







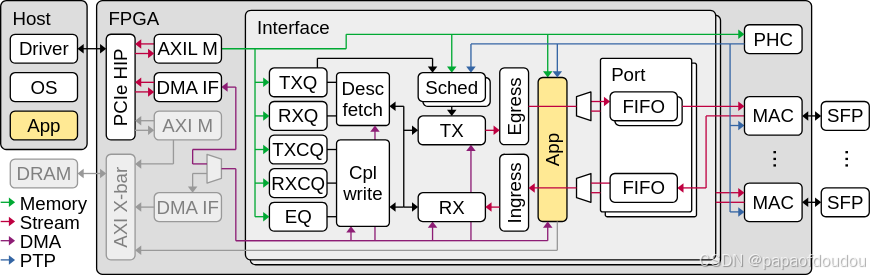
corundum是一款基于FPGA的100G以太网卡解决方案,corundum方案中的所有源码,包括verilog,linux网络驱动程序都是开源的。
下载项目代码:
git clone https://github.com/corundum/corundum 代码中包括了网卡的verilog实现以及LINUX内核驱动实现:


编译驱动
在Ubuntu 20.04.6 LTS,内核版本5.15.0-122-generic上编译,进入corundum/modules/mqnic目录,执行make 编译:
安装:


如果之前已经把写入了正确Corundum FPAG bitfile文件的FPGA卡(比如浪潮F37X FPGA加速卡)插在了主机的PCIE插槽上,此时就可以用了。
源码分析:
驱动注册
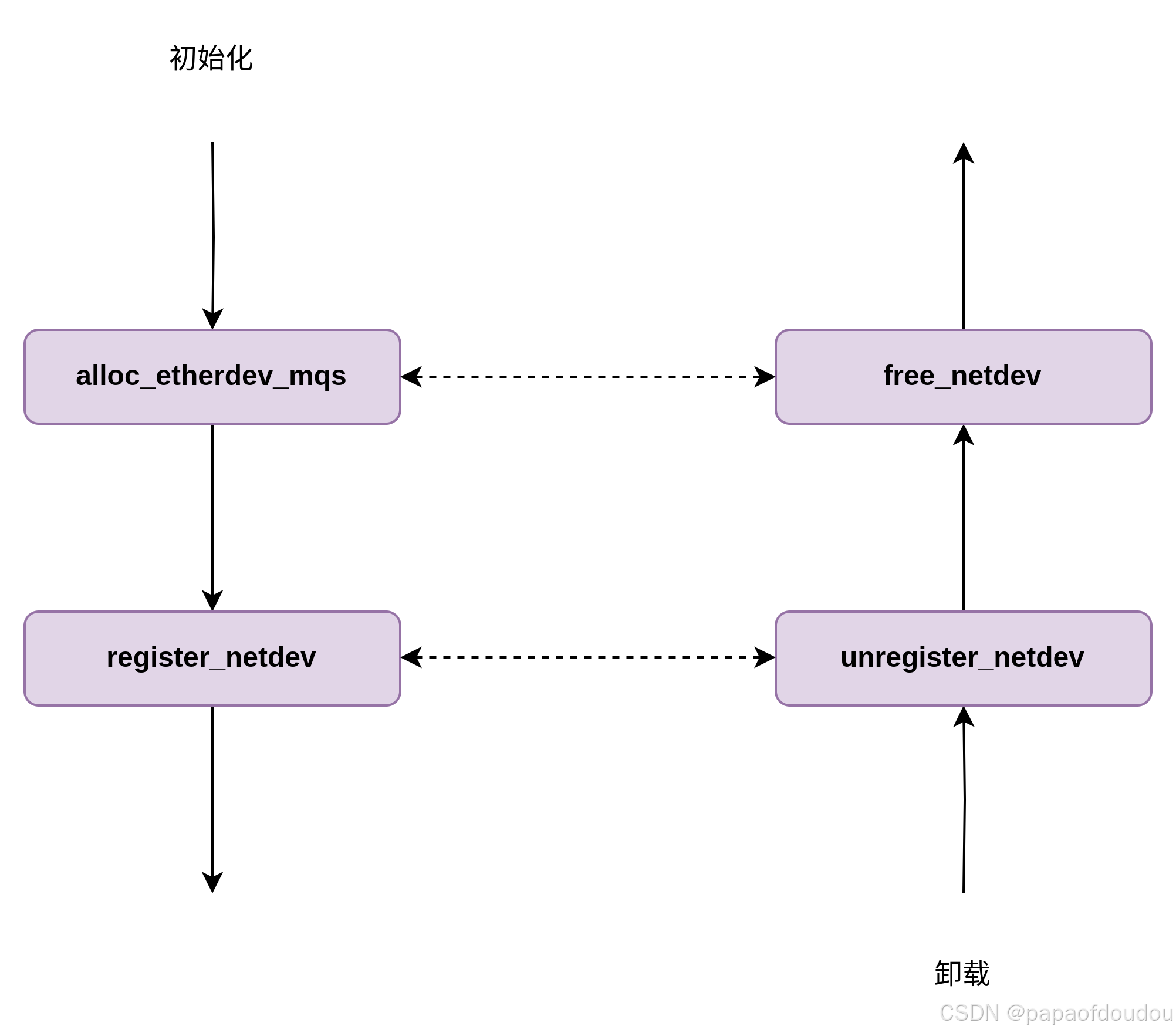
驱动初始化
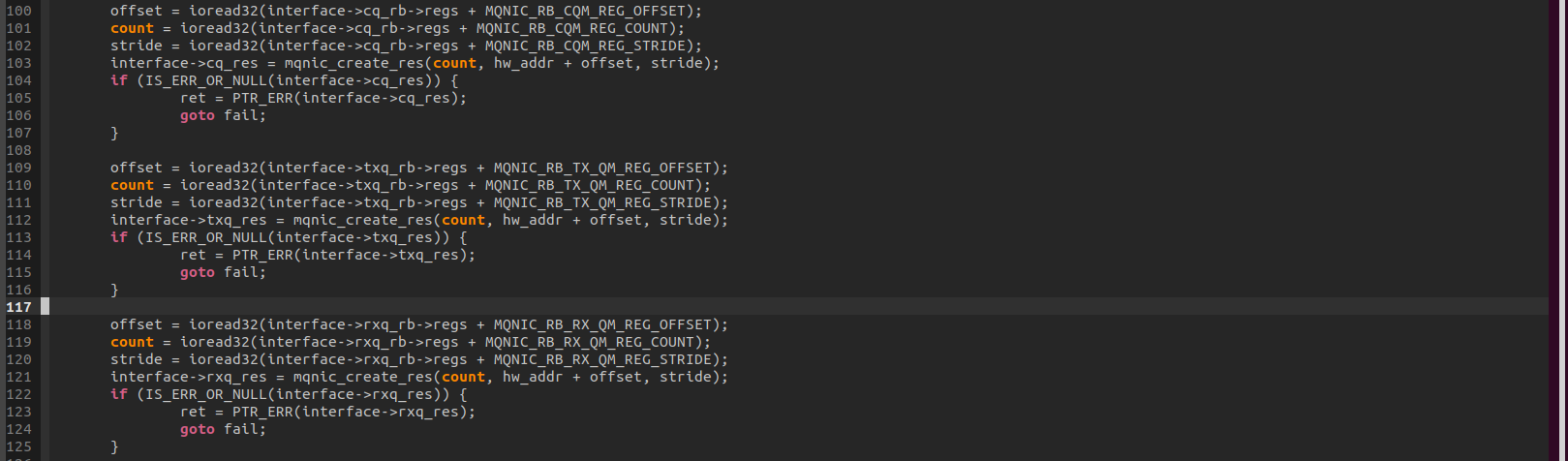
从硬件获取TX QUEUE和RX QUEUE数目,在函数mqnic_create_interface:





