




当你的模型训练时间从几小时缩短到几分钟,内存占用减少一半却保持相同精度,你就能理解为什么LightGBM成为了梯度提升决策树(GBDT)领域的佼佼者。这篇文章就来讨论微软这一开源框架如何通过四大核心创新:GOSS梯度采样、EFB特征绑定、叶级树生长和直方图优化,实现训练速度提升。
文章目录
1 介绍
2016年,微软研究院面临一个棘手问题:Bing搜索引擎需要处理13TB规模的数据进行排序学习,而现有的GBDT框架在百节点集群上运行缓慢。这促使研究团队开发了LightGBM,一个专为大规模数据设计的高性能框架。现在LightGBM已经成为结构化数据机器学习的首选工具,广泛应用于:
- 搜索引擎排序:微软Bing的核心排序算法
- 金融风控:银行信贷评分,准确率达98%以上
- 推荐系统:电商个性化推荐
- 时间序列预测:销量预测、流量预估
- 竞赛利器:Kaggle结构化数据比赛的常胜将军
在梯度提升生态系统中,LightGBM的定位非常明确:
- 相比XGBoost:更快的训练速度,更低的内存占用,原生支持类别特征
- 相比CatBoost:更成熟的生态系统,更广泛的部署经验
- 相比传统GBDT:数量级的性能提升,分布式训练支持
接下来,我们将深入了解LightGBM如何通过技术创新实现这些优势。
2 核心技术创新详解
LightGBM的性能突破来自四个相互协同的算法创新。让我们逐一剖析这些技术的原理和实现。
2.1 GOSS:基于梯度的单边采样
在梯度提升训练中,不同样本的重要性是不同的。梯度大的样本(通常是预测误差大的样本)对模型改进贡献更大,而梯度小的样本(预测准确的样本)贡献较小。
传统GBDT在每次分裂时需要遍历所有样本计算信息增益,这是主要的计算瓶颈。GOSS通过智能采样大幅减少计算量。
算法流程
GOSS的具体步骤如下:
- 计算梯度并排序:对所有样本按梯度绝对值降序排列
- 保留大梯度样本:选择前a×100%的大梯度样本(如top 20%)
- 随机采样小梯度:从剩余样本中随机采样b×100%(如10%)
- 权重补偿:给采样的小梯度样本赋予权重(1-a)/b,保证采样无偏
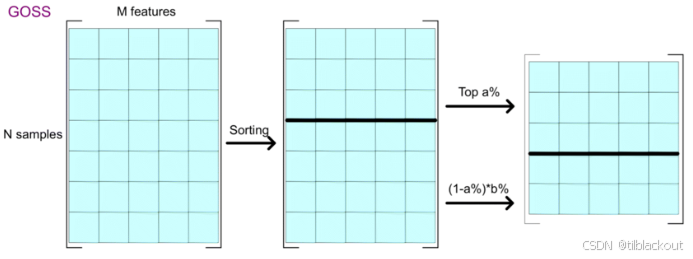
下图展示了GOSS的基本流程:首先按样本的梯度绝对值对整个训练集排序,保留前a%的大梯度样本,再从剩余小梯度样本中随机采样b%。最终组合形成新的训练子集,用于后续构建树结构。通过这种方式,GOSS显著减少了计算量。
数学原理
信息增益的计算公式简化后为:
Gain = ( ∑ g L ) 2 n L + ( ∑ g R ) 2 n R \text{Gain} = \frac{(\sum g_L)^2}{n_L} + \frac{(\sum g_R)^2}{n_R} Gain=nL(∑gL)2+nR(∑gR)2
其中 g L g_L gL和 g R g_R gR分别是左右子节点的梯度和。GOSS通过采样后的加权保证了期望值不变:
E [ Gain ∗ G O S S ] = E [ Gain ∗ o r i g i n a l ] E[\text{Gain}*{GOSS}] = E[\text{Gain}*{original}] E[Gain∗GOSS]=E[Gain∗original]
这样既减少了计算量(只用30%的数据),又保持了统计特性。实验表明,GOSS能在保持精度的同时实现3-5倍的加速。
2.2 EFB:互斥特征绑定
在从GOSS的样本采样优化后,EFB(Exclusive Feature Bundling)用来解决高维稀疏特征的问题。许多真实数据集包含大量稀疏特征,如one-hot编码后的类别特征。这些特征大部分值为0,且很多特征互斥(同一样本中不会同时非零)。
EFB将互斥特征绑定成一个特征,大幅减少特征数量:
- 构建冲突图:统计特征间的冲突次数(同时非零的样本数)
- 贪心分组:将冲突小于阈值的特征分到同一组
- 偏移编码:通过加偏移量的方式合并特征值
EFB能将上千维的稀疏特征压缩到几十维,直接带来:
- 内存减少:特征数量级下降
- 计算加速:直方图构建复杂度从O(样本数×特征数)降到O(样本数×bundle数)
例子:网页点击行为
用户每次点击行为只可能是:
- 商品点击(A):如服装 = 1,数码 = 2,图书 = 3
