





系列文章目录
重振多元时间序列预测:具有序列间依赖性和序列内变化建模的可学习分解 ICML2024
文章目录
摘要
预测多变量时间序列至关重要,需要对复杂模式进行精确建模,包括序列间依赖性和序列内变化。 每个时间序列中独特的趋势特征都带来了挑战,依赖于基本移动平均核的现有方法可能难以应对现实世界数据中的非线性结构和复杂趋势。 鉴于此,我们引入了一种可学习的分解策略来更合理地捕获动态趋势信息。 此外,我们提出了一个双重注意力模块,用于同时捕获序列间依赖性和序列内变化,以实现更好的时间序列预测,该模块是通过通道自注意力和自回归自注意力来实现的。 为了评估我们方法的有效性,我们在八个开源数据集上进行了实验,并将其与最先进的方法进行了比较。 通过比较结果,我们的 Leddam(LEarnable 分解和双重注意力模块)不仅展示了预测性能的显着进步,而且所提出的分解策略可以插入到其他方法中,从而大幅提升性能,MSE 误差从 11.87% 提高到 48.56% 降解。
一、引言
正如能源管理等领域所证明的那样,现实世界各个领域不断增长的需求迫切需要精确的多元时间序列预测方法(Dong et al., 2023; Liu et al., 2023b; Yi et al., 2023a) )、天气预报(Anonymous,2024b;c;a)、疾病控制(Yi et al.,2023b;Liu et al.,2023a;Zhou et al.,2022b;Ni et al.,2023)和交通规划( Rangapuram 等人,2018;Zhao 等人,2022)。 精确预测模型的基础在于有效识别和建模多元时间序列中嵌入的复杂模式。 两种主要模式(图 1(a))表现为系列间依赖性和系列内变化(Zhang & Yan,2023)。 前者描绘了不同变量之间错综复杂的相互作用和相关性,而后者则概括了每个特定时间序列内持久和短暂的波动。
然而,多元时间序列数据中每个构成变量的时间序列往往表现出明显的趋势变化。 原始时间序列中固有的这种差异可能会使序列间依赖性的建模复杂化(Liu et al., 2024)。 此外,现实世界中的时间序列持续容易受到其趋势演变引起的分布变化的影响——这一独特属性增加了序列内动态序列内变化模式建模的复杂性(Taylor & Letham,2018;Liu 等人) ., 2022b)。 因此,稳健的预测方法应该能够解决以下两个挑战:(1)如何在趋势成分的干扰下精确揭示原始时间序列中的模式。 (2)如何有效地建模系列间依赖性和系列内变化。
某些研究(Wu et al., 2021; Zhou et al., 2022c; Wang et al., 2023; Zeng et al., 2023)旨在通过使用移动对原始时间序列进行趋势季节分解来解决第一个挑战 平均内核 (MOV)。 然而,这种不可训练的过程与移动平均核一起导致缺乏鲁棒性。 此外,对滑动窗口内每个数据点统一分配权重可能会妨碍他们辨别特定模式的能力。 当处理复杂的时间序列数据(RAW 数据)时,这种限制变得明显,特别是那些具有非线性结构或显着噪声水平的数据,如图 1(b)(RAW VS. MOV)所示。 因此,有必要开发一种可学习的分解方法来振兴多元时间序列预测任务。
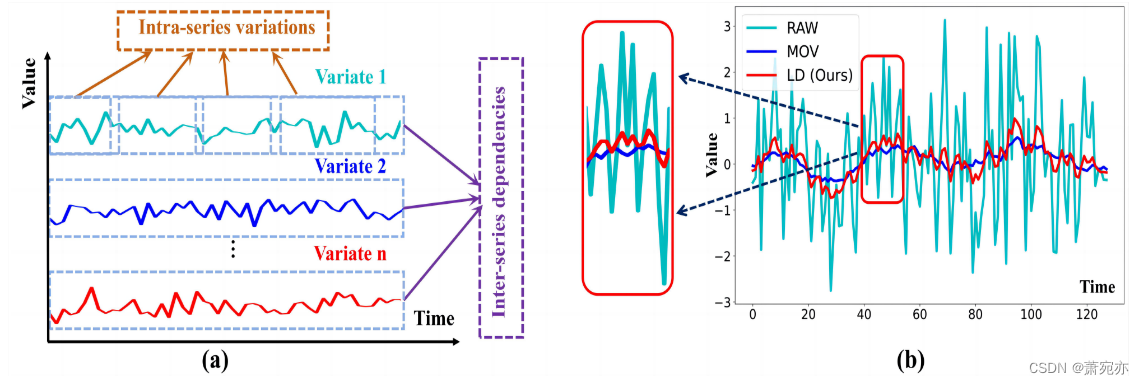
图 1.(a) 系列间依赖性和系列内变化的演示。 (b) 电力数据中不同分解方案的可视化。 RAW 表示原始时间序列。 MOV 表示移动平均内核,LD 表示我们的可学习分解模块。
