







深度学习模型的训练过程中,有一些关键的超参数需要我们在训练前设定,其中最重要的包括训练轮数(Epochs)、学习率(Learning Rate)和批大小(Batch Size)。这些超参数对模型的性能、收敛速度和稳定性有巨大的影响。
文章目录
1 Epochs
简单来说,1个epoch = 模型看完整个训练集一遍。如果你有10000张图片,训练5个epochs就意味着模型会把这10000张图片学习5遍。模型第一次看到数据时,只能学到非常粗糙的模式。每次epoch后,模型的参数都会根据误差调整。下一轮再看数据时,它在已有的基础上学得更细。
| Epoch 数量 | 效果 |
|---|---|
| 太少(如 1-5) | 欠拟合,模型还没学会 |
| 适中(如 20-100) | 模型学得差不多了 |
| 太多(如 500+) | 过拟合,死记硬背,不会举一反三 |
如何确定合适的 Epochs?
1. 使用早停法(Early Stopping)
from tensorflow.keras.callbacks import EarlyStopping
# 如果验证集损失连续5轮没有改善,就停止训练
early_stopping = EarlyStopping(
monitor='val_loss',
patience=5,
restore_best_weights=True
)
model.fit(X_train, y_train,
epochs=100, # 设置一个较大的上限
validation_split=0.2,
callbacks=[early_stopping])
2. 观察学习曲线
理想的情况是:训练损失和验证损失都在下降,且两条曲线之间的差距不大。如果验证损失在某个点后不再下降或开始上升,则表示该停止了。
3.经验值
| 任务类型 | 建议 Epochs | 说明 |
|---|---|---|
| 图像分类(从头训练) | 50-200 | 取决于数据集大小 |
| 图像分类(微调) | 10-30 | 已有预训练模型 |
| BERT微调 | 2-5 | 大模型容易过拟合 |
| 简单MLP | 20-50 | 结构简单,收敛快 |
2 Learning Rate
学习率控制着模型沿着损失函数梯度下降时迈出的步伐有多大。在反向传播过程中,梯度指明了权重需要调整的方向和幅度,而学习率就是用于缩放梯度的系数:学习率越大,每次更新权重变化越大;学习率越小,每次更新幅度越小。
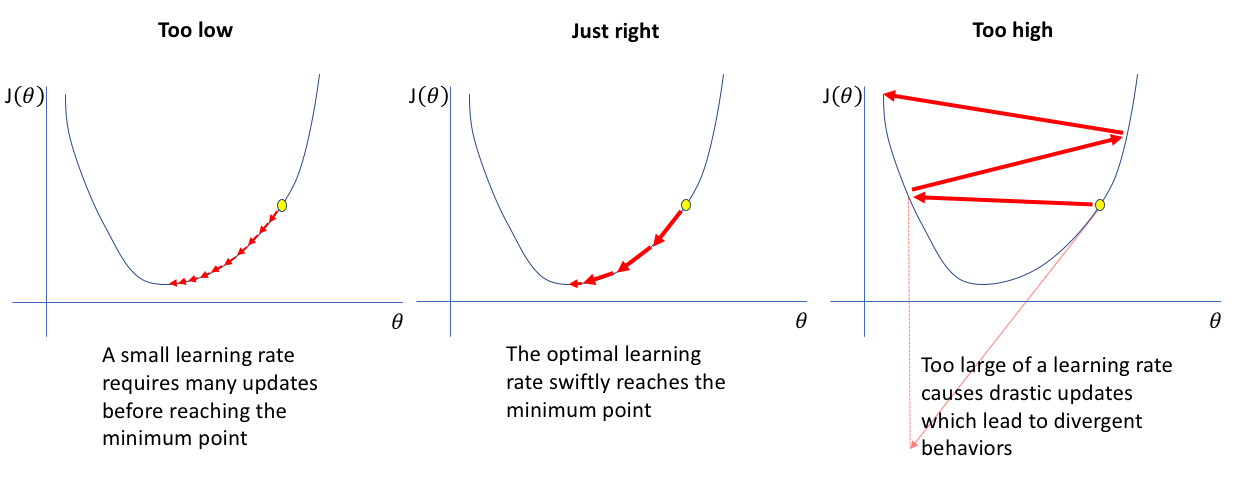
左图学习率太小,模型以很小的步伐缓慢下降;中图学习率适中,模型沿着陡峭方向快速收敛到最低点;右图学习率太大,模型每步跨幅过大,导致在最小值附近来回跳动甚至发散
| 学习率设定 | 表现 | 原因分析 | 优缺点 |
|---|---|---|---|
| 过大 | - 损失值剧烈震荡,像心电图一样 - 损失突然变成 N a N NaN NaN 或 i n f inf inf - 准确率忽高忽低,极不稳定 | 每次更新参数跨步过大,容易越过最优点,导致在最优值两侧反复震荡甚至发散 | **优点:**初期损失下降快 **缺点:**训练不稳定,可能发散,无法收敛 |
| 过小 | - 损失下降极其缓慢 - 多轮训练几乎无提升,模型像“卡住”了一样 | 每次只在损失面上迈出小碎步,进步微小,收敛速度慢 | **优点:**训练过程平稳,最终可能得到较优解 **缺点:**训练时间长,计算成本高,收敛慢 |
如何合理选择学习率?
实践中,一个合适的学习率是通过观察训练效果一步步调整出来。
1. 学习率查找器
