






腾讯云Cloud Studio × DeepSeek-R1:零成本解锁大模型开发全流程解析
——手把手教你用免费10000分钟算力构建AI应用实例
引言:当免费算力遇上国产大模型
在AI技术爆发的2025年,腾讯云Cloud Studio凭借其内置的Ollama框架与DeepSeek-R1系列大模型,为开发者提供了一条“零成本体验→快速部署→高效开发”的捷径。每月10000分钟的免费GPU算力(约166小时),搭配从1.5B到32B的多规格模型选择,让个人开发者和小型团队也能轻松驾驭百亿级参数的AI能力。本文将以实战视角,详解如何利用这一组合工具链,从环境搭建到商业级应用开发,并附完整代码实例。
第一章:环境搭建与模型部署
1.1 注册与空间创建
步骤1:注册腾讯云账号
访问[腾讯云官网:https://curl.qcloud.com/VvRu5feD,完成实名认证并开通Cloud Studio服务(新用户可享免费额度)。

步骤2:选择DeepSeek-R1模板
进入Cloud Studio控制台,点击「新建工作空间」,在「空间模板」中选择「DeepSeek-R1」模板。根据需求选择规格:
- 轻量型:适合1.5B/7B模型(CPU推理)
- 基础型:支持7B/14B/32B(16G显存)
- HAI进阶型:32G显存,支持高速推理。
步骤3:启动空间
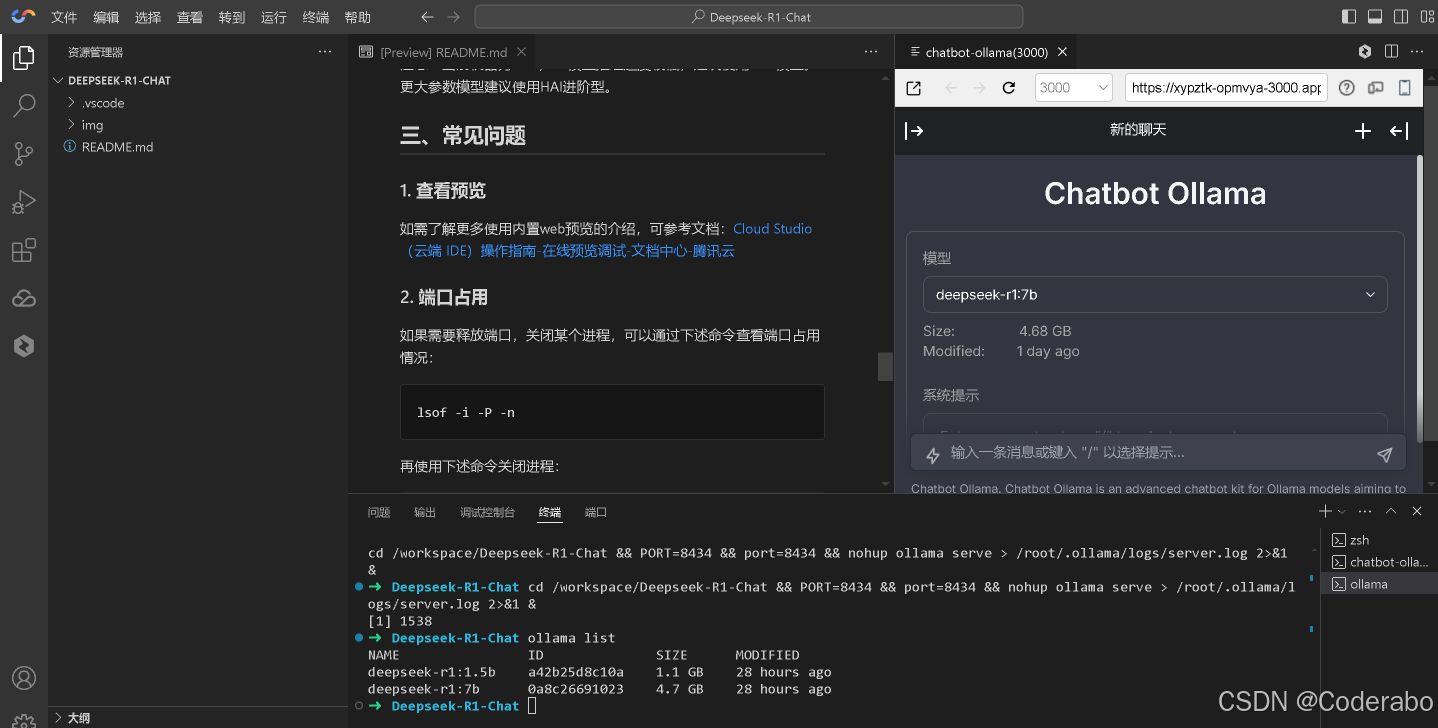
创建后等待1-2分钟,系统自动完成Ollama环境与预装模型的部署。点击「进入」跳转至VSCode风格的开发界面。
1.2 模型管理与验证
## 代码1:查看预装模型列表
ollama list
输出示例:
NAME SIZE
deepseek-r1:1.5b 1.5B
deepseek-r1:7b 7B
## 代码2:启动交互式对话(以7B模型为例)
ollama run deepseek-r1:7b
输入测试指令验证模型响应:
>>> 用Python实现快速排序算法
DeepSeek-R1:
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
第二章:API调用与集成开发
2.1 本地API服务配置
步骤1:查询Ollama服务端口
默认端口为11434(基础型)或8434(轻量型),通过以下命令确认:
lsof -i -P -n | grep ollama
## 代码3:CURL调用示例(生成模式)
curl -X POST http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:7b",
"prompt": "为新能源车企写一段200字的品牌宣传文案",
"stream": false
}'
## 代码4:Python SDK封装(支持流式输出)
import requests
import json
def deepseek_generate(prompt, model="deepseek-r1:7b", stream=False):