对于时间序列预测中的序列间依赖性和序列内变化建模的第二个挑战,最近的工作转向了 Transformer 架构,该架构以其强大的成对依赖性描述和序列内的多级表示提取而闻名(Vaswani 等人,2017) 。 iTransformer(Liu et al., 2024)通过“通道式自我关注”有效地处理系列间依赖关系,将整个时间序列嵌入到令牌中,但缺乏对系列内变化的显式学习。 其他作品直接采用成对注意机制来处理系列内的变化(Liu et al., 2022a; Zhou et al., 2022a; Li et al., 2019; Liu et al., 2022b)。 然而,他们在时间维度上不正确地使用排列不变注意机制(Zeng et al., 2023)。 或者,一些方法转向将时间序列划分为补丁,并对这些补丁应用自注意力模型(Nie et al., 2023;Zhang & Yan, 2023)。 然而,这种方法本质上会导致信息丢失,因为补丁仅封装了原始序列的一部分。 此外,最佳补丁长度也很难确定。 因此,我们的目标是通过生成适合对系列内变化进行建模的特征来处理它,同时最大限度地保留信息以避免上述缺点。
在本文中,我们的目标是利用 Leddam(LEarnable 分解和双重注意力模块)重振多元时间序列预测。 具体来说,我们首先引入可训练的分解模块,将原始时间序列数据分解为更合理的趋势和季节性部分。 这使得内核能够优先考虑当前数据点并适应原始时间序列中的非线性结构或噪声,从而有效捕获动态趋势信息(参见图 1(b) 中的 LD)。 其次,我们设计了一个“双重注意力模块”,其中1)通道自注意力以捕获系列间依赖关系; 2) 一种增强的方法,涉及对生成的令牌进行自动回归过程和注意机制,以对系列内的变化进行建模。 我们的 Leddam 旨在为时间序列预测挑战提供更强大、更全面的解决方案。 主要贡献总结如下。
• 我们建议结合一个用高斯分布初始化的可学习卷积核来增强时间序列分解。 • 我们设计了一个“双重注意力模块”,可以同时捕捉系列间依赖性和系列内变化。 • 我们验证了我们的Leddam,不仅证明了预测性能的显着进步,而且提出的分解策略可以插入到其他方法中,性能大幅提升,MSE 误差下降从11.87% 到48.56%。
二、 Related work
时间序列数据分解。 由于移动平均核具有从序列数据中提取全局信息的能力,Autoformer(Wu et al., 2021)最初提出使用它来提取时间序列的趋势部分。 后来的工作,包括 MICN (Wang et al., 2023)、FEDformer (Zhou et al., 2022c)、DLinear (Zeng et al., 2023) 等,主要遵循他们的方法论。 然而,基本的平均内核可能不足以捕获时间序列的精确趋势,其特征是比简单的线性关系更复杂的模式。
系列内变化建模。 对于精确的时间序列预测模型来说,理解时间序列中固有的时间变化至关重要。 由于点对点注意力机制的内在局限性,例如 Informer (Zhou et al., 2022a)、Reformer (Kitaev et al., 2020) 和 Pyraformer (Liu et al., 2022a) 等模型中采用的机制 ),由此产生的注意力图很容易出现次优。 这是因为时间序列中的各个点与单词(Vaswani 等人,2017)或图像块(Dosovitskiy 等人,2021)相比,缺乏明确的语义信息。 随后的努力包括将主要时间序列划分为一系列补丁(Zhang & Yan, 2023; Nie et al., 2023),然后在这些补丁中应用自注意力机制来模拟时间变化。 然而,将时间序列分割成补丁不可避免地会导致信息丢失。
