



原始CLIP
数据主要来自以下两部分:
- 互联网公开资源 :CLIP的核心数据来源于互联网上公开的文本-图像对,包括社交媒体(如Flickr)、网页的alt-text描述、维基百科配图等。这些数据天然具备图文关联性,例如图片的标题、注释或上下文描述 。
- WIT数据集 :OpenAI专门构建了包含4亿对(图像,文本)的WebImageText(WIT)数据集,覆盖了视觉概念的多样性和长尾分布,其规模与NLP领域预训练语料库(如GPT-2的WebText)相当。
EvaCLIP
由智源团队提出,专注于图像-文本多模态模型的规模化扩展。其核心目标是通过改进CLIP的训练效率和模型架构,实现更大参数量的高性能视觉-语言对齐模型。例如,EvaCLIP-18B模型参数量达到180亿,通过弱到强知识蒸馏(从较小模型逐步训练更大模型)实现性能提升。
技术亮点:
- 使用EVA视觉模型预训练初始化,加速收敛;
- 引入优化器,支持大批量训练;
- 随机掩码50%图像标记以降低计算成本;
- 在零任务中达到80.7%的准确率(27个基准测试)。
XCLIP
由微软提出,聚焦于视频理解任务,目标是将图像-文本预训练模型(如CLIP)高效迁移到视频领域,无需额外视频-文本预训练数据。其核心创新在于时序建模与语义提示的结合。
技术亮点:
- 设计跨帧通信Transformer(CCT)和多帧集成模块(MIT),捕捉时序信息;
- 利用视频标签的语义信息生成自适应提示(Prompt),提升分类精度;
- 在Kinetics-400/600数据集上分别达到87.7%和88.3%的准确率,计算量仅为同类模型的1/10。
MetaCLIP
来自于 DEMYSTIFYING CLIP DATA 这篇论文
- 原始的CLIP主要有两个问题:1) 大量噪声;2) 样本不均衡,MetaCLIP针对这两个问题做了优化
- 从WordNet(同义词库,目前有227,000个同义词集)和wikipedia数据集中构建query库(在原文中也叫entry库),再通过字符串匹配将收集到的Image-Text对分配到各个query下,最终得到500,000 queries,每个query大概得到 20,000 (image, text) pairs
Alpha CLIP
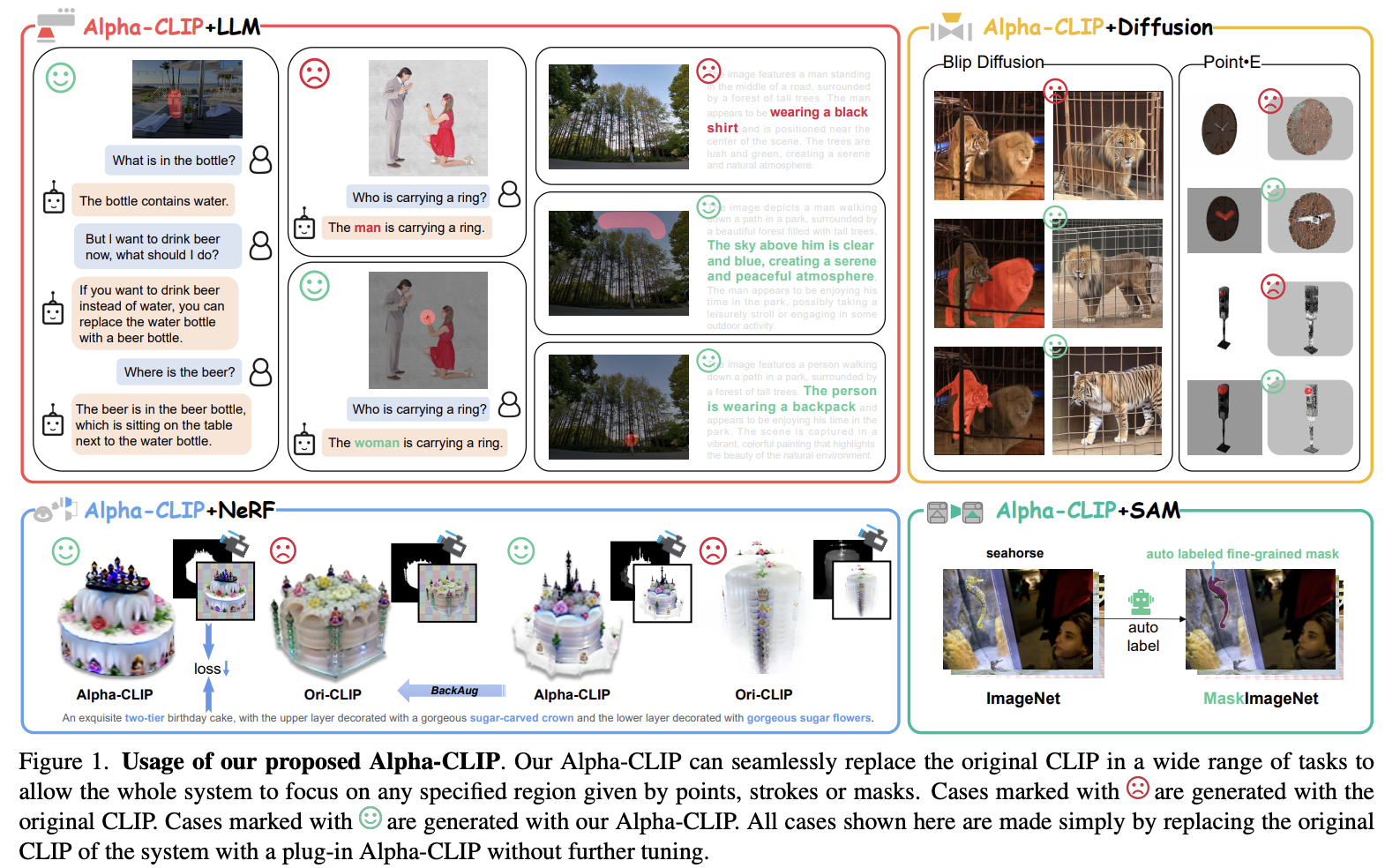
Alpha-CLIP 是2023年底由上海人工智能实验室联合多所高校提出的CLIP模型改进版本,其核心目标是通过引入可控制区域感知能力,使视觉基座模型能够聚焦于用户指定的图像区域,同时保留CLIP原有的多模态理解和泛化能力:
一、技术原理
-
输入扩展:Alpha通道引入
Alpha-CLIP在CLIP原有的RGB三通道输入基础上,新增了一个Alpha通道(第四通道),用于指定图像中需要关注的区域(0表示背景,1表示前景)。这一通道通过掩码(mask)、框(box)或交互标记(如点、笔触)生成,为模型提供空间注意力引导。 -
模型架构改进
- 在CLIP的图像编码器(如ViT)中,新增并行卷积层处理Alpha通道输入,初始权重设为0,确保训练初期模型行为与原始CLIP一致。
- 使用大规模RGBA图像-文本对(千万级)进行微调,通过对比学习优化,使匹配的图像区域与文本在共享语义空间中对齐。

















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