- 广告点击(B):如金融 = 1,教育 = 2
每次记录中,特征 A A A和 B B B互斥,即最多只有一个非零。
合并规则(bundle)
设 A A A的最大值为 3 3 3,用来为 B B B留出不重叠的编码区间:
- 若 A ≠ 0 A \ne 0 A=0,则 b u n d l e = A bundle = A bundle=A
- 若 B ≠ 0 B \ne 0 B=0,则 b u n d l e = B + max ( A ) = B + 3 bundle = B + \max(A) = B + 3 bundle=B+max(A)=B+3
这样 A A A 和 B B B 合并为一个整型特征 b u n d l e bundle bundle,编码区间互不重叠。
用户 A A A B B B b u n d l e bundle bundle U1 2 0 2 U2 0 1 4 U3 0 2 5 U4 3 0 3 合并后仍能唯一还原 A A A 和 B B B:
- 若 b u n d l e ≤ 3 bundle \le 3 bundle≤3:说明来自 A A A,则 A = b u n d l e , B = 0 A = bundle,\ B = 0 A=bundle, B=0
- 若 b u n d l e > 3 bundle > 3 bundle>3:说明来自 B B B,则 B = b u n d l e − 3 , A = 0 B = bundle - 3,\ A = 0 B=bundle−3, A=0
2.3 Leaf-wise生长策略
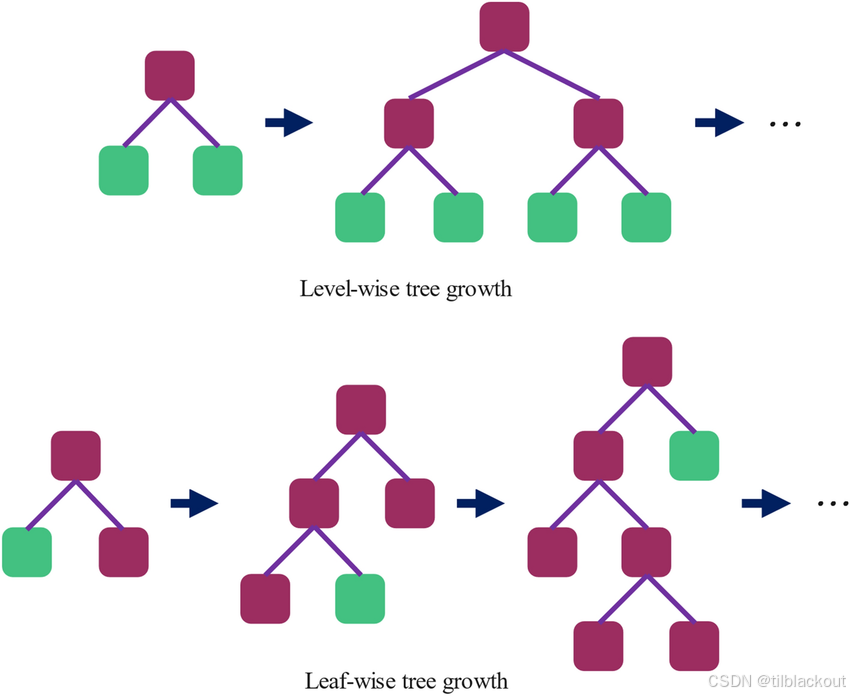
从特征维度的优化转向树结构的优化,Leaf-wise是LightGBM的另一个关键创新。传统GBDT(如XGBoost)采用Level-wise生长:同一层的所有节点同时分裂,这保证了树的平衡性,但可能在不必要的节点上浪费分。而LightGBM采用Leaf-wise生长:
- 每次选择增益最大的叶子分裂
- 可能产生不平衡但更精确的树
- 用更少的节点达到更低的误差
如下图所示,Level-wise每一层节点同时分裂,树结构保持平衡,但不一定每一步都能带来最大收益;而Leaf-wise每次选择当前增益最大的叶子节点分裂,优先优化模型效果,虽然生成的树不平衡,但能更快降低训练误差。
Leaf-wise的核心是维护一个叶子节点的优先队列,按潜在增益排序:
# 伪代码展示Leaf-wise思想
while num_leaves < max_leaves:
# 找到增益最大的叶子
best_leaf = max(current_leaves, key=lambda x: x.split_gain)
# 分裂该叶子
left_child, right_child = split(best_leaf)
# 更新叶子集合
current_leaves.remove(best_leaf)
current_leaves.extend([left_child, right_child])
过拟合控制
Leaf-wise策略容易过拟合,LightGBM提供多个参数控制:
max_depth:限制树的最大深度min_data_in_leaf:叶子最少样本数min_gain_to_split:最小分裂增益
2.4 直方图算法优化
2.4.1 原理
最后一个核心优化是用直方图替代传统的预排序方法。XGBoost等框架使用预排序方法找最优分裂点:
- 需要存储排序后的索引,内存开销为
O(样本数×特征数) - 每次分裂都要重新统计,计算复杂度高
直方图方法将连续特征离散化到固定数量的bins(默认255个):
- 构建直方图:统计每个bin内的梯度和、样本数
- 遍历分裂点:只需遍历bin的边界(255个点而非全部样本)
- 直方图做差:利用父节点直方图减去一个子节点得到另一个子节点
直方图算法带来多重优势:
- 内存节省:只需存储bin值(uint8),内存减少8倍
- 计算加速:分裂点候选从样本数降到bin数
- 缓存友好:连续内存访问模式
2.4.2 例子
我们用年龄这个特征来分裂一棵树的某个节点,目标是找到一个年龄的分界点,把样本分成两组,使模型的预测误差尽可能减小。传统做法是对样本按年龄排序后遍历每个切分点,计算增益。但这样在每个节点都排序太慢。直方图方法可以避免这个问题。