系列间依赖关系建模。 序列间依赖性构成了区分多变量时间序列与单变量时间序列的关键属性。 我们注意到,大多数基于 Transformer 的方法选择将来自同一时间步骤的不同变量或来自不同通道的值视为标记(Zhou 等人,2022a;Kitaev 等人,2020;Liu 等人) ., 2022a;b) 对系列间依赖性进行建模。 这种策略可能会导致注意力图缺乏有意义的信息,从而阻碍对我们寻求的信息进行有效和准确的建模(Liu et al., 2024)。 某些努力试图采用通道无关的设计,旨在减轻此操作引起的预测准确性的降低,例如 PatchTST(Nie 等人,2023)和 DLinear(Zeng 等人,2023)。 独立考虑时间序列变量并采用共享骨干网的通道独立性(CI)作为一种无架构方法,在预测中越来越受欢迎,并具有性能提升。 最近的研究(Han et al., 2023; Li et al., 2023)发现,虽然通道依赖(CD)在理想情况下受益于更高的容量,但由于样本稀缺,CI 可以极大地提高性能,因为大多数当前的预测基准 不够大。 然而,忽视变量之间的相互依赖性可能会导致次优结果(Liu et al., 2024)。 Crossformer(Zhang & Yan,2023)致力于将时间序列划分为补丁,然后学习这些补丁的系列间依赖性,如前所述,这个过程可能会导致信息丢失。 iTranformer(Liu et al., 2024)通过将变量的整个时间序列嵌入到令牌中,实现了对多元时间序列的变量之间的关系进行更精确的建模,从而避免信息丢失。
三、Methodology
在本节中,我们将阐明 Leddam 的整体架构,如图 2 所示。我们将首先定义问题,然后描述所提出的可学习卷积分解策略和双重注意力模块。
3.1. Problem Definition
给定一个多元时间序列输入
X
∈
R
N
×
T
X \in \mathbb{R}^{N\times T}
X∈RN×T,时间序列预测任务旨在预测其未来的 F 个时间步
Y
^
∈
R
N
×
F
{\hat{Y}}\in{{\mathbb{R}}}^{N\times F}
Y^∈RN×F,其中 N 是变量或通道的数量,T 表示回溯窗口长度 。 我们的目标是使
Y
^
\hat{Y}
Y^ 非常接近
Y
∈
R
N
×
F
Y\in\mathbb{R}^{N\times F}
Y∈RN×F,它代表了基本事实。
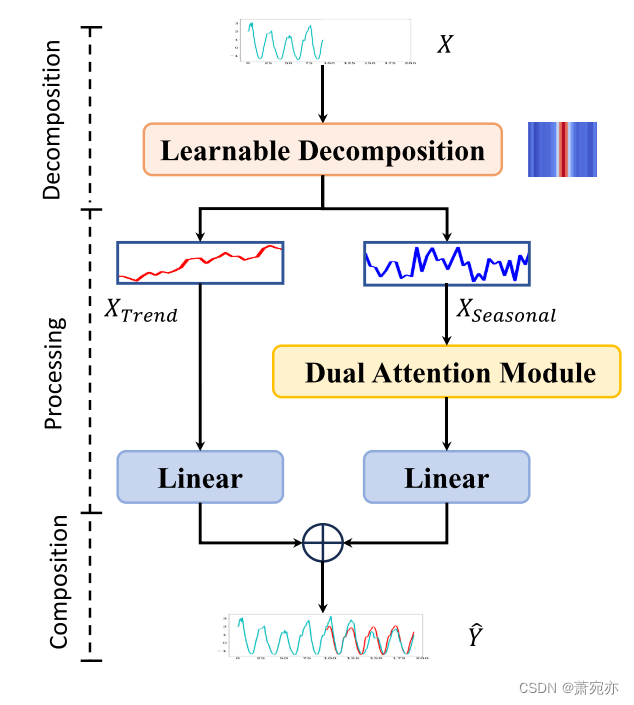
图 2. 拟议 Leddam 的总体结构。 我们首先嵌入时间序列并结合位置编码。 然后,时间序列被分解为趋势部分和季节性部分,每个部分都通过不同的方法来处理。 最后,将这两个组件的处理结果汇总以获得最终的预测结果。
3.2. Learnable Convolutional Decomposition
我们采用卓越的可学习一维卷积分解内核而不是移动平均内核来全面封装时间序列中细微的时间变化。
投影和位置嵌入。 遵循 iTransformer (Liu et al., 2024),我们首先将时间序列数据 X ∈ R N × T X\in\mathbb{R}^{N\times T} X∈RN×T 从原始空间映射到新空间,随后将位置编码 P o s ∈ R N × D Pos\in\mathbb{R}^{N\times D} Pos∈RN×D 合并为 X e m b e d ∈ R N × D X_{embed}\in\mathbb{R}^{N\times D} Xembed∈RN×D,如下 X e m b e d = ( X W + b ) + P o s X_{embed}=(XW+b)+Pos Xembed=(XW+b)+Pos,权重 W ∈ R T × D , b ∈ R 1 × D W \in \mathbb{R}^{T\times D},b \in \mathbb{R}^{1\times D} W∈RT×D,b∈R1×D,其中 D 是层的维度。
可学习的一维卷积分解内核。 为了实现可学习的卷积分解,我们需要首先定义卷积分解核。 具体来说,我们通过实验预先定义步长 S = 1 和内核大小 K = 25。 关于其权重,利用高斯分布进行初始化。 我们假设它的权重是 ω ∈ R 1 × 1 × K \omega\in\mathbb{R}^{1\times1\times K} ω∈R1×1×K,超参数 σ ∈ R。