url = "http://localhost:11434/api/generate"
payload = {
"model": model,
"prompt": prompt,
"stream": stream
}
response = requests.post(url, json=payload)
if stream:
for line in response.iter_lines():
if line:
yield json.loads(line.decode('utf-8'))["response"]
else:
return response.json()["response"]
# 示例调用
result = deepseek_generate("解释Transformer架构的核心思想")
print(result)
2.2 外网访问与生产级部署
问题:Cloud Studio默认不开放外网端口,需借助反向代理工具。
## 代码5:使用Ngrok暴露API服务
# 安装Ngrok
wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
unzip ngrok-stable-linux-amd64.zip
# 启动端口映射(假设Ollama端口为11434)
./ngrok http 11434
获取Ngrok提供的公网URL(如https://abc123.ngrok-free.app),即可通过外网调用API。
第三章:实战案例——构建智能客服系统
3.1 架构设计
- 前端:Vue.js + WebSocket(实时对话)
- 后端:Flask + Ollama API
- 数据库:腾讯云对象存储COS(历史记录)
3.2 核心代码实现
## 代码6:Flask后端接口(app.py)
from flask import Flask, request, jsonify
from flask_cors import CORS
import requests
app = Flask(__name__)
CORS(app)
OLLAMA_URL = "http://localhost:11434/api/generate"
@app.route('/chat', methods=['POST'])
def chat():
data = request.json
response = requests.post(
OLLAMA_URL,
json={
"model": "deepseek-r1:7b",
"prompt": data['message'],
"stream": False
}
)
return jsonify({"reply": response.json()["response"]})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
## 代码7:Vue前端组件(Chat.vue)
<template>
<div>
<div v-for="(msg, index) in messages" :key="index">