在GBDT中,每棵新树是在拟合上一轮残差的目标下构建的。对于每个样本,它都有一个当前模型预测值 y ^ i \hat{y}_i y^i,真实值是 y i y_i yi,那么我们对损失函数 ℓ ( y i , y ^ i ) \ell(y_i, \hat{y}_i) ℓ(yi,y^i) 计算一阶导数(梯度0): g i = ∂ ℓ ∂ y ^ i g_i = \frac{\partial \ell}{\partial \hat{y}_i} gi=∂y^i∂ℓ,表示当前模型在该样本上的误差方向,每个样本在本轮建树时都带着一个自己的梯度值。
1. 离散年龄特征,构建直方图
假设年龄范围是0到100,我们将其划分成10个桶,其中bin0表示0-10岁,…,bin9表示90-100岁。将每个样本根据其年龄放进对应的bin中,并统计每个bin中:样本数和梯度和(所有样本的 g i g_i gi 求和)
- 也可以统计 Hessian 总和 H H H,但此处简化不展开
2. 尝试切分
假设我们尝试把切分点放在bin4(即年龄 ≤ 50 \le 50 ≤50 在左边, > 50 > 50 >50 在右边),左子节点包含bin0 ~ bin4,右子节点包含bin5 ~ bin9。我们现在要得到左右子节点的统计量 G L G_L GL, G R G_R GR。
直方图已经保存了每个bin的梯度和,左边的梯度和 G L G_L GL通过相加得到,由于整个父节点的梯度和 G G G是所有bin的梯度和总和,那么右边的梯度和就是: G R = G − G L G_R = G - G_L GR=G−GL
3.计算增益
将 G L G_L GL、 G R G_R GR和样本数代入增益公式:
Gain = G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ \text{Gain} = \frac{G_L^2}{H_L + \lambda} + \frac{G_R^2}{H_R + \lambda} - \frac{(G_L + G_R)^2}{H_L + H_R + \lambda} Gain=HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2
遍历所有桶边界,找出增益最大的切分点作为最终的分裂点。
2.5 总结
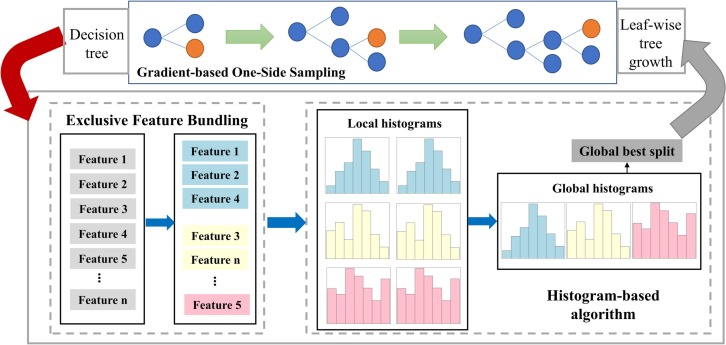
下图展示了LightGBM高性能的实现路径,串联了其四大核心优化技术:
- GOSS:通过优先保留大梯度样本、随机抽取小梯度样本,显著减少计算负担,提升训练效率。
- Exclusive Feature Bundling(EFB):通过分析稀疏特征间的互斥性,将它们压缩绑定成更少的虚拟特征,降低特征维度和内存占用。
- Histogram-based algorithm:每个特征构建直方图,离散化特征值并统计梯度和,从而快速寻找最佳分裂点。
- Leaf-wise Tree Growth:不是按层扩展整棵树,而是始终选择当前最优增益的叶子节点进行分裂,更快降低模型误差。
3 代码
理解了原理后,让我们通过代码实例来掌握LightGBM的使用技巧。
3.1 完整代码示例
我们用泰坦尼克号数据集为例,预测某个乘客是否生存,下面是各个字段及其含义:
| 字段名 | 中文含义 |
|---|---|
| Survival | 是否生存(0 = 否,1 = 是) |
| Pclass | 船票等级(1 = 一等,2 = 二等,3 = 三等) |
| Sex | 性别 |
| Age | 年龄(以年为单位) |
| SibSp | 同行兄弟姐妹或配偶数量 |
| Parch | 同行父母或子女数量 |
| Ticket | 船票号码 |
| Fare | 票价 |
| Cabin | 舱位号 |
| Embarked | 登船港口(C = 瑟堡,Q = 昆士敦,S = 南安普顿) |
1. 加载并查看数据
我们首先加载原始数据,目的是了解数据的基本结构和字段类型,以便后续处理。
import lightgbm as lgb
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 加载数据