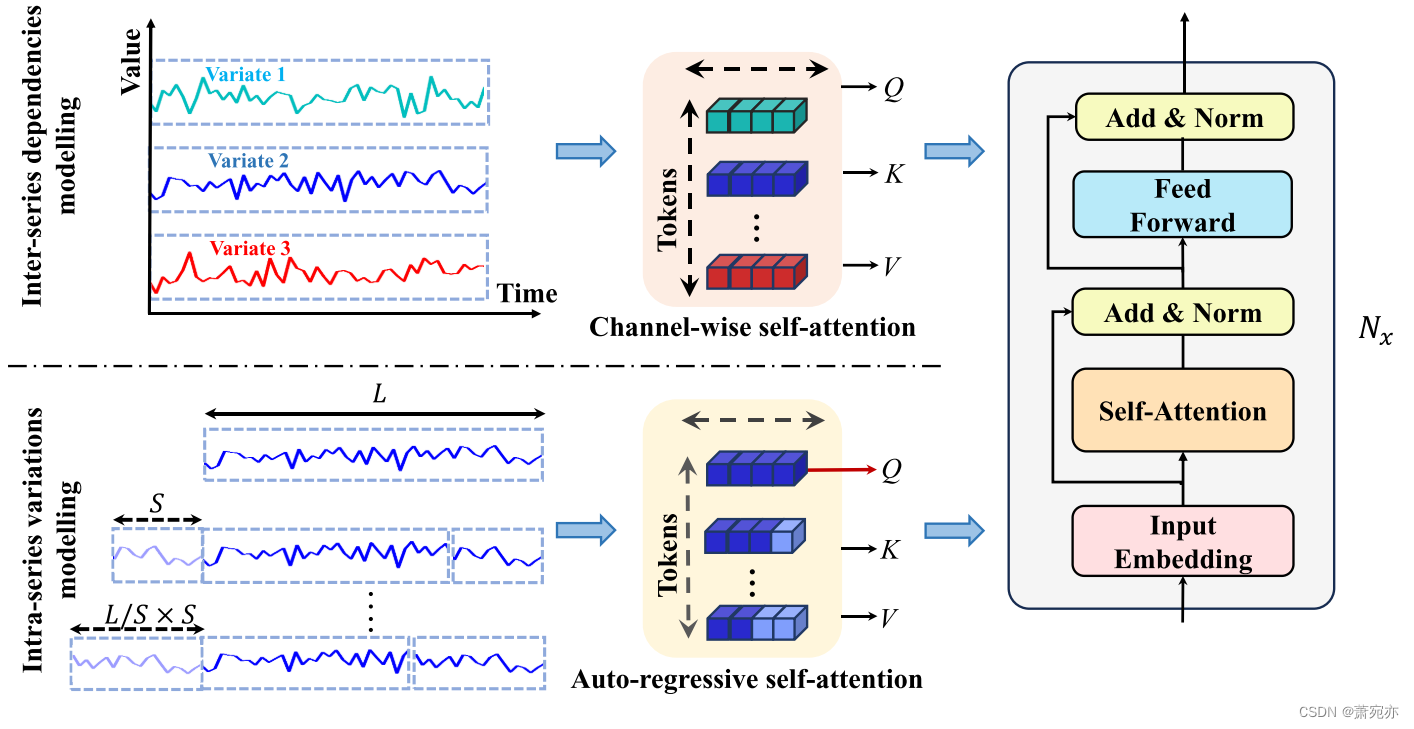
图 3.“双重注意力模块”分别处理系列间依赖性和系列内变化的一般流程。 “通道自注意力”嵌入通道的整个系列以生成“全系列嵌入”,并采用变压器编码器来建模系列间依赖关系。 “自回归自注意力”生成“自回归嵌入”,并且仍然利用变压器编码器来模拟系列内的变化
这里我们设置 σ = 1.0。 那么,我们有
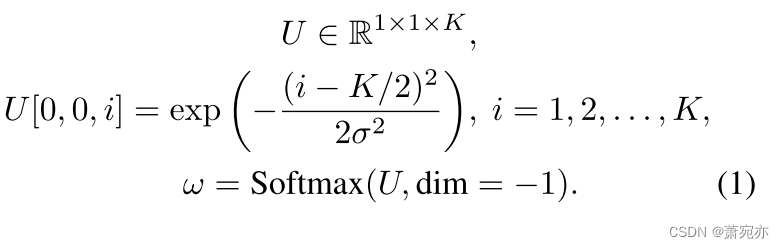
因此,这种初始化导致卷积核的中心位置具有最大权重,而核的边缘位置具有相对较小的权重。 这通常有利于卷积层在识别特定特征时对中心位置更加敏感。 给定一个多元时间序列输入
X
e
m
b
e
d
∈
R
N
×
D
X_{embed}\in\mathbb{R}^{N\times D}
Xembed∈RN×D,其中 N 表示通道的维数,对应于时间序列中变量的数量,D 是位置和时间编码后嵌入的维数,以保持以下等价 卷积之前和之后的序列长度,使用终端值进行填充。 所以我们得到
X
p
a
d
d
e
d
∈
R
N
×
(
D
+
K
−
1
)
X_{padded}\in\mathbb{R}^{N\times(D+K-1)}
Xpadded∈RN×(D+K−1),我们将它分成 N 个单独的时间序列
x
i
∈
R
1
×
(
D
+
K
−
1
)
x_i \in \mathbb{R}^{1\times(D+K-1)}
xi∈R1×(D+K−1), i = 1, 2,… ,N. 随后,对于每个
x
i
x_i
xi,我们应用具有共享权重的可学习一维卷积核来提取其趋势分量,表示为
x
i
^
∈
R
1
×
D
\hat{x_{i}}\in\mathbb{R}^{1\times D}
xi^∈R1×D。 随后,所有
x
i
^
∈
R
1
×
D
\hat{x_{i}}\in\mathbb{R}^{1\times D}
xi^∈R1×D的卷积输出被连接起来形成结果矩阵
X
T
r
e
n
d
∈
R
N
×
D
X_{Trend}\in\mathbb{R}^{N\times D}
XTrend∈RN×D。 我们通过
X
S
e
a
s
o
n
a
l
=
X
e
m
b
e
d
−
X
T
r
e
n
d
X_{Seasonal} = X_{embed}-X_{Trend}
XSeasonal=Xembed−XTrend 得到季节性部分
X
S
e
a
s
o
n
a
l
∈
R
N
×
D
X_{Seasonal}\in\mathbb{R}^{N\times D}
XSeasonal∈RN×D。
整个过程可以概括为
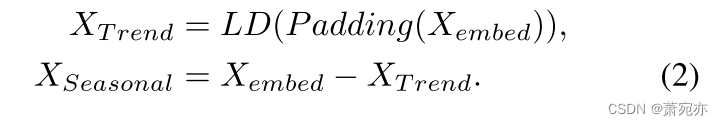
趋势部分。 考虑到趋势部分更平滑、更具预测性,我们采用简单的 MLP 进行投影来导出趋势部分的输出,类似于(Zeng 等人,2023;Wang 等人,2023),其内容如下:
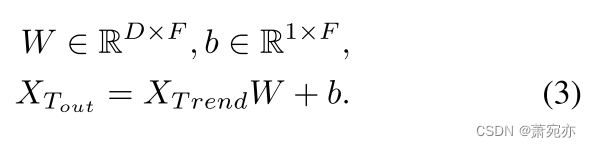
季节性部分。 考虑到季节性分量对系列间依赖性和系列内变化进行建模的适用性,我们将
X
S
e
a
s
o
n
a
l
∈
R
N
×
D
X_{Seasonal}\in\mathbb{R}^{N\times D}
XSeasonal∈RN×D 转换为两种不同的嵌入:“全系列嵌入”和“自回归嵌入”。 这有利于两种模式的建模和学习过程。
3.3. Dual Attention Module
我们提出了一个“双重注意力模块”来同时对系列间依赖性和系列内变化进行建模。 具体来说,我们设计了“Channel-wise self-attention”来建模前者,并设计“Auto-regressive self-attention”来建模后者。