从一个极小的学习率开始,逐渐增大(如每次乘1.1),每一步训练一小批数据,记录损失值。最后绘制出学习率 vs 损失曲线:
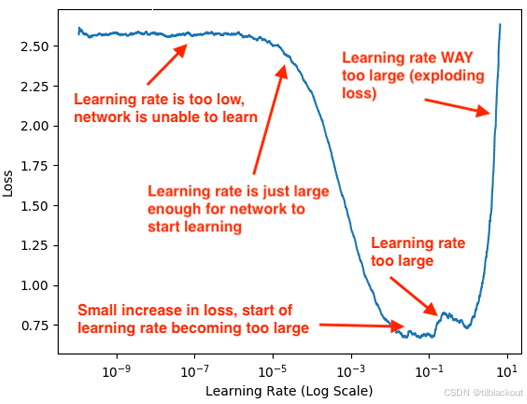
- 学习率太小时,损失下降非常慢
- 某一段范围内,损失快速下降
- 再往上,损失开始上升甚至发散
最佳学习率 ≈ 损失开始迅速上升前的值的一半
2.训练过程中逐步降低学习率
很少有模型能从头到尾都用同一个学习率。通常的做法是:前期用大一点的学习率:让损失快速下降;后期用小一点的学习率:更稳地靠近最优解。
以下是常见的动态调整策略:
- 固定步长衰减:每隔N个epoch把学习率乘以一个系数(如0.5)
- 平滑衰减:随着训练进程,学习率缓慢下降(如余弦函数式)
- 自动调整:如果验证集表现停滞一段时间,自动减小学习率
很多框架(Keras、PyTorch)已经内建了学习率调度器(scheduler)功能,可以自动帮你根据训练情况动态调整学习率:
from tensorflow.keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(
monitor='val_loss', # 监控验证集的损失
factor=0.5, # 学习率乘以0.5
patience=3, # 如果3个epoch验证损失都没提升,就触发调整
min_lr=1e-6 # 最小学习率下限,避免调得太低
)
还有Hugging Face Transformers库中用于学习率调度函数:
from transformers import get_cosine_with_hard_restarts_schedule_with_warmup
scheduler = get_cosine_with_hard_restarts_schedule_with_warmup(
optimizer, # 你的优化器
num_warmup_steps=1000, # warmup 步数
num_training_steps=10000, # 总训练步数
num_cycles=3 # 重启次数
)
^
| /\ /\ /\
| / \ / \ / \
| / \ / \ / \ <- Cosine decay with restarts
|____/ \__/ \__/ \_____
^ warmup
-
Warmup(预热阶段):一开始,学习率从0线性上升到设定的初始学习率。
这个阶段持续num_warmup_steps步,用于缓解一开始模型不稳定的问题。 -
Cosine Decay(余弦退火)
Warmup后,学习率会按余弦函数逐渐减小。表现为训练初期下降较快,后期下降缓慢,模拟“退火”过程。 -
Hard Restarts(硬重启)
在整个训练过程中,会定期“重启”学习率,即重新回到最高点开始新的余弦衰减。重启的次数由num_cycles参数控制,每个周期内部都会经历完整的余弦衰减。
3.经验值
下面是一些已有模型/优化器组合的经验值,作为初始值跑几轮试试看。
| 优化器 | 模型类型 | 推荐初始学习率 | 说明 |
|---|---|---|---|
| SGD | CNN | 0.01 ~ 0.1 | 需要动量,适合简单任务 |
| Adam | 通用(如CNN) | 0.0001 ~ 0.001 | 默认值为0.001 |
| AdamW | Transformer | 1e-5 ~ 1e-4 | 微调大模型常用 |
| Adam | LSTM/GRU | 0.001 ~ 0.01 | RNN较敏感 |
学习率还要配合batch Size使用,大批量数据的梯度估计更稳定,可以配大一点的学习率;而小批量容易噪声大、跳动大,步子太大反而不稳,所以学习率要小一点更稳。