df = pd.read_csv('train.csv')
# 查看数据结构
print("数据集形状:", df.shape)
print("\n数据集前5行:")
print(df.head())
print("\n特征类型:")
print(df.dtypes)
输出:
数据集形状: (891, 12)
数据集前5行:
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
特征类型:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
2. 数据预处理
机器学习模型不能直接处理缺失值和文本数据。我们需要:
1.填补缺失值(例如Age、Fare、Embarked):
- 年龄和票价填充中位数,因为它们是连续变量且可能有极端值。
- 登船港口用众数填充,表示最常见的港口。
2.类别特征编码成整数:LightGBM支持原生类别特征(但要求是int类型)。
3.选择特征
- 类别特征:Sex、Pclass、Embarked(都是非数值但重要的变量)
- 数值特征:Age、Fare、SibSp、Parch(与生存概率密切相关)
# 填补缺失值
df['Age'].fillna(df['Age'].median(), inplace=True)
df['Embarked'].fillna(df['Embarked'].mode()[0], inplace=True)
df['Fare'].fillna(df['Fare'].median(), inplace=True)
# 特征选择
categorical_features = ['Sex', 'Pclass', 'Embarked']
numerical_features = ['Age', 'Fare', 'SibSp', 'Parch']
target = 'Survived'
# 类别特征编码(LightGBM原生支持类别特征,但需要为整数)
for col in categorical_features:
df[col] = pd.Categorical(df[col]).codes
# 构建特征与标签
X = df[categorical_features + numerical_features]
y = df[target]
# 划分训练集和验证集(stratify确保标签分布一致)
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
3. 构造LightGBM数据格式
LightGBM需要通过其特有的Dataset数据格式来进行训练。指定categorical_feature参数可自动启用类别特征的优化处理。
# 构建LightGBM训练/验证数据
train_data = lgb.Dataset(
X_train,
label=y_train,
categorical_feature=categorical_features
)
valid_data = lgb.Dataset(
X_val,
label=y_val,
reference=train_data,
categorical_feature=categorical_features
)
4. 模型训练
# 设置训练参数并开始训练模型
params = {
'objective': 'binary', # 二分类任务
'metric': 'binary_logloss', # 使用对数损失评估模型,值越小越好
'boosting_type': 'gbdt', # 使用梯度提升树(Gradient Boosting Decision Tree)
'num_leaves': 31, # 控制树的复杂度,叶子节点越多模型越复杂
'learning_rate': 0.05, # 学习率控制每步更新幅度,较小值学习更稳定
'feature_fraction': 0.9, # 每棵树随机选用90%的特征,降低过拟合风险
'bagging_fraction': 0.8, # 每轮迭代使用80%的样本进行训练
'bagging_freq': 5, # 每5轮进行一次bagging采样
'verbose': -1 # 禁用训练过程的详细输出
}
print("\n开始训练...")