系列间依赖关系建模。 为了对系列间依赖关系进行建模,请遵循 iTranformer (Liu et al., 2024),我们考虑 X S e a s o n a l [ i , : ] ∈ R 1 × D , i = 1 , 2 , … , N X_{Seasonal}[i,:]\in\mathbb{R}^{1\times D},\quad i=1,2,\ldots,N XSeasonal[i,:]∈R1×D,i=1,2,…,N 作为令牌,如图 3 所示。随后,所有令牌都被发送到普通 Transformer 编码器中以用于学习目的,以获得 X I n t e r ∈ R N × D X_{Inter}\in\mathbb{R}^{N\times D} XInter∈RN×D:
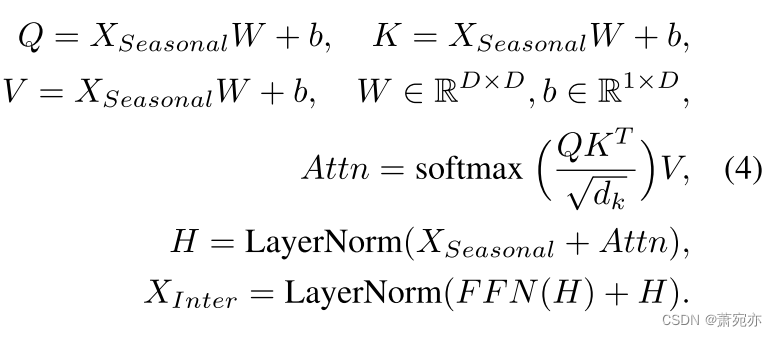 我们将此过程表示为“通道式自注意力”,并将生成的嵌入表示为“全系列嵌入”,与补丁或片段相比,它在保留序列的大部分信息的同时,更适合对系列间依赖关系进行建模 ,因为变量的所有语义信息都被保存。
我们将此过程表示为“通道式自注意力”,并将生成的嵌入表示为“全系列嵌入”,与补丁或片段相比,它在保留序列的大部分信息的同时,更适合对系列间依赖关系进行建模 ,因为变量的所有语义信息都被保存。
系列内变化建模。 为了捕获系列内的变化,我们提出了一种先进的方法。 在此,初始序列经过自回归处理,生成标记,在精心保留全部原始信息的同时,部分模拟原始时间序列中存在的动态变化。
对于序列内变化,如图 3 所示,我们首先将 X S e a s o n a l X_{Seasonal} XSeasonal拆分为 N 个单独的时间序列 x s i ∈ R 1 × D x_s^i\in\mathbb{R}^{1\times D} xsi∈R1×D,i = 1, 2,…。 。 。 ,N. 对于每个 x s i x_s^i xsi,给定长度 L,我们通过从开头切割给定长度的序列并将其连接到时间序列的末尾来生成 S i ∈ R D L × D S^i \in \mathbb{R}^{\frac DL\times D} Si∈RLD×D 标记:
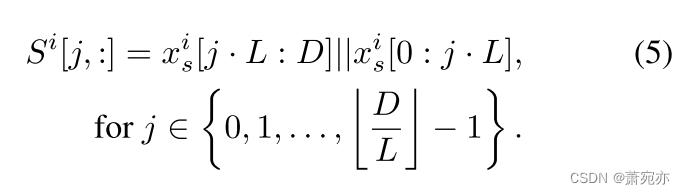
在此过程中生成的代币被命名为“自回归嵌入”。 这种自回归令牌生成方法可以动态模拟时间序列内的时间变化。 与利用采样策略派生子序列或将主时间序列划分为补丁或片段的方法相比,这些方法不可避免地导致信息丢失,这种方法最大限度地保留了原始时间序列的信息。 然后,我们仍然使用另一个普通的 Transformer 编码器,其权重在所有通道之间共享,以对序列内变化进行建模,但考虑到我们对原始序列的时间信息的主要兴趣,我们将原始序列
x
s
i
x_{s}^{i}
xsi 单独指定为 Q,同时利用 整个序列
S
i
S^{i}
Si作为 K 和 V:
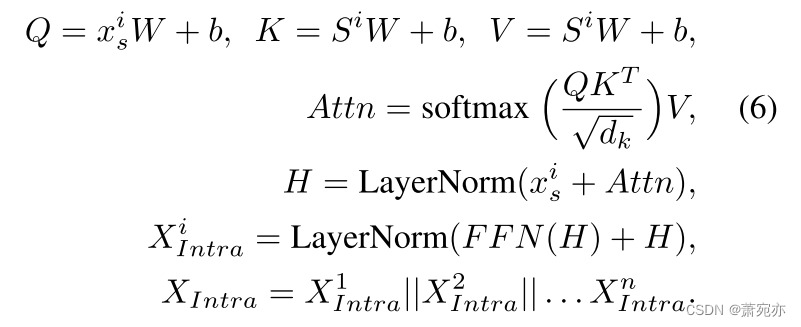
所有通道的输出
X
I
n
t
r
a
i
X_{Intra}^{i}
XIntrai 连接为
X
I
n
t
r
a
∈
R
N
×
D
X_{Intra}\in\mathbb{R}^{N\times D}
XIntra∈RN×D。 季节部分的最终输出结果由下式得出:
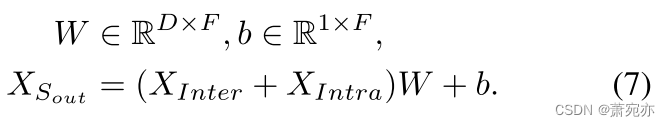
预测生成。 我们通过
Y
^
=
X
S
o
u
t
+
X
T
o
u
t
\hat{Y}=X_{S_{out}}+X_{T_{out}}
Y^=XSout+XTout 获得最终的预测结果。
四、 Experiments
4.1. Experimental Settings