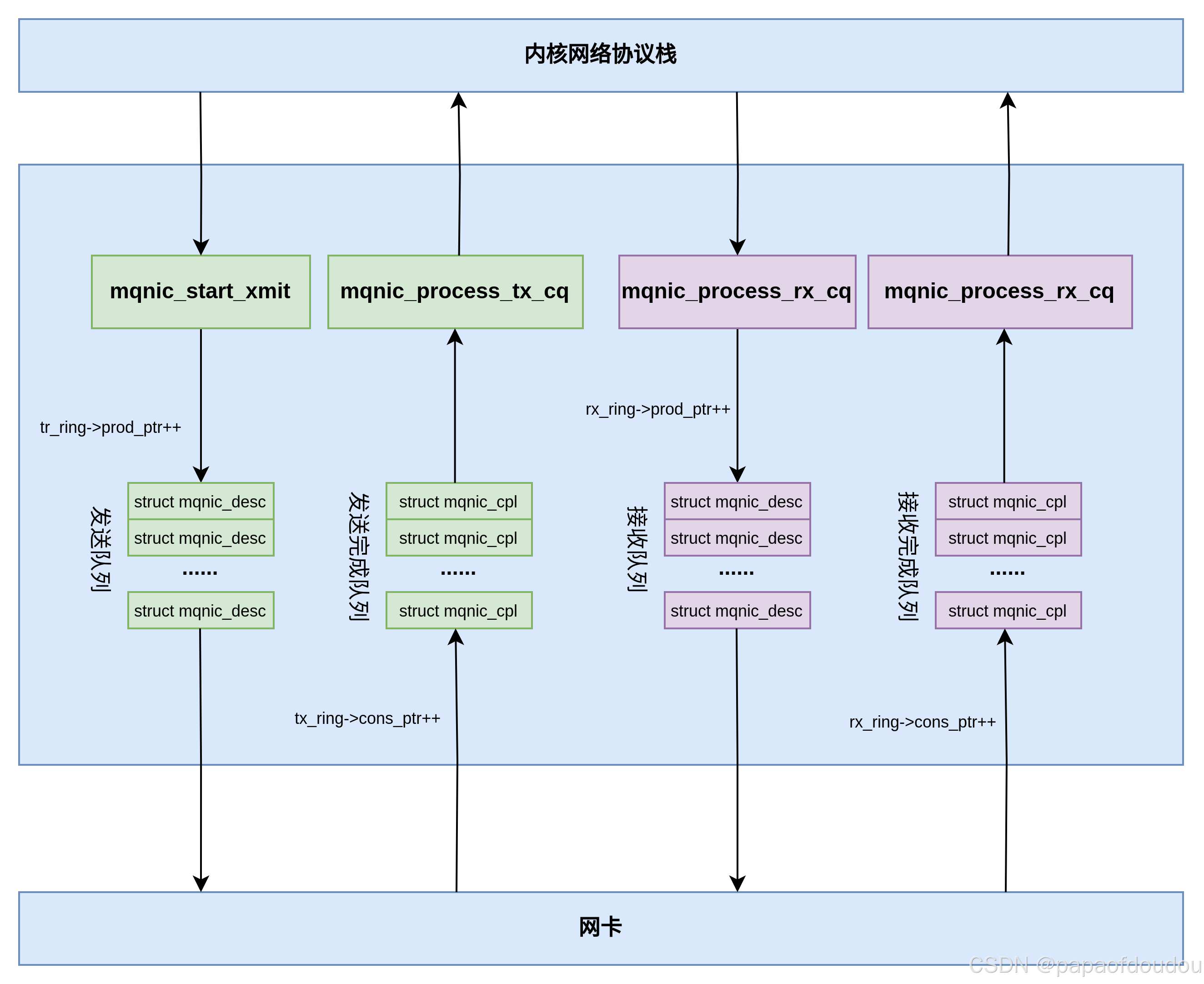
和RDMA QP通信模型的关系
对上图的模型进行一次抽象和封装,就得到了RDMA IB中的QP通信模型,如下图所示,创建QP时,QP内部会分配SQ/RQ队列,相当于上图中的发送队列和接收队列,而ibv_qp_init_attr参数中填充的字段.send_cq/.recv_cq,则相当于途中的发送完成队列和接收完成队列。
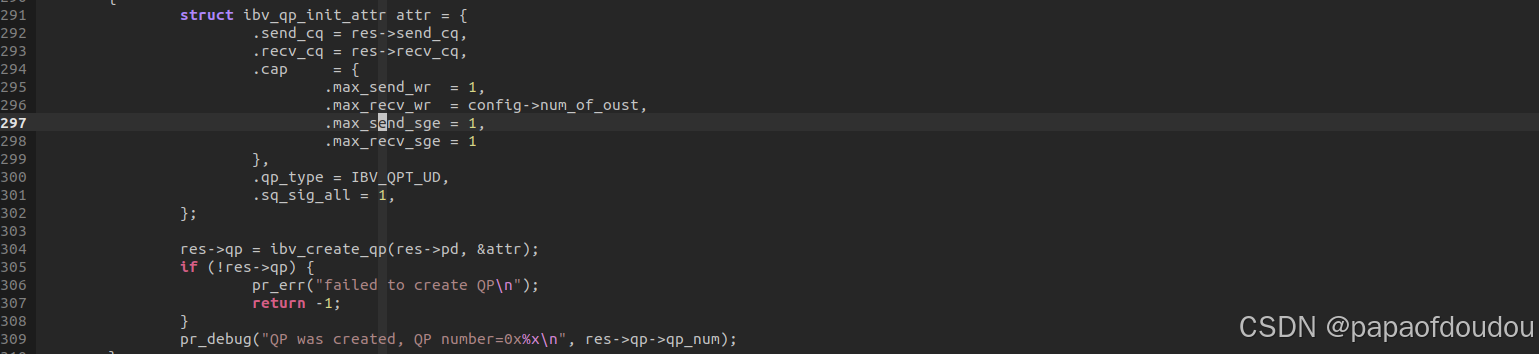
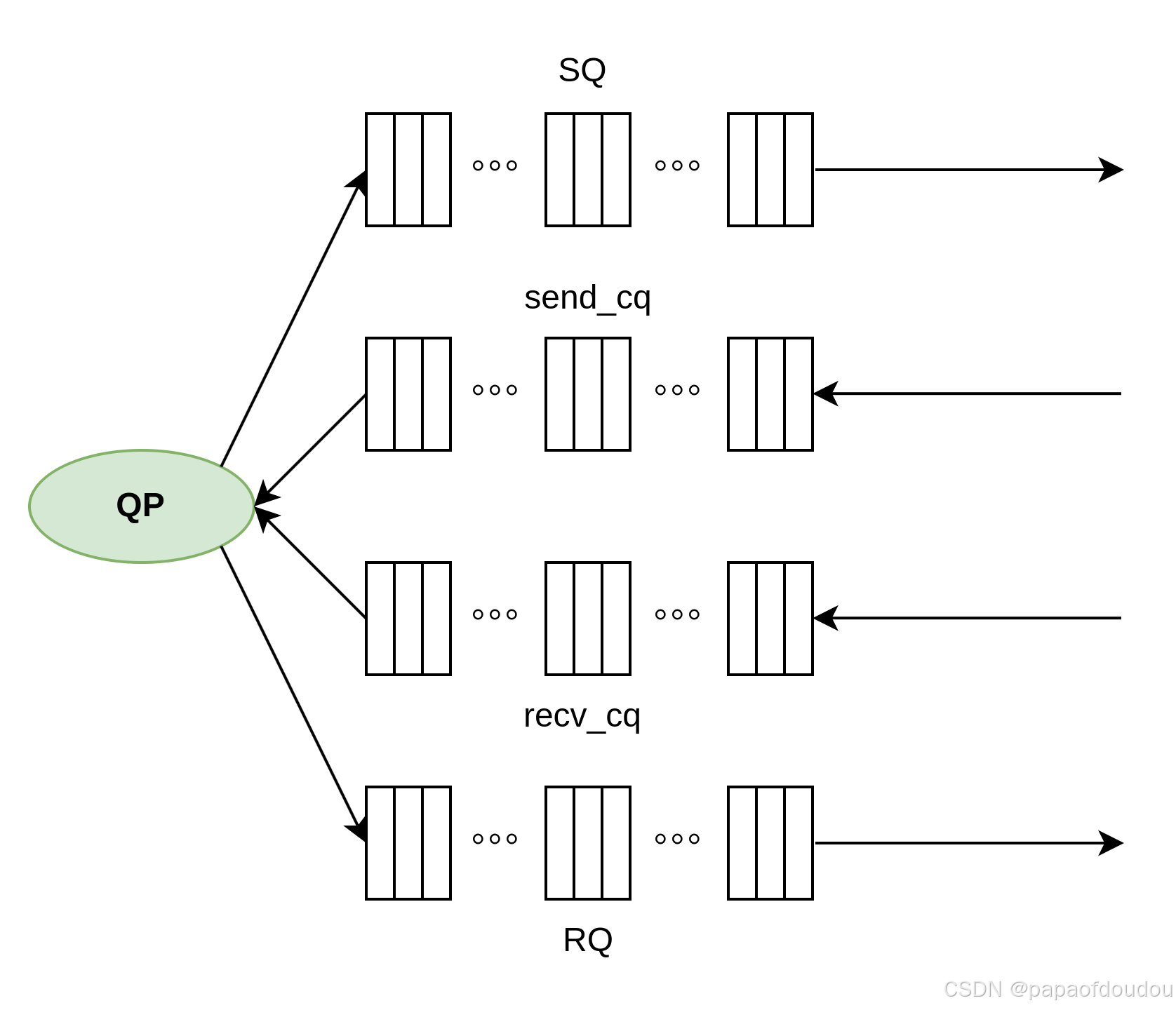
并且硬件设计也完美符合这个模型:
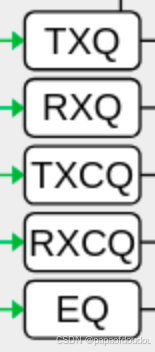
所以可以看出,普通网卡的一个收发队列相当于RDMA中的一个QP,对于一些简化网卡实现,确实就是例化RDMA中的一个QP来实现的。
总结:其实普通网卡也是由N个SQ,N个RQ组成,散列管理,但是RDMA网卡作了进一步抽象,提取一个SQ,一个RQ,包装成QP,这样就有N个QP了,从这N个QP中拿出一个或者多个QP出来,负责以太网包的处理,就是利用RDMA机制实现普通网卡功能的RDMA网卡。
方框图中还有一个EQ,在驱动代码中也有体现,它应该是一个硬件上报事件的队列,本质上也是个Ringbuffer,BUF分配方式也是调用dma_alloc_coherent,在文件mqnic_eq.c中:

一致性DMA内存分配和流式DMA映射的区别
struct mqnic_desc描述符中的addr/len字段用来记录发送/接收数据的长度和地址信息,注意到发送队列和接收队列的描述符是一样的。
在网卡驱动中,发送/接收队列使用的是一致性dma内存分配接口dma_alloc_coherent分配的,其特点是不需要软件维护DMA和CACHE一致性信息,依赖于CPU架构的不同,对于X86来说,是通过硬件保证CPU和DMA CACHE一致性的,而对于ARM架构来说,则是在分配的时候,DISABLE页表的CACHE位实现的。不同的架构下必须实现这两个函数arch_sync_dma_for_device/arch_sync_dma_for_cpu,对于硬件支持一致性的CPU架构,LINUX还提供了通用的实现(这种情况下是空函数).

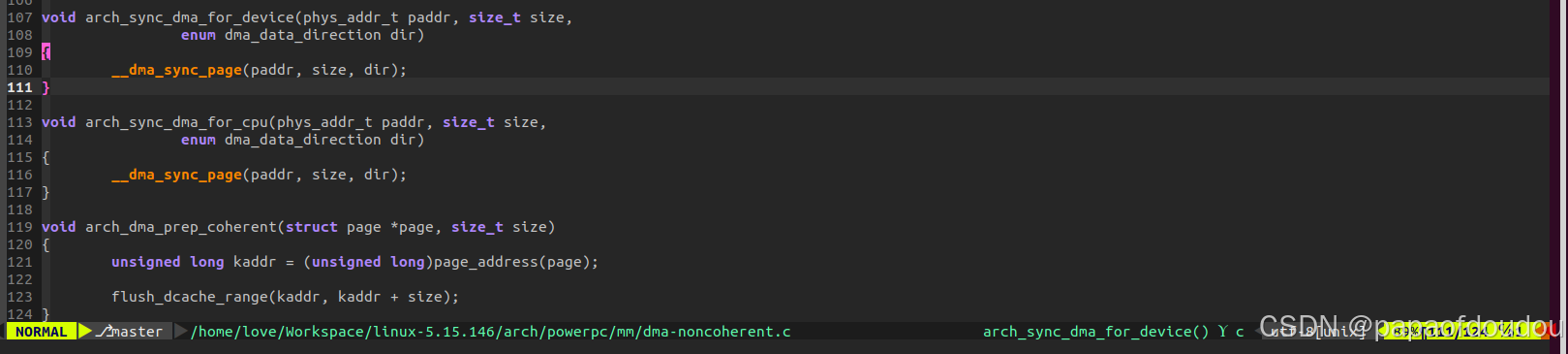
和发送/接受队列不同,描述符中记录的二级指针代表的发送/接收 PAYLOAD地址,比如skb->data,是由内核网络栈分配的连续内存,它并不属于网络驱动,所以使用流式DMA映射,保证在CPU填充完数据交给网卡硬件发送之前,或者由网卡接收后,转交给CPU读取之前,进行DMA缓存一致性处理。
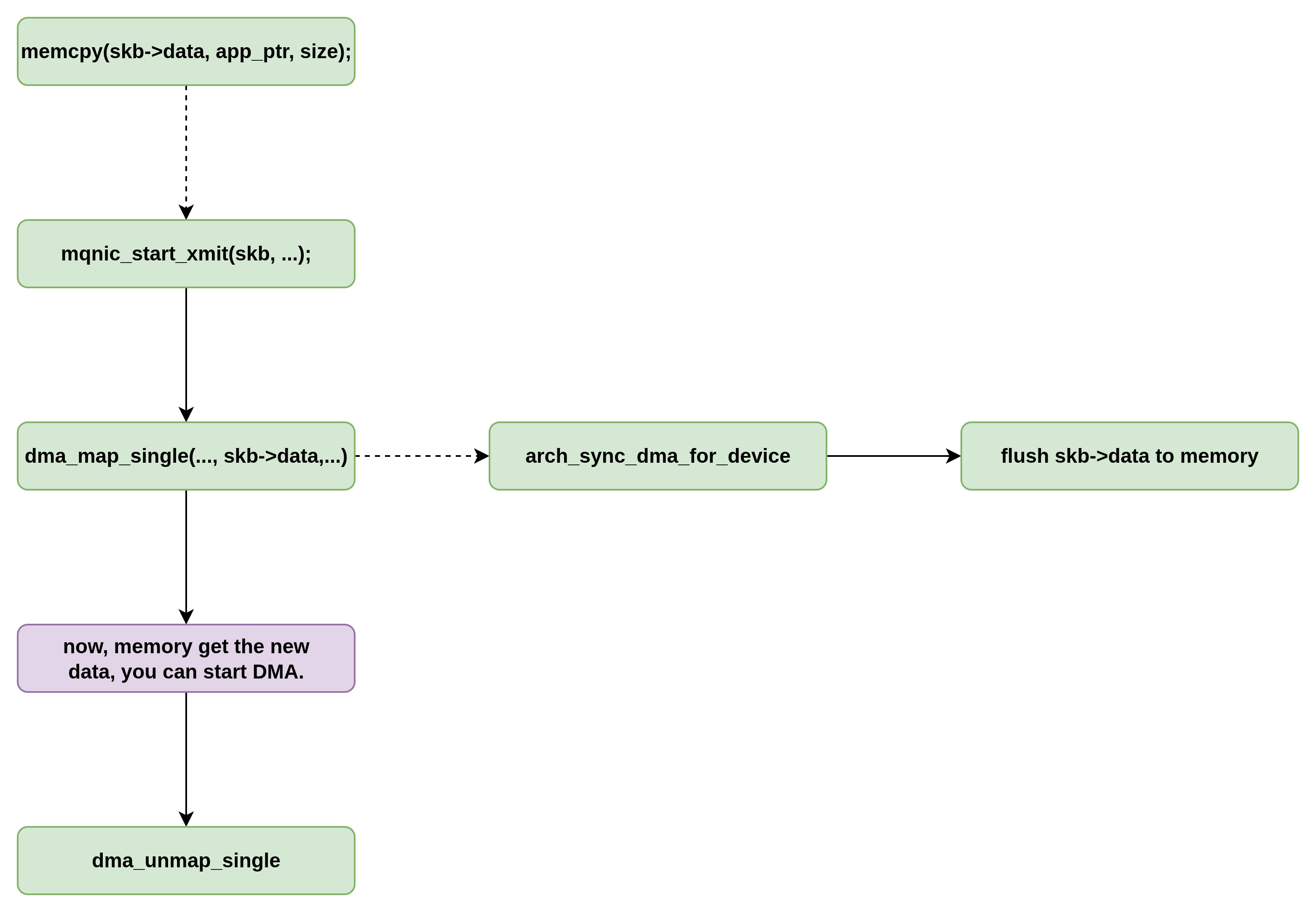
比如,对于发送处理来说,mqnic_start_xmit->mqnic_map_skb->dma_map_single(ring->dev, skb->data, len, DMA_TO_DEVICE);DMA_TO_DEVICE其作用告知CPU刷新一次CACHE,如果CACHE中有这段地址的脏数据,就把CACHE LINE中的数据回刷主机内存,这样硬件才能确保从主机内存读到最新的数据,协议栈在分配内存的时候,并不知道某个数据包是否要被硬件读取,因此并没有向分配一致性DMA缓存那样DISABLE CPU页表的CACHE属性。数据包所在的内icun通常都是使能CACHE的。
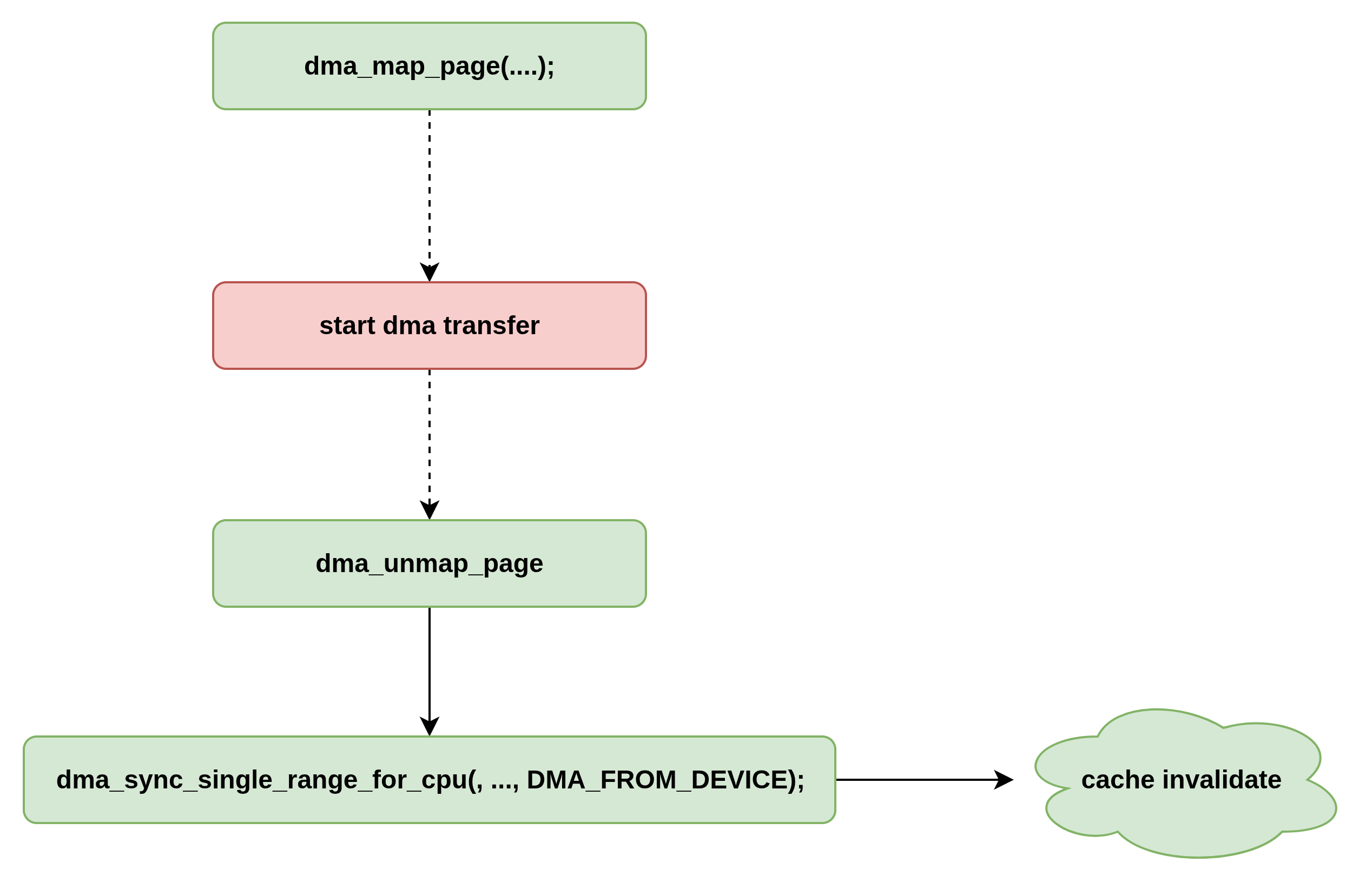
而对于接受来说恰恰相反,调用路径netif_napi_add->mqnic_poll_rx_cq->mqnic_process_rx_cq->mqnic_prepare_rx_desc->dma_map_page(ring->dev, page, 0, len, DMA_FROM_DEVICE);