推荐做法:
- 先用默认学习率跑几个epoch,看损失是否平稳下降
- 如果收敛慢但曲线平稳,则尝试提高学习率
- 如果训练震荡或发散,则及时减小学习率
3 Batch Size
批大小是指每次参数更新时所使用的训练样本数。在训练神经网络时,我们把训练数据划分成一个个小批(mini-batch),每个批包含一定数量的样本,用这个批的数据计算梯度并更新模型参数,然后再取下一个批,如此循环。简单来说,批大小决定了模型在一次权重更新中看多少样本。例如,batch size=32表示每处理32个样本才做一次梯度下降更新。
批大小对训练的影响
1. 计算效率与资源消耗
- 大batch:在支持并行计算的硬件(如GPU)上能显著提高吞吐量。由于每个batch包含更多样本,每个epoch所需的迭代次数减少,从而整体训练速度提升。
- 小batch:计算量小,内存占用低,更适合资源受限的环境。
- 硬件限制是首要约束:过大的batch会耗尽显存或造成内存交换瓶颈,反而拖慢训练。
2. 收敛稳定性与泛化性能
- 小batch会引入更多梯度噪声,因为每次更新依赖的样本少。虽然训练过程会出现波动甚至震荡,但这种扰动有时有助于跳出局部极小值,找到平坦最小值。
- 平坦极小值:模型在一大片区域内都表现得不错,对测试集更鲁棒,泛化能力强。
- 大batch提供更稳定、更接近真实梯度的更新路径,损失下降更平滑,通常可以更快收敛。然而,这种稳定性可能让模型过早陷入某个尖锐但次优的极小值,从而影响泛化效果。
- 尖锐极小值:模型只在非常特定的参数值附近表现好,一旦稍有扰动,性能就下降,泛化能力差。
研究表明,小batch训练更有可能找到平坦的最优解(即对输入微扰不敏感),这有助于提升模型的泛化能力。大 batch虽然能更快降低训练误差,但泛化性能往往略逊一筹,即训练误差低,但测试误差不一定好。这被称为 大批量训练的泛化差距。
3.极端设置的风险
- 过小:训练过程高度随机,损失曲线嘈杂,收敛慢,需要更多epoch平滑噪声。对于深层或复杂模型可能导致优化失败。
- 过大:每个epoch只进行一次更新,方向虽最精确,但更新频率太低,整体收敛速度反而下降;同时显存压力大,效率下降。
小批量 vs 大批量
| 维度 | 小批量(如16~32) | 大批量(如256~1024) |
|---|---|---|
| 梯度估计 | 噪声大,更新方向抖动 | 更稳定,接近真实梯度 |
| 显存占用 | 低,适配资源受限设备 | 高,需大显存 |
| 训练效率 | 每个epoch更新次数多,较慢 | 更新频率低,但每次处理数据多 |
| 收敛路径 | 波动大,利于探索 | 平滑,可能陷入尖锐极小值 |
| 泛化能力 | 更强,类似隐式正则 | 稍弱,需额外正则或训练技巧弥补 (比如更大的权重衰减、使用Dropout等) |
许多大型模型在使用上千的批大小训练时,往往结合了学习率策略和强正则化手段,使得最终模型仍具有良好泛化
设置批大小
| 任务类型 | 常见范围 | 原因 |
|---|---|---|
| 计算机视觉(CV) | 32 ~ 256 | 图像数据体积大,内存占用高,但计算高度并行化,适合中到大型batch,训练速度较快。 |
| 自然语言处理 (NLP) | 8 ~ 64(甚至更小) | 序列长度不确定,Transformer等模型参数众多,易出现显存瓶颈,小batch更安全稳定。 |
| 语音识别 / 音频 | 16 ~ 64 | 输入数据为频谱图或音频序列,占用中等内存,batch设定类似 NLP。 |
| 微调(Fine-tuning) | 8 ~ 32 | 使用预训练模型时,小batch有助于避免扰动过大,保留已有泛化能力。 |