在本节中,我们首先介绍公平比较下的整个实验设置。 其次,我们通过将 Leddam 与 8 种当前最先进的(SOTA)方法进行比较来说明实验结果。 此外,我们进行了消融研究,以全面研究可学习的卷积分解模块的有效性以及引入的“双重注意模块”的有效性。
表 1. 我们实验中使用的八个数据集的统计数据。

数据集。 我们对选定的八个广泛使用的现实世界多元时间序列预测数据集进行了广泛的实验,包括电力变压器温度(ETTh1、ETTh2、ETTm1 和 ETTm2)、Autoformer 使用的电力、交通、天气(Wu 等人,2021) ,以及 LSTNet 中提出的太阳能数据集(Lai 等人,2018)。 为了公平比较,我们遵循相同的标准协议(Liu et al., 2024),并按照 ETT 数据集 6:2:2 和 7:1 的比例将所有预测数据集分为训练集、验证集和测试集: 2 对于其他数据集。 这些数据集的特征如表1所示(更多信息请参见附录A.1)。
评估协议。 继TimesNet(Wu et al., 2023)之后,我们使用均方误差(MSE)和平均绝对误差(MAE)作为评估的核心指标。 为了公平地比较预测性能,我们遵循相同的评估协议,其中所有模型的历史范围长度设置为 T = 96,预测长度 F ∈ {96, 192, 336, 720}。 Leddam的详细超参数可以在附录A.2中找到。
基线设置。 我们精心选择了最近八个公认的预测模型作为我们的基线,包括 1) 基于 Transformer 的方法:iTransformer (Liu et al., 2024)、Crossformer (Zhang & Yan, 2023)、PatchTST (Nie et al., 2023) ); 2)基于线性的方法:DLinear(Zeng et al., 2023)、TiDE(Das et al., 2023); 3)基于TCN的方法:SCINet(LIU等人,2022)、MICN(Wang等人,2023)、TimesNet(Wu等人,2023)。
4.2. Experiments Results
定量比较。 综合预测结果如表2所示,其中最好的为红色粗体,次之为蓝色下划线。 我们将完整的预测结果保留在附录 E 中以节省空间。 MSE/MAE 越低,表明预测结果越好。 显而易见,Leddam 在除 Traffic 之外的所有数据集上都表现出了卓越的预测性能,其中 iTransformer 获得了最佳的预测性能。 与 PatchTST 和 iTransformer 类似,Leddam 采用普通 Transformer 编码器作为其主干,没有任何结构修改。 然而值得注意的是,这三个模型在所有数据集上始终表现出卓越的性能。 这至少部分表明,与复杂设计的模型架构相比,原始时间序列特征的卓越表示,例如 iTransformer 和 Leddam 中使用的“全序列嵌入”以及 PatchTST 的补丁,确实可能构成实现更高效时间的关键因素 -系列预测。 值得注意的是,在这三个模型中,PacthTST采用了通道无关的设计,专门解决系列内的变化,而不考虑系列间的依赖性。 iTransformer 利用通道自注意力来建模系列间依赖关系,但无法充分捕获系列内的变化。 与两者相比,拟议的 Leddam 结合了“全系列嵌入”和“自回归嵌入”来分别建模系列间依赖性和系列内变化。 因此,Leddam 在各种数据集上都表现出了卓越的性能。 然而,这三个模型在大多数数据集上仍然保持着相对于其他模型的领先地位。 这与我们的假设相一致,即对多元时间序列中的序列间依赖性和序列内变化进行适当建模是实现更精确预测的关键。
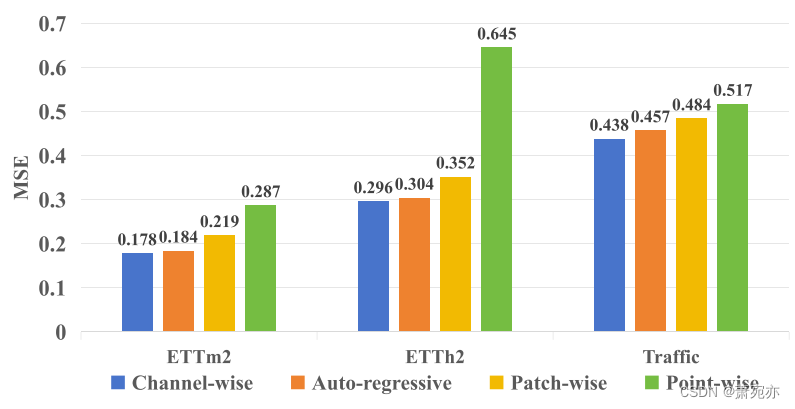 图 4. ETTh2、ETTm2 和 Traffic 中“通道式自注意力”、“自回归自注意力”、“补丁式自注意力”和“点式自注意力”的预测性能比较 (MSE) 数据集。 预测范围统一设置为F = 96,而输入长度T = 96。