model = lgb.train(
params,
train_data,
valid_sets=[valid_data], # 用于评估的验证集
num_boost_round=200, # 最多训练200轮
callbacks=[
lgb.early_stopping(20), # 如果20轮内验证集效果无提升,则提前停止
lgb.log_evaluation(25) # 每25轮输出一次日志信息
]
)
5. 验证集评估
我们使用LightGBM训练完的模型在验证集上进行预测并评估:
- 预测概率>0.5判为生存(1),否则为遇难(0)
- 使用
accuracy_score和classification_report进行分类评估,后者提供了精确率、召回率和F1分数
# 验证集预测
val_predictions = model.predict(X_val, num_iteration=model.best_iteration)
val_predictions_binary = (val_predictions > 0.5).astype(int)
# 输出评估结果
print("\n验证集性能:")
print(f"准确率: {accuracy_score(y_val, val_predictions_binary):.3f}")
print("\n分类报告:")
print(classification_report(y_val, val_predictions_binary,
target_names=['遇难', '生存']))
输出:
验证集性能:
准确率: 0.804
分类报告:
precision recall f1-score support
遇难 0.80 0.90 0.85 110
生存 0.80 0.65 0.72 69
accuracy 0.80 179
macro avg 0.80 0.78 0.78 179
weighted avg 0.80 0.80 0.80 179
从验证集结果来看,模型准确率为80.4%,整体性能较为稳健。遇难者的召回率为0.90,说明模型能较好地识别出实际遇难的乘客;但对生还者的召回率只有0.65,存在一定的误判倾向,模型在预测生还者时偏保守,后续可通过调整分类阈值或优化特征进一步提升平衡性。
6. 特征重要性分析
LightGBM支持自动提取特征重要性,这是一大优势。即使我们是做预测,模型在训练过程中也会记录每个特征在分裂中带来的信息增益。我们通过model.feature_importance()提取这种Gain类型的重要性:
- Gain表示该特征在所有树中对模型性能的贡献总和
- 可用于理解模型依赖于哪些变量进行预测
# 提取特征重要性
importance = model.feature_importance(importance_type='gain')
feature_names = categorical_features + numerical_features
feature_imp = pd.DataFrame({
'feature': feature_names,
'importance': importance
}).sort_values('importance', ascending=False)
print("\n特征重要性排序:")
print(feature_imp)
输出:
特征重要性排序:
feature importance
0 Sex 1706.534011
4 Fare 977.778962
3 Age 886.457785
1 Pclass 724.556066
2 Embarked 163.553084
5 SibSp 97.664115
6 Parch 66.460923
3.2 参数调优
LightGBM参数众多,下表按重要性排序,帮助你快速定位需要调整的参数:
| 参数名 | 作用说明 | 建议取值范围 | 调参建议 |
|---|---|---|---|
| 第一优先级 | |||
num_leaves | 控制树的复杂度 | 15-255 | 通常设为2^(max_depth)-1,过大易过拟合 |
learning_rate | 学习率/步长 | 0.01-0.3 | 配合n_estimators调整,小学习率+多树效果好 |
n_estimators | 树的数量 | 100-1000 | 使用early_stopping自动确定 |
| 第二优先级 | |||
max_depth | 树的最大深度 | 3-10 | 限制树深度,防止过拟合 |
min_data_in_leaf | 叶子最少样本数 | 20-100 | 增大可防止过拟合,减小可提高精度 |
feature_fraction | 特征采样比例 | 0.6-1.0 | 小于1可加速训练并防止过拟合 |
