境的转换,更多的是模型速度的提升和稳定性的提升。稳定性这个可能要与服务器框架有关了,网络传输、负载均衡等等,老潘不是很熟悉,也就不献丑了。不过速度的话,从模型训练出来,到部署推理这一步,有什么优化空间呢?

上到模型层面,下到底层硬件层面,其实能做的有很多。如果我们将各种方法都用一遍(大力出奇迹),最终模型提升10倍多真的不是梦!
有哪些能做的呢?
- 模型结构
- 剪枝
- 蒸馏
- 稀疏化训练
- 量化训练
- 算子融合、计算图优化、底层优化
简单说说吧!
模型结构
模型结构当然就是探索更快更强的网络结构,就比如ResNet相比比VGG,在精度提升的同时也提升了模型的推理速度。又比如CenterNet相比YOLOv3,把anchor去掉的同时也提升了精度和速度。
模型层面的探索需要有大量的实验支撑,以及,脑子,我脑子不够,就不参与啦。喜欢白嫖,能白嫖最新的结构最好啦,不过不是所有最新结构都能用上,还是那句话,部署友好最好。

哦,还有提一点,最近发现另一种改变模型结构的思路,结构重参化。还是蛮有搞头的,这个方向与落地部署关系密切,最终的目的都是提升模型速度的同时不降低模型的精度。
之前有个比较火的RepVgg——Making VGG-style ConvNets Great Again就是用了这个想法,是工业届一个非常solid的工作。部分思想与很多深度学习推理框架的算子融合有异曲同工之处。
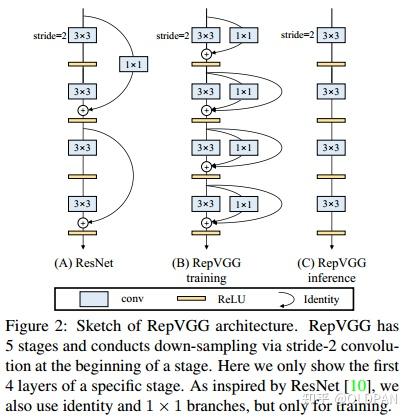
老潘也在项目中使用了repvgg,在某些任务的时候,相对于ResNet来说,repvgg可以在相同精度上有更高的速度,还是有一定效果的。
剪枝
剪枝很早就想尝试了,奈何一直没有时间啊啊啊。
我理解的剪枝,就是在大模型的基础上,对模型通道或者模型结构进行有目的地修剪,剪掉对模型推理贡献不是很重要的地方。经过剪枝,大模型可以剪成小模型的样子,但是精度几乎不变或者下降很少,最起码要高于小模型直接训练的精度。
积攒了一些比较优秀的开源剪枝代码,还咩有时间细看:
蒸馏
我理解的蒸馏就是大网络教小网络,之后小网络会有接近大网络的精度,同时也有小网络的速度。
再具体点,两个网络分别可以称之为老师网络和学生网络,老师网络通常比较大(ResNet50),学生网络通常比较小(ResNet18)。训练好的老师网络利用soft label去教学生网络,可使小网络达到接近大网络的精度。
印象中蒸馏的作用不仅于此,还可以做一些更实用的东西,之前比较火的centerX,将蒸馏用出了花,感兴趣的可以试试。
稀疏化
稀疏化就是随机将Tensor的部分元素置为0,类似于我们常见的dropout,附带正则化作用的同时也减少了模型的容量,从而加快了模型的推理速度。
稀疏化操作其实很简单,Pytorch官方已经有支持,我们只需要写几行代码就可以:
def prune(model, amount=0.3):
# Prune model to requested global sparsity
import torch.nn.utils.prune as prune
print('Pruning model... ', end='')
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):
prune.l1_unstructured(m, name='weight', amount=amount) # prune
prune.remove(m, 'weight') # make permanent
print(' %.3g global sparsity' % sparsity(model))
上述代码来自于Pruning/Sparsity Tutorial 。这样,通过Pytorch官方的torch.nn.utils.prune模块就可以对模型的卷积层tensor随机置0。置0后可以简单测试一下模型的精度...精度当然是降了哈哈!所以需要finetune来将精度还原,这种操作其实和量化、剪枝是一样的,目的是在去除冗余结构后重新恢复模型的精度。
那还原精度后呢?这样模型就加速了吗?当然不是,稀疏化操作并不是什么平台都支持,如果硬件平台不支持,就算模型稀疏了模型的推理速度也并不会变快。因为即使我们将模型中的元素置为0,但是计算的时候依然还会参与计算,和之前的并无区别。我们需要有支持稀疏计算的平台才可以。
英伟达部分显卡是支持稀疏化推理的,英伟达的A100 GPU显卡在运行bert的时候,稀疏化后的网络相比之前的dense网络要快50%。我们的显卡支持么?只要是Ampere architecture架构的显卡都是支持的(例如30XX显卡)。
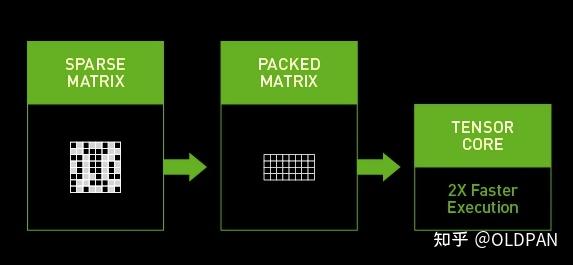
最近的TensorRT8是支持直接导入稀疏化模型的,目前支持Structured Sparsity结构。如果有30系列卡和TensorRT8的童鞋可以尝试尝试~
并且英伟达官方提供了基于Pytorch的自动稀疏化工具——Automatic SParsity,总的流程来说就是:
- 先拿一个完整的模型(dense),然后以一定的稀疏化系数稀疏化这个模型
- 然后基于这个稀疏化后的模型进行训练
- 将训练后的模型导出来即可
是不是很简单?
相关讨论:
- NVIDIA's Tensor-TFLOPS values for their newest GPUs include sparsity
- Pruning BERT to accelerate inference
- Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning
- NVIDIA RTX 3080: Performance Test
量化训练
这里指的量化训练是在INT8精度的基础上对模型进行量化。简称QTA(Quantization Aware Training)。
量化后的模型在特定CPU或者GPU上相比FP32、FP16有更高的速度和吞吐,也是部署提速方法之一。
PS:FP16量化一般都是直接 转换模型权重从FP32->FP16,不需要校准或者finetune。
量化训练是在模型训练中量化的,与PTQ(训练后量化)不同,这种量化方式对模型的精度影响不大,量化后的模型速度基本与量化前的相同(另一种量化方式PTQ,TensorRT或者NCNN中使用交叉熵进行校准量化的方式,在一些结构中会对模型的精度造成比较大的影响)。
举个例子,我个人CenterNet训练的一个网络,使用ResNet-34作为backbone,利用TensorRT进行转换后,使用1024x1024作为测试图像大小的指标:
| 精度/指标 | FP32 | INT8(PTQ) | INT8(QTA) |
|---|
精度不降反升(可以由于之前FP32的模型训练不够彻底,finetune后精度又提了一些),还是值得一试的。
目前我们常用的Pytorch当然也是支持QTA量化的。
不过Pytorch量化训练出来的模型,官方目前只支持CPU。即X86和Arm,具有INT8指令集的CPU可以使用:
- x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
- ARM CPUs (typically found in mobile/embedded devices)
已有很多例子。
相关文章:
那么GPU支持吗?
Pytorch官方不支持,但是NVIDIA支持。
NVIDIA官方提供了Pytorch的量化训练框架包,目前虽然不是很完善,但是已经可以正常使用:
利用这个量化训练后的模型可以导出为ONNX(需要设置opset为13),导出的ONNX会有QuantizeLinear和DequantizeLinear两个算子:

带有QuantizeLinear和DequantizeLinear算子的ONNX可以通过TensorRT8加载,然后就可以进行量化推理:
Added two new layers to the API: IQuantizeLayer and IDequantizeLayer which can be used to explicitly specify the precision of operations and data buffers. ONNX’s QuantizeLinear and DequantizeLinear operators are mapped to these new layers which enables the support for networks trained using Quantization-Aware Training (QAT) methodology. For more information, refer to the Explicit-Quantization, IQuantizeLayer, and IDequantizeLayer sections in the TensorRT Developer Guide and Q/DQ Fusion in the Best Practices For TensorRT Performance guide.
而TensorRT8版本以下的不支持直接载入,需要手动去赋值MAX阈值。
相关例子:
常见部署流程
假设我们的模型是使用Pytorch训练的,部署的平台是英伟达的GPU服务器。
训练好的模型通过以下几种方式转换:
其中onnx2trt最成熟,torch2trt比较灵活,而trtorch不是很好用。三种转化方式各有利弊,基本可以覆盖90%常见的主流模型。
遇到不支持的操作,首先考虑是否可以通过其他pytorch算子代替。如果不行,可以考虑TensorRT插件、或者模型拆分为TensorRT+libtorch的结构互相弥补。trtorch最新的commit支持了部分op运行在TensorRT部分op运行在libtorch,但还不是很完善,感兴趣的小伙伴可以关注一下。
常见的服务部署搭配:
- triton server + TensorRT/libtorch
- flask + Pytorch
- Tensorflow Server
后记
来北京工作快一年了,做了比较久的AI相关的训练部署工作,一直处于快速学习快速输出的状态,没有好好总结一下这段时间的工作内容和复盘自己的不足。所以趁着休息时间,也回顾一下自己之前所做的东西,总结一些内容和一些经验罢。同时也是抛砖引玉,看看大家对于部署有没有更好的想法。
AI部署的内容还是有很多,这里仅仅是展示其中的冰山一角,对于更多相关的内容,可以关注老潘一起交流哈。
看了上述介绍,如果不确定自己的方向的,可以先打打基础,先看看C++/python等,基础工具熟悉了,之后学习起来会更快。

先这样,我是老潘,我们下期见~
文中若有描述不恰当的地方,欢迎指正~

















 6795
6795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