图 4. ETTh2、ETTm2 和 Traffic 中“通道式自注意力”、“自回归自注意力”、“补丁式自注意力”和“点式自注意力”的预测性能比较 (MSE) 数据集。 预测范围统一设置为F = 96,而输入长度T = 96。
4.3. Model Analysis
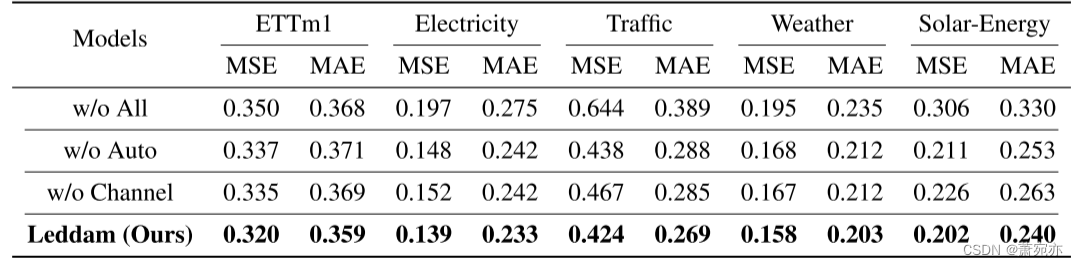
双注意力模块的消融研究我们在 ETTh1、交通、电力、太阳能和天气等五个数据集上进行了消融实验,以验证我们的“自回归自注意力”和“逐通道自注意力”带来的性能增强 ’ 成分。 “Channel”意味着我们只使用“Channel-wise self-attention”。 “自动”意味着我们只使用“自回归自注意力”。 “w/o All”意味着我们只需用线性层替换“自回归自注意力”和“通道自注意力”组件。
我们在表 3 中观察到“自回归自注意力”和“通道自注意力”组件带来的显着性能改进。 与使用线性层相比,“自回归自注意力”使五个数据集的 MSE 平均降低了 19.02%,而“通道自注意力”实现了 21.09% 的改进。 此外,它们的协同集成进一步增强了模型性能,平均 MSE 降低了 25.03%,达到了最佳水平。 这证明了这两个设计元素的有效性,并再次验证了我们的假设,即,对多元时间序列中的系列间依赖性和系列内变化进行适当建模可以产生更好的预测性能。
可训练的一维卷积核相对于移动平均核的优越性。 为了更好地强调我们的可训练一维卷积核(其权重使用高斯分布初始化)与传统移动平均核相比的优势,我们进行了广泛的实验。 鉴于 DLinear 可以说代表了利用移动平均内核进行趋势信息提取的最突出的实例,并且仅使用两个简单的线性层就实现了与其他最先进的方法相当的性能,我们选择它作为我们的基线。 为了进行比较,我们将其移动平均内核替换为可训练的一维卷积内核,如果内核设置为可训练,则将修改后的模型表示为 LD TL,如果内核设置为不可训练,则将修改后的模型表示为 LD UTL。
表 2. 预测长度 F ∈ {96, 192, 336, 720} 和固定回溯长度 T = 96 的多变量预测结果。结果是所有预测长度的平均值。 完整结果列于附录中。
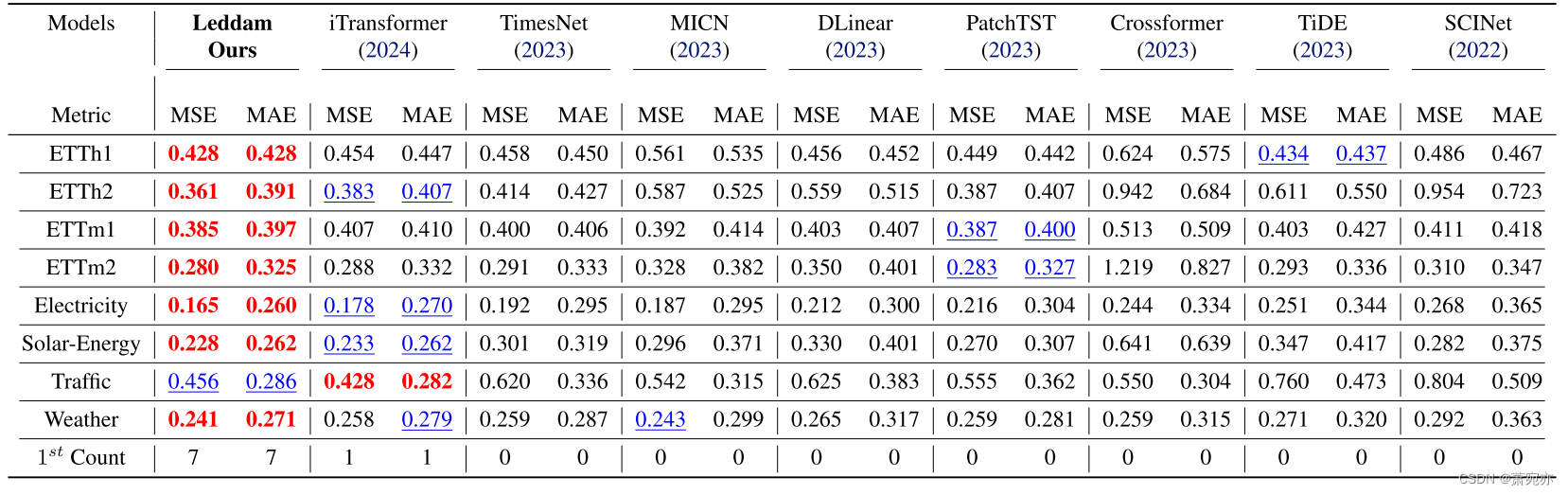
表 3. 五个数据集的模型结构消融,预测长度 F = 96,输入长度 T = 96。
与简单的移动平均核相比,可训练的一维卷积核(如表 4 所示)无论其可训练性如何,在所有四个数据集上始终表现出卓越的预测性能。 与使用移动平均核相比,不可训练的一维卷积核版本在五个数据集上平均降低了 7.28% 的 MSE,而可训练版本则降低了 11.98%。 获得的结果最终证明了我们的可训练一维卷积核比简单的移动平均核具有优越的功效,并且核的可训练性在其适应性中起着重要作用。 我们将进一步分析留给附录 B.1-B.3。
系列间依赖建模中不同注意机制的分析。 我们设计了一项综合实验来研究三种流行的序列间依赖关系建模方法:“通道式自注意力”、“点式自注意力”和“补丁式自注意力”。 第一个将变量的整个序列视为令牌(Liu et al., 2024),第二个将同一时间戳的不同变量视为令牌(Zhou et al., 2022a;c),第三个将变量的补丁视为令牌 原始序列作为标记(Zhang & Yan, 2023; Nie et al., 2023)。 具体来说,我们从原始 Leddam 结构中消除了“自回归自注意力”分支,以专注于系列间依赖关系建模。 我们依次采用“Channel-wise self-attention”、“Point-wise self-attention”和“patch-wise self-attention”。 在图 4 中,很明显,与“Point-wise self-attention”和“Patch-wise self-attention”相比,“Channel-wise self-attention”表现出优越的预测性能,意味着更好的系列间 依赖关系建模能力。