DMA_FROM_DEVICE其作用是驱动程序申请一段缓存给硬件填充数据,为了保证CPU能够读取硬件写入的数据,需要这个参数告诉dma_map_page函数,在调用路径中“invalid cpu data cache"就是将数据CACHE中和这段地址相关的CACHELINE设置为无效,这样CPU之后直接从主机内存中读取这段地址中的数据,就是硬件最新写入的。
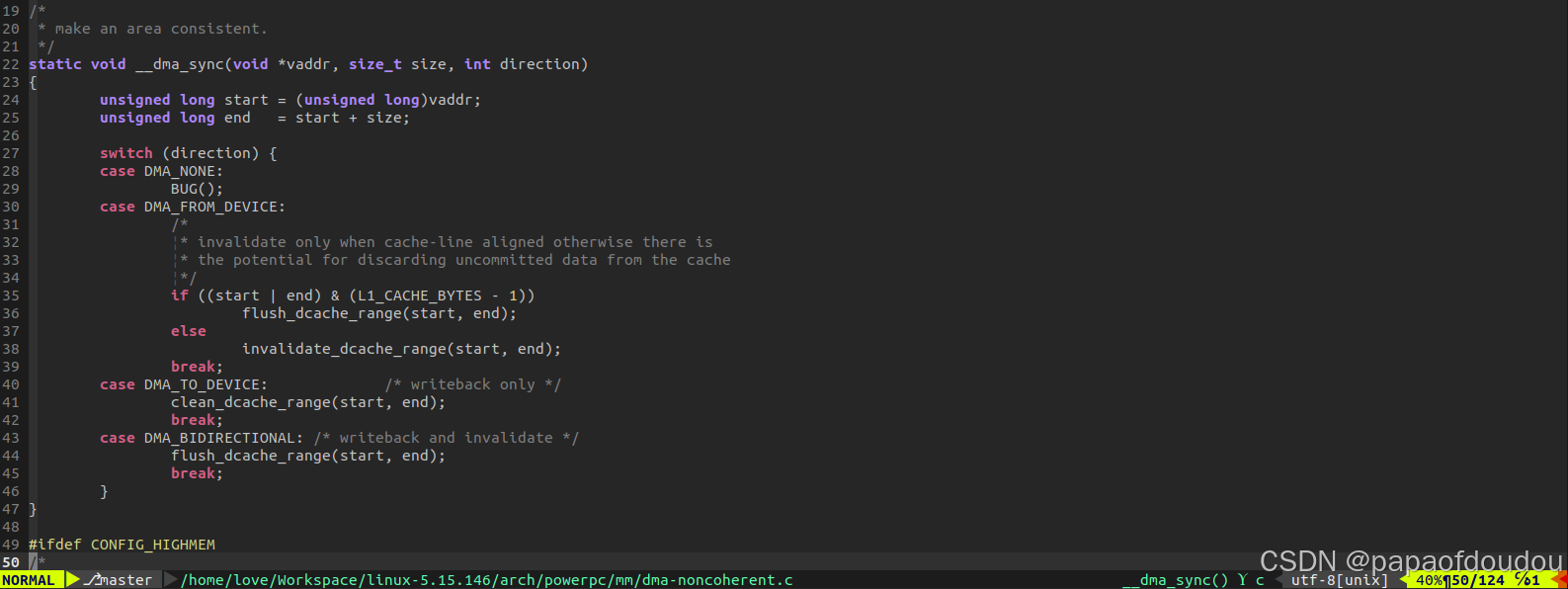
内核提供的dma_map_single/dma_map_page等函数会调用各CPU体系结构提供的arch_sync_dma_for_device函数,对于这个函数的实现,PowerPC体系结构的代码写的比较清晰,可以参考,下面是对这段代码的解释:
DMA_FROM_DEVICE:对于数据搬运方向为DMA_FROM_DEVICE(设备向主存写数据)的缓存,把数据Cache中和这段地址有关的Cacheline设置为无效(invalid data cache),作用是让CPU之后直接从主机内存读取这段地址的数据,对于非Cacheline对齐的数据,改为"flush data cache line",即刷新数据Cache中和这段地址有关的Cacheline,原因是此时Cacheline中可能含有不属于缓存地址范围的数据,需要将这些数据先写入内存,再把cacheline设置为无效。
DMA_TO_DEVICE:对于数据搬运方向为DMA_TO_DEVICE(设备从主存读数据)的缓存,操作为"clean data cache",作用是将数据cache中和这段地址有关的cacheline的数据写入主机内存。
DMA_BIDIRECTIONAL:对于双向缓存,操作为"flush data cache",也就是先把数据cache中和这段地址有关的cache line的数据写入内存,然后把cacheline设置为无效,让CPU之后直接从内存读取这段地址的数据。
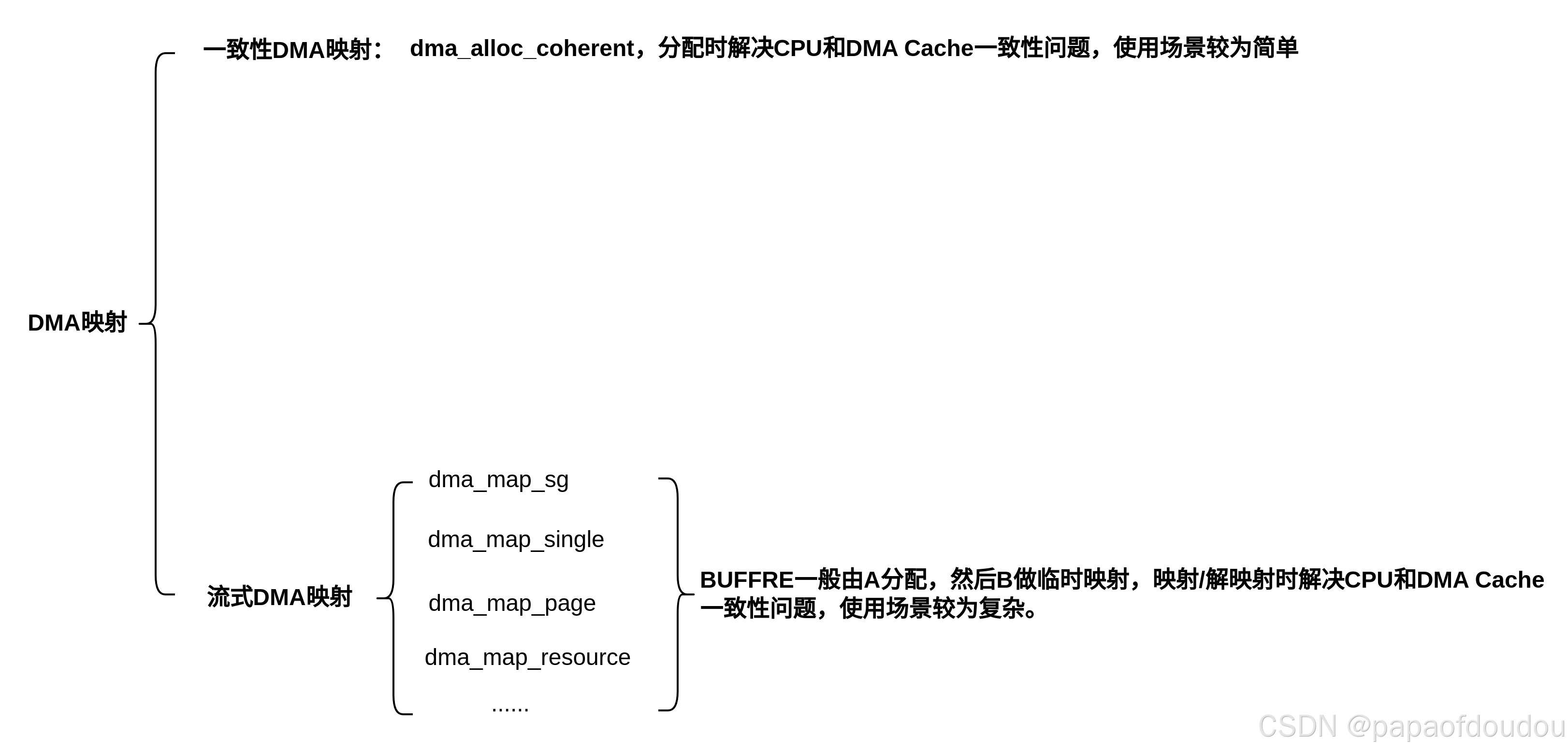
所以,一致性DMA内存分配和流式DMA内存映射的区别概括起来主要有亮点:
1.一致性DMA内存分配包括分配+IOMMU映射,而流式DMA内存映射只有 IOMMU映射,不包分配。
2.一致性DMA内存分配不需要软件关心CPU和DMA的CACHE一致性问题,映射的时候已经解决了,而流式的需要。
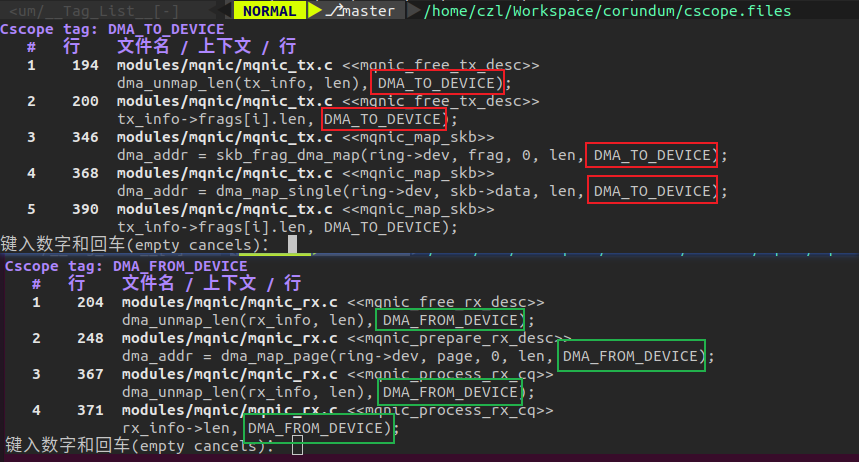
DMA_TO_DEVICE用在网卡的TX处理流程中,DMA_FROM_DEVICE用在网卡的RX处理流程中。
