








论文标题:RETHINKING CHANNEL DEPENDENCE FOR MULTIVARIATE TIME SERIES FORECASTING: LEARNING FROM LEADING INDICATORS
论文链接:https://arxiv.org/pdf/2401.17548
前言
现在很多主流时序模型都是通道独立的,CI(channel independent)的好处在于可以避免过拟合。但是仔细想想多变量之间肯定是有关联的,假设气压升高,温度随后也升高。那实际上气压和温度可能遵循同样的变化模式,只是气压变化领先于温度。
看个例子,下图有三个变量v1v2和v3,他们的变化模式是相同的,但是这种变化模式前后有个"时间差",如果直接用通道依赖,由于时间差的存在,造成聚合不同变量时段内实际的变化模式不一致,间接导致预测目标不同。
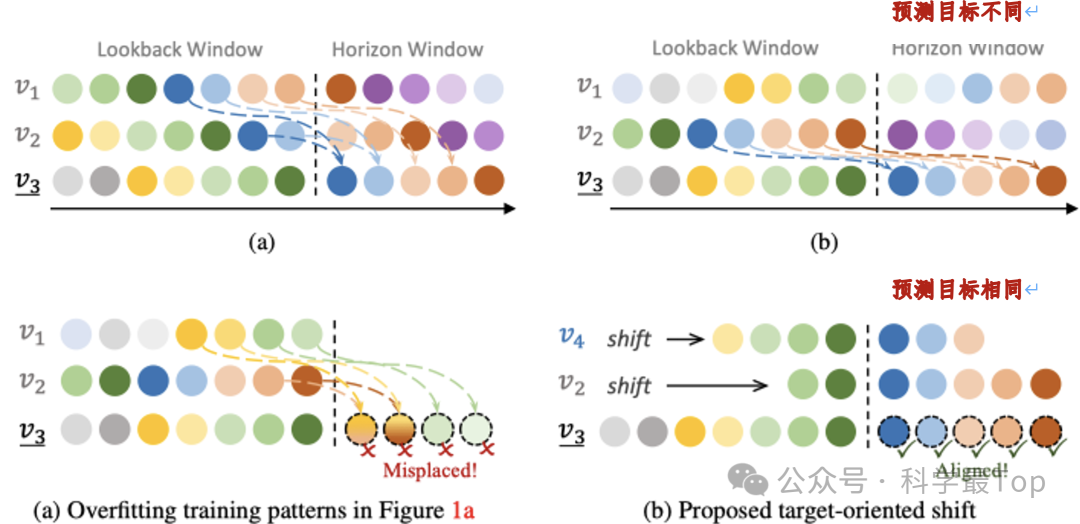
这就启发我们:(1)检测多变量相关性,先检测哪些变量之间有局部的时序变化模式相关性;(2)消除变量间时间差,通过平移也让具有相同变化模式的变量,具有一样的预测目标,然后把这种相关性作为先验知识指导预测。
这也就是这篇文章提出的LIFT模型做的事。文章中起了个高大上的名字local stationary lead- lag relationship,就是局部平稳的前后关系,这种关系就是作者说的leadding indicator。
其实这种思想有点像量化交易里面的配对交易,就是说同一行业的股票价格走势整体应该是类似的。如果我们找到具有协整性的一对股票,当价格偏离的时候我们就可以套利。这里也引出一个问题,文中是使用相关性来寻找leading indicator,这是否是合理的?因为相关并不意味着协整。
本文模型
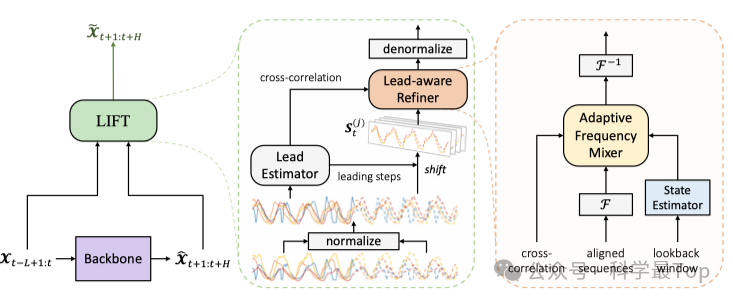
理解了思路看模型就相对容易了,图中展示了LIFT的概述,它包含以下6个主要步骤:1. 初步预测。给定一个回顾窗口,我们首先从一个主流模型获得粗略预测,该模型可以由任何现有的时间序列预测模型实现。2. 实例归一化。应用实例归一化以便统一变量的值范围。
3. 前导估计(Lead estimation)。这一步的主要目的是:计算变量对之间的互相关系数值。对于每个变量 j,我们选择K个最相关的变量,以及相应的需要移动的步长,也就是我们前面说的“时间差”。
4. 目标导向的偏移(Target-oriented shifts)。获得具有相关性的变量,以及需要移动的步长后,对于每个领先指标,根据其与目标变量的领先步数进行时间上的移位,确保领先指标在预测窗口内与目标变量对齐。
5. Lead-aware Refiner。其作用是对初步预测进行精细化处理,允许模型动态地利用领先指标中的信息,并在频域中进行自适应的信号混合,从而提高预测的准确性。这种方法特别适用于处理具有局部平稳超前-滞后关系的多元时间序列数据。
最后一步是反归一化,模型中Lead estimation和Lead-aware refinement是核心模块,涉及傅立叶变换及其逆变换,以映射到频域,建议读原文。
实验结果和结论
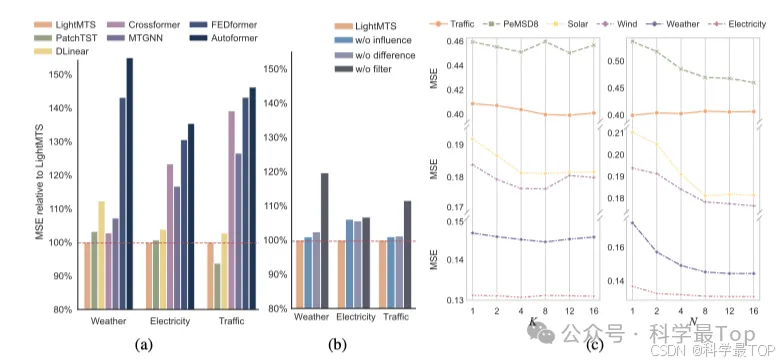
LIFT可以作为一个即插即用模块,能够与任意时间序列预测方法无缝协作。在六个真实世界数据集上的广泛实验表明,LIFT平均提高了现有最先进方法5.9%的预测性能。进一步引入了LightMTS作为MTS预测的轻量级但强大的基线,它保持与线性模型相似的参数效率,并与最先进的方法相比表现出相当的性能。作者预期,leading-lag关系可以为MTS中的通道依赖性提供一种新的跨时间视角,这是通道依赖Transformer或其他复杂神经网络未来发展的一个有希望的方向。
大家可以关注我【科学最top】,第一时间follow时序高水平论文解读!!!


















 7051
7051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