系列内变异建模中不同注意机制的分析。 同样,我们替换了原始 Leddam 结构中的“Channel-wise self-attention”分支,并在系列内使用“Point-wise self-attention”、“Patchwise self-attention”和“Auto-regressive self-attention” 变化建模。 图 4 中的实验结果清楚地证明了“自回归自注意力”架构的优越性。
4.4. Learnable Decomposition Generalization Analysis
在本小节中,我们通过将 Leddam 的可学习分解模块插入其他不同类型的模型来研究其泛化性。
模型选择和实验设置。 为了实现这一目标,我们对一系列具有代表性的时间序列预测模型结构进行了实验,包括(1)基于 Transformer 的方法:Informer(Zhou et al., 2022a)、Transformer(Vaswani et al., 2017); (2)基于线性的方法:LightTS(Zhang et al., 2022); (3) 基于 TCN 的方法:SCINet (LIU et al., 2022); (4) 基于 RNN 的方法:LSTM (Hochreiter & Schmidhuber, 1997)。 我们将输入长度T标准化为96,同样,预测长度F统一设置为96。随后,在ETTh2、ETTm2、Weather、Electricity和Traffic 5个数据集上进行了对比实验。 具体来说,我们依次用每个模型替换了 Leddam 中的“自回归自注意力”和“通道自注意力”组件。 进行比较分析以评估 Leddam 加入前后的预测性能,将原始模型与增强模型进行比较。 更多结果可以在附录 C 中找到。
表 4. 四个数据集的移动平均核和可训练一维卷积核的预测性能比较。 预测范围统一设置为F = 720,而输入长度T = 96。
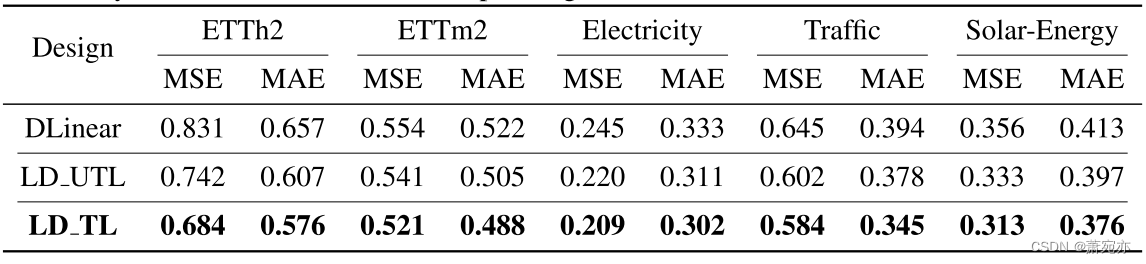
表 5. LD 相对于预测长度 F = 96 和固定回溯长度 T = 96 的不同模型的改进。LD 表示可学习分解。
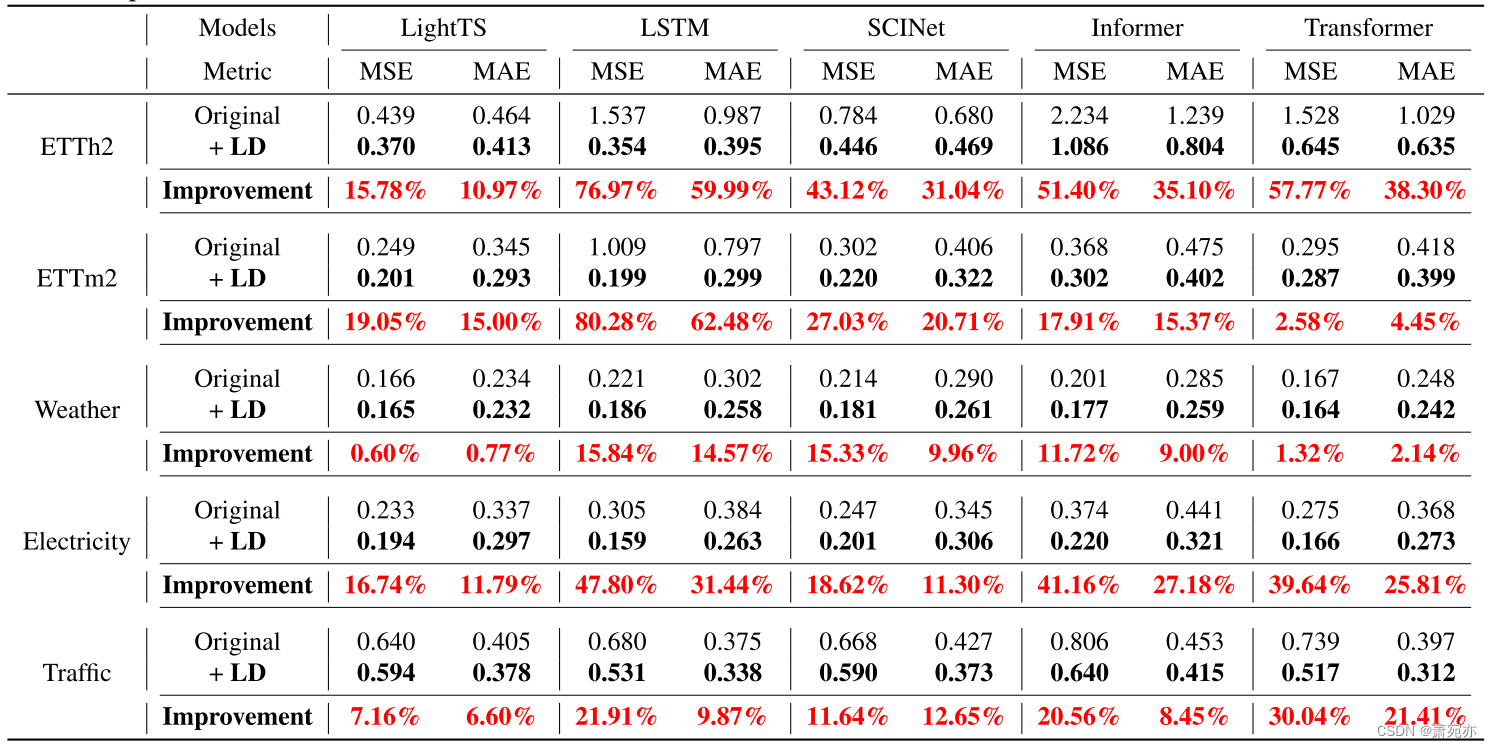
定量结果。 在表 5 中,很明显,即使仅引入单个线性层,Leddam 结构的结合也会导致各种模型的预测性能显着增强。 具体来说,LightTS 在五个数据集上显示平均 MSE 降低了 11.87%,其他模型包括 LSTM:48.56%、SCINet:23.15%、Informer:31.72% 和 Transformer:26.27%。 特别值得注意的是经典 LSTM 模型中观察到的性能增强,其中 ETTh2 和 ETTm2 的 MSE 分别显着下降了 76.97% 和 80.28%,这一结果令人非常惊讶。 这明确地证实了 Leddam 结构的普遍性。
五、 Conclusion
考虑到现实世界时间序列数据固有的非线性和复杂的趋势特征,本文制定了一种可学习的卷积核,作为对时间序列分解的简单移动平均核的改进。 高斯初始化和适应性强的属性使其能够更好地与实时序列数据的细微差别保持一致,从而产生更适合上下文的分解。 此外,我们提出了双重注意力模块,结合了通道自注意力和自回归自注意力。 这种创新设计有助于同时精确捕获系列间依赖性和系列内变化。 通过实验,我们的方法实现了最先进的性能,并展示了卓越的框架通用性,并得到了令人信服的分析的支持。 未来,我们的目标是在级数分解的背景下优化可学习卷积核的应用。

















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