| 从零训练大模型 | 128 ~ 1024+ | 有充足计算资源时,大batch可显著提高吞吐量,缩短训练时间,适合大规模分布式训练。 |
| 小模型 / 小数据集 | 16 ~ 64 | 模型参数少、数据量小,batch设置弹性大,但仍推荐使用小批量增强泛化能力。 |
| 资源受限设备 | ≤ 32 \leq 32 ≤32 | CPU、笔记本、嵌入式设备显存受限,batch size必须小,否则训练/推理会因内存不足失败。 |
- 硬件资源限制:在可用显存范围内尽量使用更大的batch
- 刚开始尝试32或64,若内存充足且训练稳定,则可以翻倍,若训练不稳定(损失震荡),则减小批大小
- 对于更好的泛化性能和稳健性,中等batch size(如32-128)是较常见的选择
4 Weight Decay
Weight Decay是一种常用的正则化技术。如果不给模型设限,它可能会把某些特征的权重学得非常大,完全依赖它们去预测,这样可能在训练集上表现很好,但在新数据上表现很差。加入权重衰减后,模型在训练时会被轻微地惩罚权重过大的行为,从而鼓励它学到更保守和泛化性强的特征。
和L2正则化的区别
| 名称 | 做法 | 特点说明 |
|---|---|---|
| L2 正则化 | 在损失函数里手动加上 w 2 w^2 w2 惩罚 | 是通过梯度来惩罚,可能被某些优化器抵消 |
| 权重衰减 | 每次更新参数时直接减掉 w w w 一点 | 不走梯度,更直接有效,尤其在Adam里 |
如果你用的是像Adam、AdamW这种优化器,推荐使用AdamW,它把权重衰减和梯度更新分开处理,不会冲突。
代码示例:
# 推荐的方式:使用 AdamW
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
# 不推荐:传统 Adam + 手动添加L2正则
optimizer = Adam(model.parameters(), lr=0.001)
l2_lambda = 0.01
l2_norm = sum(p.pow(2.0).sum() for p in model.parameters())
loss = original_loss + l2_lambda * l2_norm
常见设置推荐
| 模型或任务类型 | 建议范围 | 说明 |
|---|---|---|
| 小型CNN | 0.0001 ~ 0.001 | 防止轻度过拟合 |
| ResNet | ≈ 0.0001 | 经典设置,几乎是标准默认值 |
| Transformer/BERT | 0.01 ~ 0.1 | 大模型需要更强约束,防止爆炸式拟合 |
| BERT微调 | ≈ 0.01 | HuggingFace & OpenAI推荐值 |
| 小数据集 | 0.001 ~ 0.01 | 数据太少容易过拟合,需要更强正则 |
| 大数据集 | 0.00001 ~ 0.0001 | 数据够多,模型自然就不容易过拟合 |
调参建议:
- 初次尝试时可设为:
- 小模型:
weight_decay = 1e-4;BERT或Transformer:weight_decay = 1e-2
- 小模型:
- 如果训练集准确率很高,但验证集差距很大(过拟合):尝试加大weight decay
- 如果训练和验证都很低(欠拟合):尝试减小weight decay
不建议对以下参数使用权重衰减:
bias:每层的偏置项,数量少,主要用于调整输出的整体偏移,对模型拟合影响不大。BatchNorm或LayerNorm层的权重:这些是归一化层的缩放与偏移参数(如gamma和beta),用于稳定训练,不是用于学习特征的主力权重。