发送时的CACHE一致性维护:
接收时的CACHE一致性维护
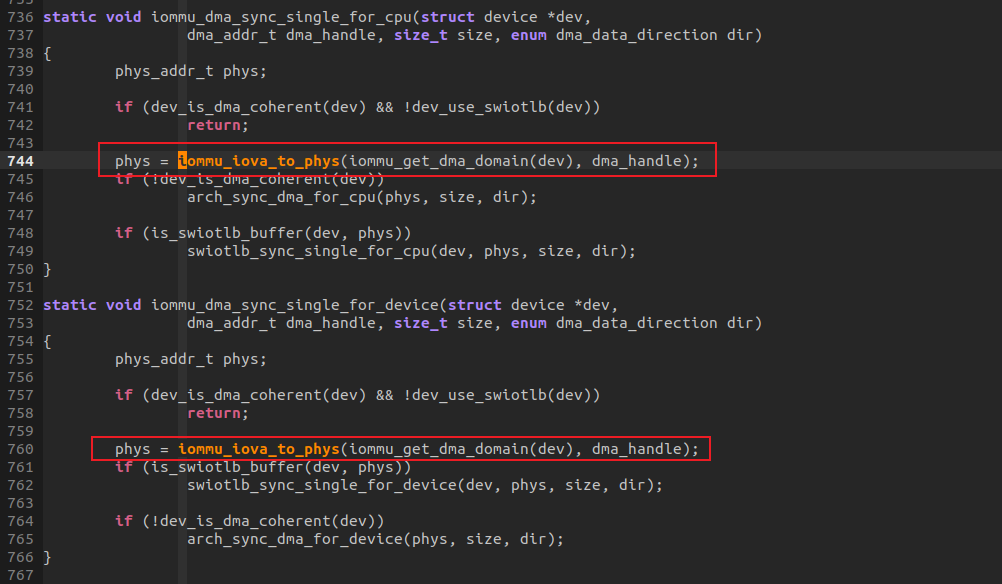
dma_sync_single_range_for_cpu/dma_sync_single_range_for_device/dma_sync_sgtable_for_cpu/dma_sync_sgtable_for_device进行CACHE一致性操作的指令使用的是BUF 物理地址,但是函数传入的时候,使用的dma_addr(iova)或者SGTABLE,函数内部会进行转换。
读写指针管理
和传统的ringbuffer管理机制不同,corundum驱动实现的时候,接收队列和发送队列的producer ptr和consumer ptr(其实是mqnic_desc idx)都是单调递增的,当软件填满队列后,不会把队列的producer index置0,而是继续加1,这样作的好处是在判断队列是否已满时可用producer index - consumer index,如果其值等于描述符的总个数,则队列已满。当索引队列元素的时候,则是 producer_index&size_mask, size_mask则是队列长度减1,比如队列长度4096时,使index = produer & 0xFFF,这样算出来的index就可以作为索引区访问队列成员了,这种情况下,需要把size设置为2的N次幂。
参考其实现自己实现了一个读写offset无回绕的rinbuf,在如下连接:
https://gitee.com/tugouxp/ringbuf/blob/master/ringbufnew.c
使用单调增长的方式管理读写指针另一个好处就是不用浪费一个ITEM的空间用于判断BUFFER的满状态,由于传统取对SIZE取模回绕读写指针方式会丢失索引的高位信息,所以必须牺牲一个空间来判满,但是如果使用单调递增的方式管理读写指针,就不需要浪费这一个ITEM空间了。
struct net_device_ops mqnic_netdev_ops
网络设备是完成用户数据包在网络媒介上发送和接收的设备,它将上层协议传递下来的数据包以特定的媒介访问控制方式进行发送,并将接收到的数据包传递给上层协议。
发送路径必然调用.ndo_start_xmit,net_device_ops中没有定义接收回调,因为这个结构体只定义了从内核网络协议栈中调用下来的函数,而接收函数不属于这种,接收函数的发起端寄生在设备中断中.
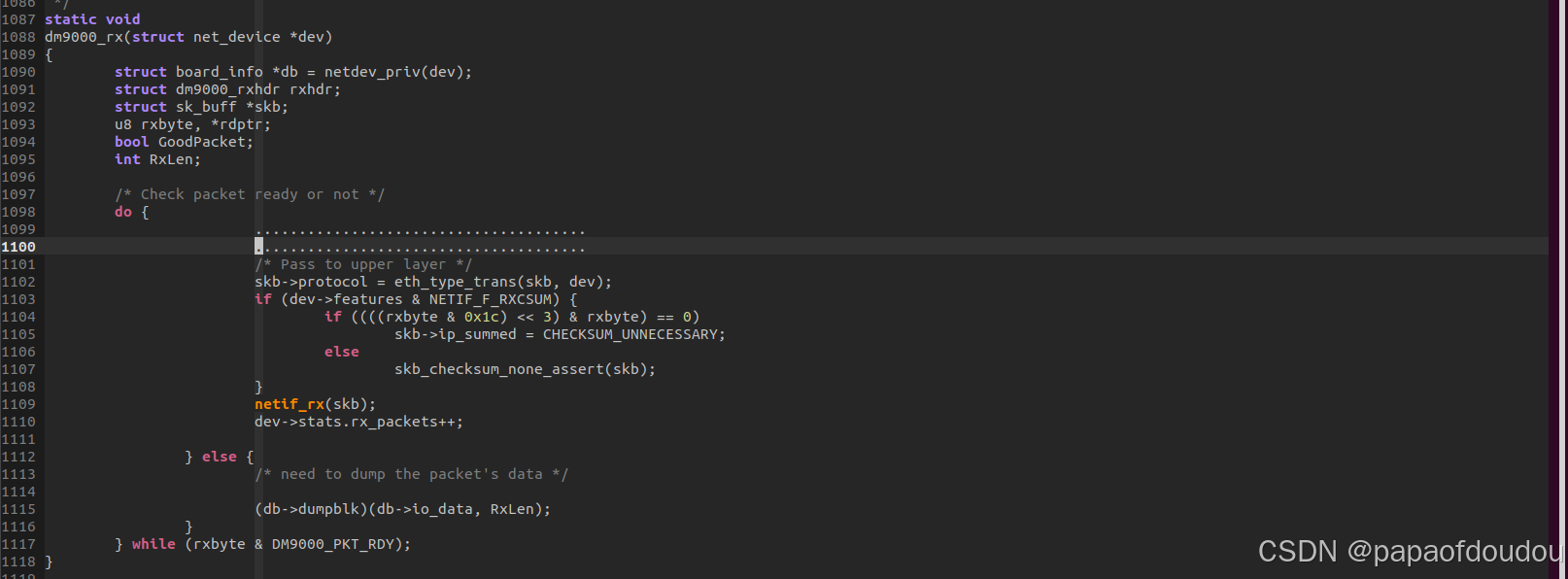