bagging_fraction | 数据采样比例 | 0.6-1.0 | 配合bagging_freq使用,增加随机性 |
| 第三优先级 | |||
lambda_l1 | L1正则化 | 0-10 | 产生稀疏解,特征选择效果 |
lambda_l2 | L2正则化 | 0-10 | 平滑解,防止过拟合 |
min_gain_to_split | 最小分裂增益 | 0-1 | 限制分裂条件,防止过度生长 |
max_bin | 直方图桶数 | 63-255 | 影响精度和速度平衡 |
防止过拟合的关键要点:
LightGBM由于采用Leaf-wise生长策略,相比XGBoost更容易过拟合。主要通过以下方法控制:
- 限制树的复杂度,减小
num_leaves或设置max_depth - 增加
min_data_in_leaf,确保叶子节点有足够样本 - 使用子采样,设置
feature_fraction和bagging_fraction小于1 - 加入正则化项
lambda_l1和lambda_l2 - 最重要的是使用early_stopping,让模型在验证集性能不再提升时自动停止。
大数据集优化要点
当数据量超过百万级别时,可以通过以下策略加速:
- 减小
max_bin到63或127以节省内存和计算,使用num_threads=-1充分利用多核,设置bin_construct_sample_cnt限制构建直方图的采样数 - 对于特征多的数据使用
force_col_wise=True,数据多时使用force_row_wise=True - 考虑使用GPU版本,但注意GPU对稀疏数据支持不佳
4. 性能对比与使用建议
了解了LightGBM的使用方法后,我们来看看它在实际场景中的表现。基于多个公开基准测试,这里整理了LightGBM和XGBoost的对比数据:
| 指标 | LightGBM | XGBoost | 数据来源 |
|---|---|---|---|
| 训练速度 | |||
| Higgs数据集(1000万样本) | 238秒 | 1265秒 | LightGBM论文 |
| Bosch数据集(100万样本) | 38秒 | 531秒 | Laurae基准测试 |
| 内存使用 | |||
| 数据加载 | 原始数据1.02倍 | 原始数据0.69倍 | Bosch测试 |
| 训练峰值 | 基准值 | 基准值1.18倍 | Bosch测试 |
| 精度对比 | |||
| 二分类AUC | 0.7548 | 0.7513 | 平均值 |
| 回归RMSE | 相当 | 相当 | 多数据集 |
在使用GBDT框架时,二者各有适用场景:
| 场景/特点 | LightGBM | XGBoost |
|---|---|---|
| 数据规模 | 大于10万样本 | 小于5万样本 |
| 特征维度 | 高维(数百到数千) | 中低维 |
| 类别特征支持 | 原生支持,处理效率和效果更好 | 需手动编码 |
| 实验迭代速度 | 更快,内存占用小 | 相对较慢 |
| 分布式训练 | 支持良好 | 也支持,配置稍复杂 |
| GPU 支持 | 适合数值密集、大batch数据 | 在稀疏场景中更稳定 |
常见问题与解决方案
1. 小数据集容易过拟合:适用于LightGBM和XGBoost
- 减小
num_leaves(例如15-31),增大min_data_in_leaf(例如50-100) - 使用更强的正则项,如
lambda_l1,lambda_l2
2. 类别特征基数过高:特征如用户ID、商品ID等,唯一值过多
- 超过1000类别的特征建议使用目标编码
- 设置
max_cat_threshold限制分裂时考虑的类别数,或提前做聚类、映射等特征工程降维
3. GPU训练不一定加速:表现取决于数据结构
- 数据传输开销大,或稀疏特征结构不适合GPU并行处理
- GPU更适合数值密集、连续特征 + 大batch场景,训练前先用CPU跑小样本做基准评估
LightGBM更适合大数据、高维特征、快速实验需求;XGBoost在小数据或已有使用基础时仍有优势。但无论用哪种框架,常见问题(过拟合、高基数、GPU不加速)都应结合实际数据结构和调参技巧进行优化。
5 总结
LightGBM以其高效、灵活、强大的性能,已成为结构化数据建模的首选工具。凭借一系列技术创新和不断演进的功能,它不仅提升了模型效果,也极大优化了开发效率。掌握它不仅能提升模型性能,更能大幅提高工作效率。
参考资源:


















 4547
4547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