这些参数本身就很小,功能也偏辅助性质,加入权重衰减可能会影响训练稳定性,因此我们通常排除它们。
5 超参数之间的相互作用
前面介绍的超参数并不是孤立起作用的,它们常常相互影响、相互制约。如果只单独优化某一个超参数,可能导致整体训练效果反而下降。因此,我们需要理解这些超参数之间的关联,才能做出更有效的联合调整。
除了前面介绍的四个核心超参数,实际训练中还常常会调整一些常见辅助参数,如Dropout和动量(Momentum),下面也有讨论。
5.1 批大小 vs 学习率
批大小决定了每次模型更新所使用的样本数量,而学习率则决定了更新幅度,两者关系非常紧密。
主要关系:
-
线性缩放法则:
通常,在一定范围内可以使用下面的经验公式进行同步调整:
新学习率 = 基准学习率 × ( 新 batch size 基准 batch size ) \text{新学习率} = \text{基准学习率} \times \left(\frac{\text{新 batch size}}{\text{基准 batch size}}\right) 新学习率=基准学习率×(基准 batch size新 batch size)例如,如果基准为 l r = 0.001 , b a t c h _ s i z e = 32 lr=0.001, batch\_size=32 lr=0.001,batch_size=32,当批大小增至128 时,可尝试学习率 0.004 0.004 0.004。
-
优化器差异:
- 对于 SGD,这种线性缩放规则通常成立;
- 对于 Adam 这类自适应优化器,更常见的经验是按 批大小 \sqrt{\text{批大小}} 批大小 来调整学习率。
-
泛化差异:
- 大batch带来梯度估计更稳定、训练更快,但可能导致模型陷入尖锐最小值,影响泛化。
- 小batch噪声大但更容易跳出局部最优,通常泛化性能更好,但训练更慢、震荡更强。
实践建议:
- 批大小增大时应考虑同步调高学习率;
- 如果模型发散,检查是否需要将学习率缩回与batch匹配;
- 在资源允许时,大批量配warmup学习率(训练初期小学习率,然后逐渐增大)是常见策略。
5.2 学习率 vs 训练轮次
学习率控制模型学习的速度,而训练轮数控制持续时间,它们之间存在天然的平衡。
主要关系:
- 学习率越大,每步走得快,通常需要的epochs越少;
- 学习率越小,收敛更平稳,但需要更多的epochs才能达到目标误差;
实践建议:
- 先使用学习率范围测试,找出稳定的最大学习率;
- 如果选择较小学习率,需配合更长的训练时间;
- 通常配合学习率调度器(如warmup、Step decay、余弦退火)效果更好
5.3 学习率 vs 权重衰减
权重衰减是一种正则化手段,用于限制模型过度依赖单一特征,它与学习率有较强的耦合关系:
相互影响:
- 学习率高,权重衰减小:否则更新过猛,模型容易陷入震荡或提前收敛;
- 学习率低,权重衰减可以大一点:帮助模型收敛到更平滑的区域,抑制过拟合;
- Adam优化器下,推荐使用
AdamW,将权重衰减从梯度中解耦,更稳定有效。
实践建议:
- 微调模型时,建议将学习率与权重衰减作为一组进行联合搜索;
- 避免在高学习率下配高权重衰减,容易导致训练停滞;
- 大模型(如Transformer)通常使用较大的weight decay(如0.01)与小学习率(如1e-4)。
5.4 学习率 vs 动量
动量能在优化过程中加速下降、抑制震荡,它和学习率之间也需要配合使用:
相互影响:
- 高动量代表更强的更新累积,这在一定程度上放大了学习率的效果;