loopback netif
由于本地回环的特殊性,loopback的net_device_ops定义中,是在nod_start_xmit函数中调用netif_rx接收回调的,毕竟,本地回环的意思就是发送和接收直接短接的。

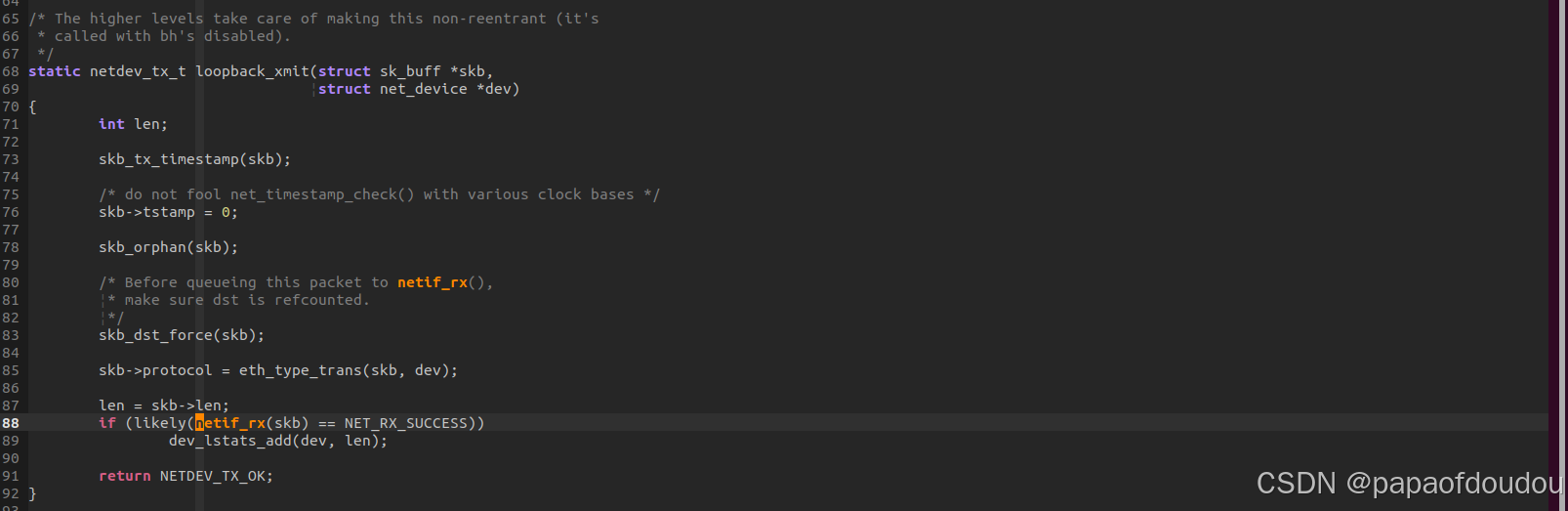
wifi net_device_ops:
红米笔记本使用ieee80211的ops.系统初始化过程中,用户态网络管理程序NetworkManager通过NETLINK建立 WIFI 网络接口的链接。