<p :class="msg.role">{{ msg.content }}</p>
</div>
<input v-model="inputMsg" @keyup.enter="sendMessage" />
</div>
</template>
<script>
export default {
data() {
return {
inputMsg: '',
messages: []
}
},
methods: {
async sendMessage() {
this.messages.push({ role: 'user', content: this.inputMsg });
const response = await fetch('http://localhost:5000/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message: this.inputMsg })
});
const data = await response.json();
this.messages.push({ role: 'assistant', content: data.reply });
this.inputMsg = '';
}
}
}
</script>
第四章:高级技巧与优化策略
4.1 模型微调与领域适配
步骤:准备领域数据集(如医疗问答数据),通过Modelfile定制模型:
# 创建Modelfile
FROM deepseek-r1:7b
PARAMETER temperature 0.3
SYSTEM """
你是一名三甲医院的AI医生助手,需根据最新医学指南回答患者问题。
"""
# 构建自定义模型
ollama create my-medical -f Modelfile
4.2 性能调优
- GPU加速:在HAI进阶型中启用CUDA驱动
- 量化压缩:使用4-bit量化模型减少显存占用
ollama pull deepseek-r1:7b-q4_0
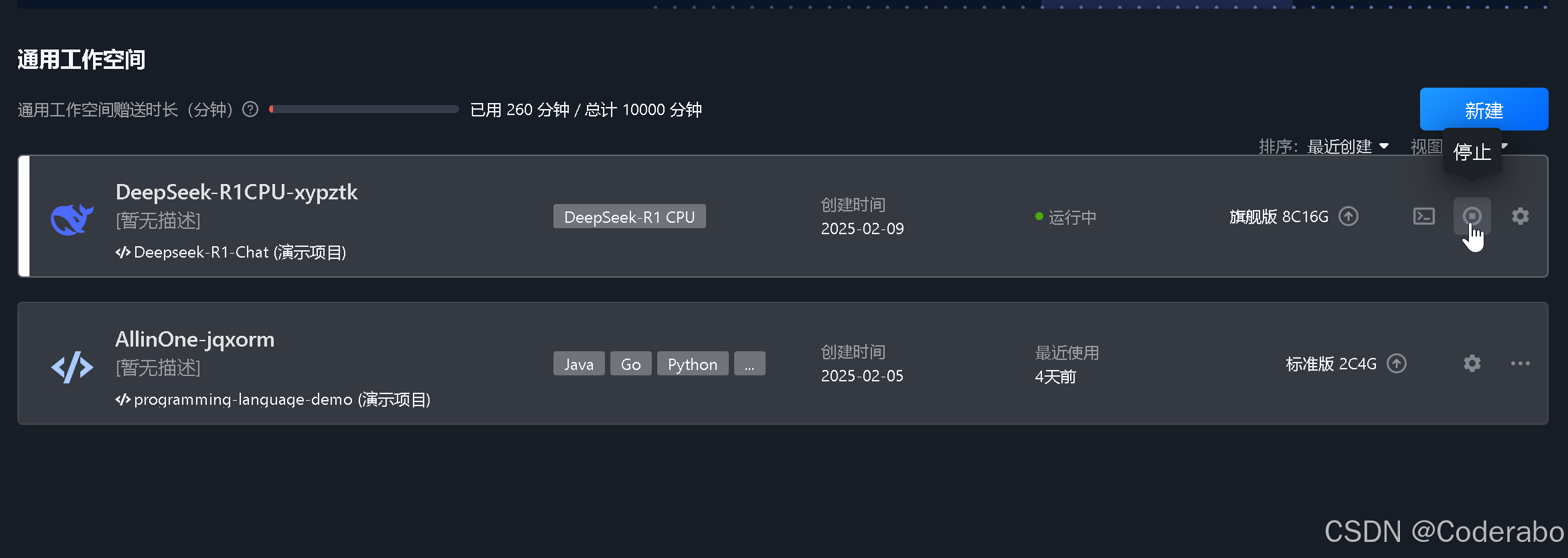
第五章:免费额度管理与成本控制
- 监控使用时长:Cloud Studio控制台实时显示剩余分钟数
- 关机策略:非活跃时通过CLI或界面手动关闭空间
# 查看运行状态
cloudstudio status
# 关闭空间
cloudstudio stop
结语:AI普惠化时代的开发者红利
通过腾讯云Cloud Studio与DeepSeek-R1的组合,开发者无需担忧硬件采购、环境配置与算力成本,即可快速验证AI创意。无论是构建智能客服、代码助手,还是垂直领域知识引擎,这套方案都提供了从实验到生产的完整路径。立即行动,用每月10000分钟的免费额度,不用时记得要关一下机。开启你的大模型之旅!



















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