- 若动量太大(如 > 0.95)且学习率也大,容易出现震荡、跳过最优点;
- 动量常用值为 0.9,通常不需要频繁调整。
实践建议:
- 使用SGD + Momentum时,若加大学习率,动量可以适当减小;
- 若保持动量固定(如0.9),可专注于微调学习率;
- 使用Adam等自适应方法时内部已含有动量,不需额外调节。
5.5 Dropout vs 权重衰减
二者都是控制过拟合的常用方法,适用于不同场景,也可结合使用。
- Dropout更偏向结构性断联:它通过在训练过程中随机断开神经元之间的连接,防止神经网络对某些路径依赖过强,强迫模型在不同的子网络中都能学习有效特征。这种方式更偏向于结构级的正则化,适用于层数多、参数多、容易过拟合的中大型模型(如全连接网络、Transformer等)。
- 权重衰减更细粒度、作用在参数层面:它直接在优化过程中对每个参数的值进行惩罚,以避免模型参数变得过大或过复杂。相比Dropout的结构级限制,它是一种参数级的约束,适用于更普遍的场景,不改变网络结构本身,适合搭配任何模型。
- 两者可以协同增加模型正则化强度,尤其是在数据较小或噪声较多时。
5.6 调参建议
调参时建议按照影响程度和资源依赖的优先级,分步优化:
- 学习率:优先调,收敛速度核心参数;
- 批大小:根据硬件显存能力选择,影响学习率调节;
- 权重衰减:调节模型复杂度,配合学习率调;
- 动量:一般默认0.9或略作微调;
- 训练轮数:配合早停动态调整;
- Dropout:在发生过拟合时开启或增强;
超参数调优速查表
| 超参数 | 建议初始值 | 调优方向 | 备注 |
|---|---|---|---|
| Epochs | 50 | 欠拟合→增加,过拟合→减少 | 配合EarlyStopping效果更好 |
| 学习率 (LR) | 0.001 (Adam) / 0.01 (SGD) | 收敛慢→增大,震荡/发散→减小 | 影响最大,建议优先调 |
| 批大小 | 32 | 显存足够→增大,训练不稳→减小 | 调整后应同步修改学习率(线性缩放) |
| 权重衰减 | 1e-4 | 过拟合→增大,欠拟合→减小 | 推荐用AdamW实现 |
| 动量 | 0.9 | 训练震荡→减小,收敛慢→略增 | 高动量时注意学习率不要太大 |
| Dropout | 0.2~0.5 | 过拟合→增大,欠拟合→减小 | 与weight decay互补作用 |
常见问题
| 问题类型 | 可能原因 | 建议应对 |
|---|---|---|
| 损失为 NaN | 学习率过大、无梯度裁剪、数据异常 | 减小学习率,添加梯度裁剪(如clip_grad_norm_),检查数据 |
| 训练慢、准确率不涨 | 学习率太小、batch 太大 | 增大学习率或减小batch;尝试 warmup + decay |
| 验证集效果差 | 模型过拟合、正则化不够 | 增加 Dropout/weight_decay,或采用早停与数据增强 |
6 总结
尽管我们对各类超参数提供了一些经验建议,但这些经验往往高度依赖具体任务、数据分布、模型结构及计算资源,不能直接照搬套用。在实际应用中,超参数调优仍然是一个试错性很强的过程,缺乏通用解。此外,还有一些未完全展开的重要调节维度(如学习率调度策略组合、正则化体系整体权衡、搜索算法如Bayesian Optimization、自动调参框架等)也值得进一步探索。
换句话说:调参没有万能公式,但理解它们是走向"调得准"的第一步。


















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