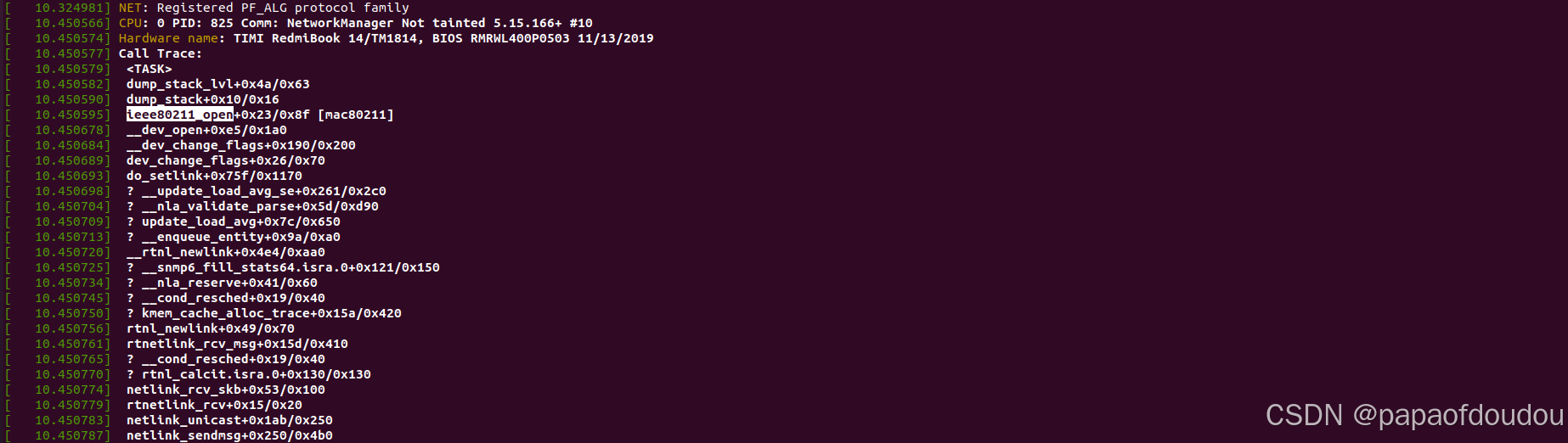
除了前面提到的在系统启动阶段调用ieee80211_open之外,用户还可以通过如下命令触发ieee80211_open/ieee80211_stop.
sudo ifconfig wlp0s20f3 down
sudo ifconfig wlp0s20f3 up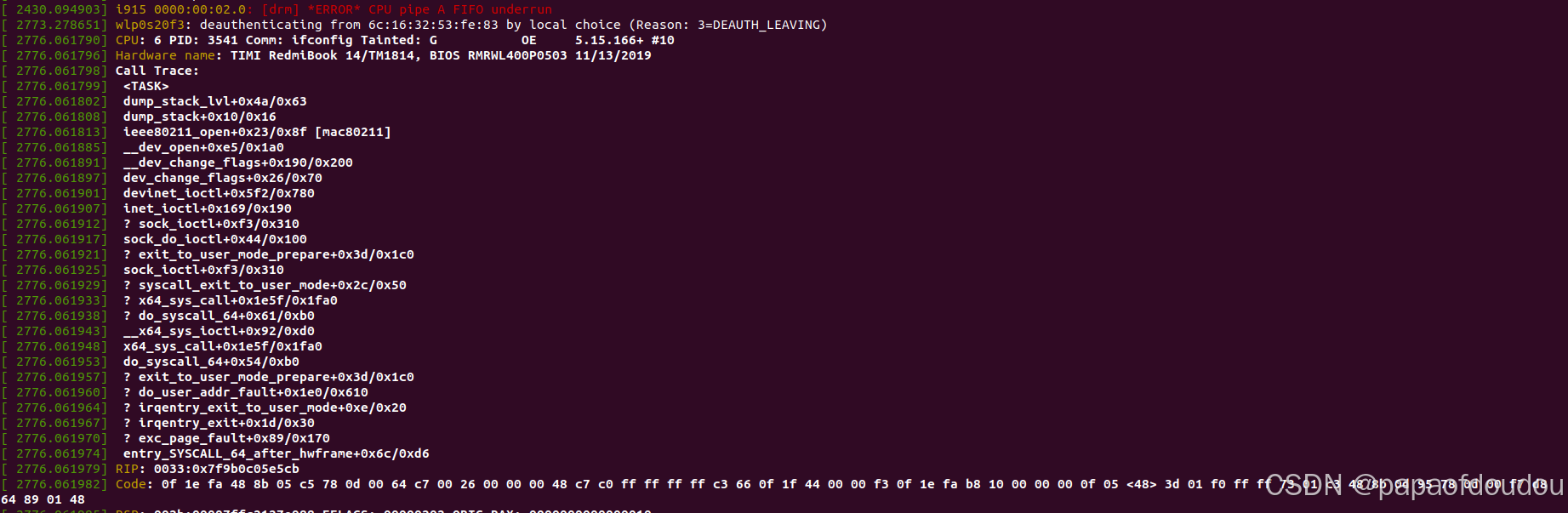
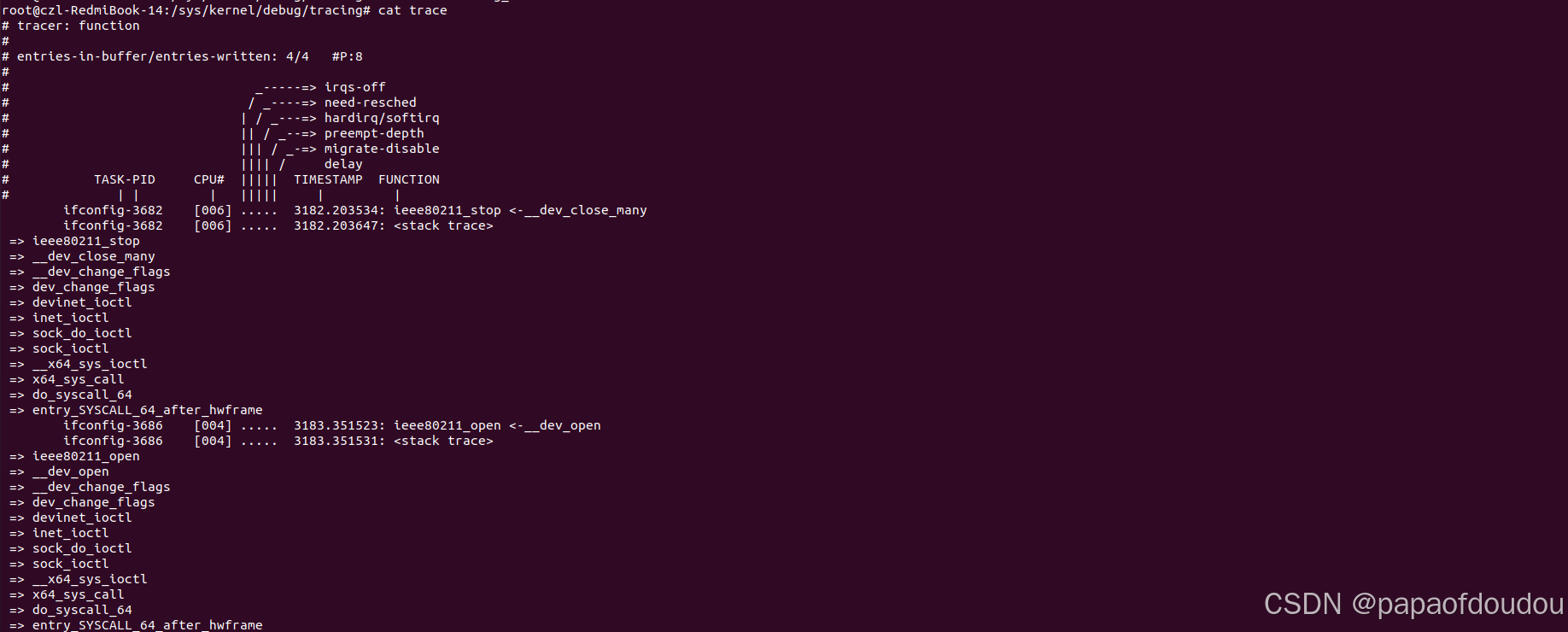
貌似NAPI情况下,接收SKB处理不是调用netif_rx,而是如下堆栈,msix handler是INTEL WIFI无线网卡的中断处理程序。

NAPI
通常情况下,网络设备驱动以中断方式接收数据包,另外一种数据接收方式是NAPI(New API),其数据接收流程为“接收中断来临->关闭接收中断->以轮询方式接收所有数据包直到收空->开启接收中断->接收中断来临.....".内核提供了如下NAPI相关的API:netif_napi_add/netif_napi_del


几个问题点
1.角色分配,无论发送队列还是接收队列,都是软件做为producer,硬件作为consumer的角色,发送队列这样作还能理解,为何接收队列也这样作呢? 毕竟发送队列,软件确确实实是生产者的角色,但是对于接收队列来说,明明是硬件生产数据,软件消费数据的。
其实可以反过来想,接收队列不正是软件生产空包,硬件消费空包吗?
2.完成进度由cq队列中的struct mqnic_cpl->index记录,用于更新consumer pointer.

3.发送队列和接收队列都是通过dma_alloc_coherent(一致性DMA映射,驱动分配,生命周期和驱动相同,解决了CPU和DMA一致性问题)分配DMA Buffer的,DMA Buffer里面装的是描述符,描述了通过dma_map_single(流式DMA映射,BUF并非由网卡驱动分配,而是网络栈分配,典型的就是skb->data,内核网络协议栈用alloc_pages/kmalloc等返回内核逻辑地址的接口分配,CPU CACHE属性,可以很容易转换为PAGE对象,CPU和DMA设备之间的一致性问题需要驱动aware并维护)分配的skb buffer地址,对于发送来说,这个buffer是业务分配的,但是对于接收来说,需要网卡驱动主动分配,准备BUFFER。
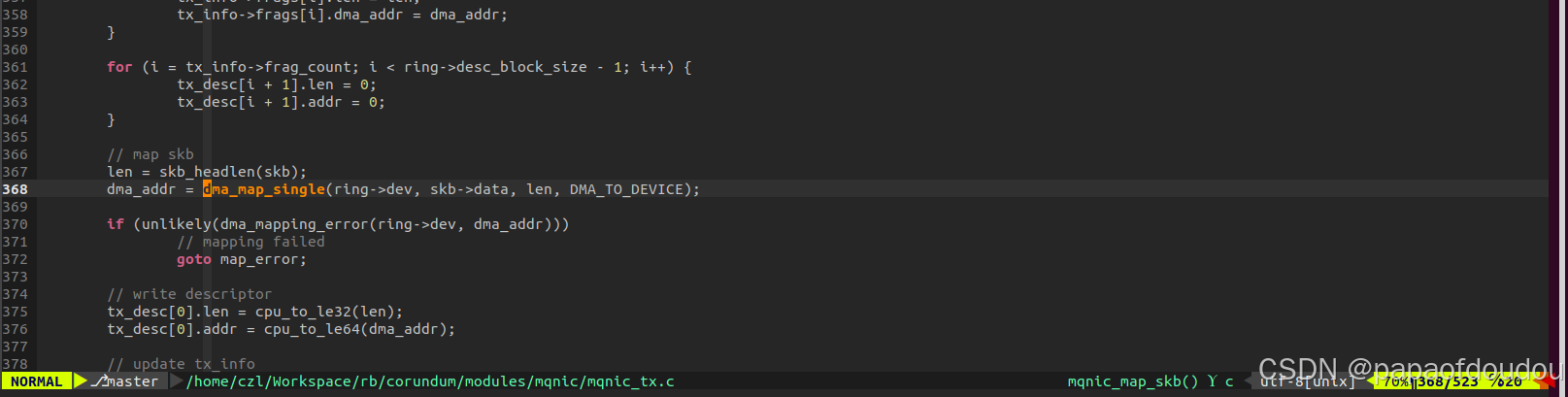
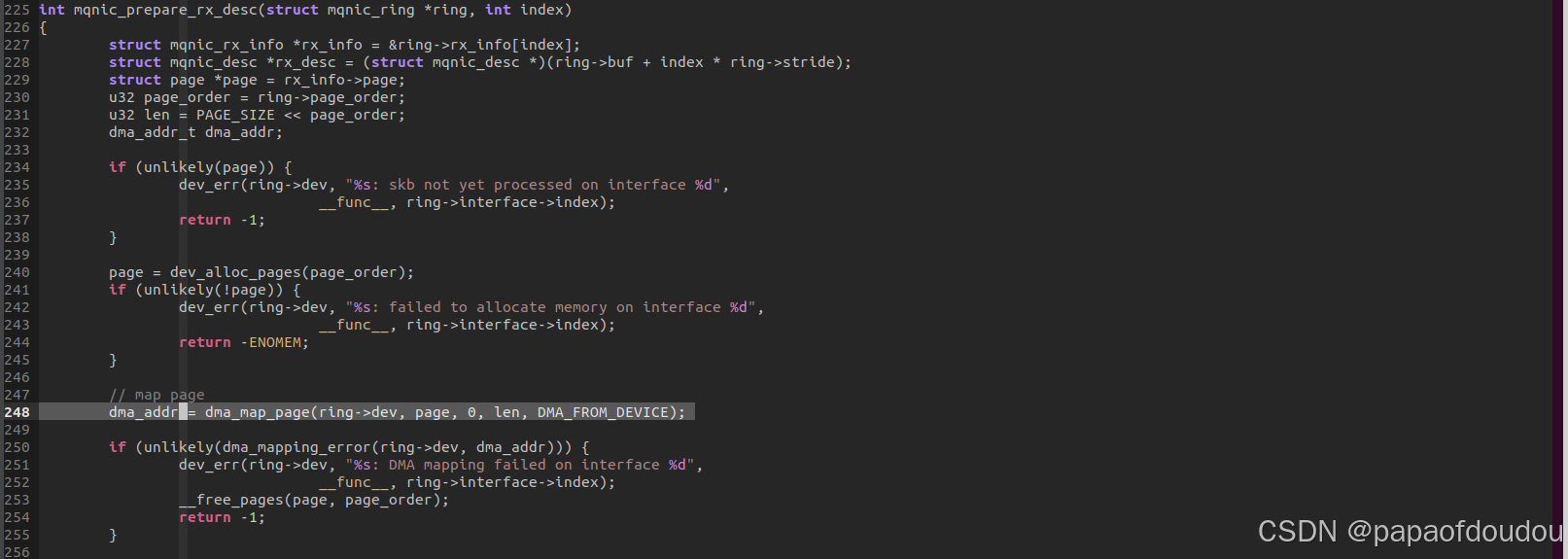
其中dev是设备的指针,size是申请内存的大小。dma_addr是硬件访问这片内存所需要提供的DMA地址(iova地址,需要经过系统IOMMU翻译),gfp用于属性控制,我们目前不关心。而返回值cpu_virt_addr则是CPU访问这片内存所需要使用的虚拟地址。

从SKB Buffer获取队列号
skb_get_queue_mapping/skb_set_queue_mapping:

DPDK
DPDK没有实现网络协议栈,网络协议栈由用户应用实现。
【DPDK】基于dpdk实现用户态UDP网络协议栈_dpdk udp-优快云博客
其它类型的网卡驱动分析
以ZXDH为例,它是ZTE针对自家的E312网卡的驱动,支持标准以太网以及RDMA(RoCEv2),项目仓库位于:anolis/kmod-dinghai
其tx/rx发送队列完全复制了virtio中vring queue的实现,连API都没有变,如下分别是ZX网卡驱动代码中的vring_alloc_queue实现和内核主线vring_alloc_queue的实现,可以看到完全一样:


ZX这样的实现相当于使用他们的网卡硬件作为virtio的后端,复用了virtio的代码.最终这些virqueue会绑定到以太网卡硬件的收发队列上。
https://docs.oasis-open.org/virtio/virtio/v1.2/cs01/virtio-v1.2-cs01.pdf
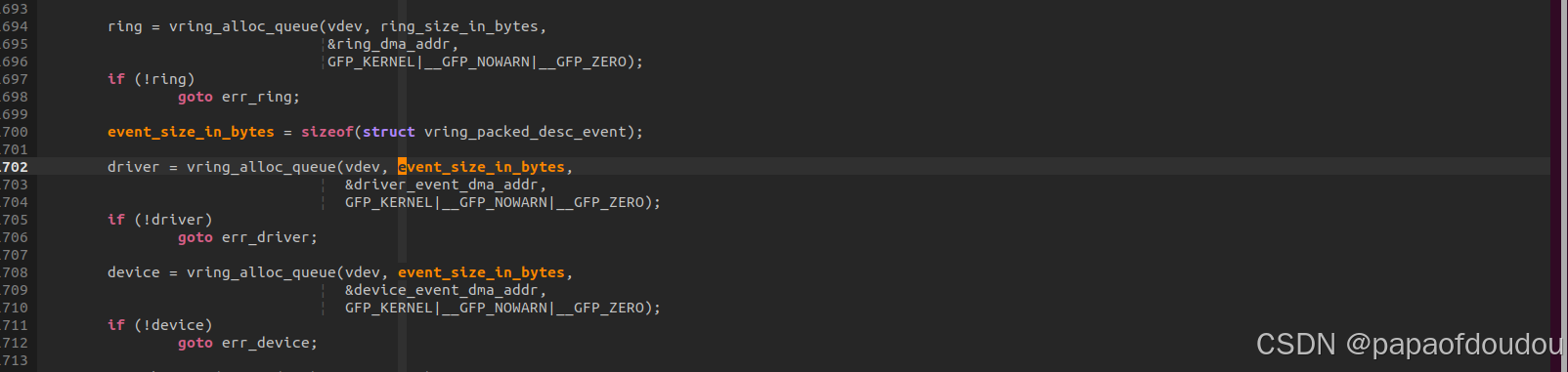
zxdh甚至将virtqueue的后端原封不动硬件化了,这一点可以从vq->packed.vring.driver/vq->packed.vring.device的分配看出来:


网卡LOOPBACKS设计
数据在经过协议栈软硬件的不同实现层中,都可以(必须)设计LOOPBACK机制:




队列数是从寄存器中获取,这表明支持多少个队列,是网卡自身的一个重要feature.
参考文章
Corundum开源100G网卡调试总结_corundum fpga-优快云博客



















 216
216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











