



ChatGLM2-6B相对于ChatGLM1-6B(GLM)的重要改进点
- 使用了Flash Attention将Context Length由ChatGLM的2k扩展到了32k
- 使用Multi-Query Attention大幅提高了模型的推理速度
- 使用了混合目标函数,该目标函数在ChatGLM中已经提出来了,但当时效果不好。ChatGLM2加入了Document-level Masking和Sentece-level Masking
- 仓库中提供了友好的P-tuning代码,fine-tuning模型非常方便
这部分转载自 https://www.zhihu.com/question/608732789/answer/3141379386
Vicuna相比LLaMA1的改进点
Vicuna是LLama经过Instruction Fine Tune的版本。
Instruction Fine Tune和Prompt Engineer的区别
IFT involves actually training the model by changing its weights. The LLM’s weights are not changed in prompt Engineer
部分转载自 https://community.deeplearning.ai/t/confusion-between-instruction-fine-tuning-vs-prompt-engineering/491824
LLama1相比GPT2的改进
- 首次引入RMSNorm层(去均值计算的LayerNorm变体)替代传统LayerNorm,提升计算效率,RMSNorm使用PreNorm更多
- 采用SwiGLU激活函数替代ReLU,增强非线性表达能力
- RoPE旋转位置编码突破传统绝对位置编码限制,支持长序列建模
LLama2相比LLama1的改进
- 模型结构基本和llama一样,transformer decoder结构,RMSNorm 应用预归一化、使用 SwiGLU 激活函数和旋转位置嵌入RoPE。
- 上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
- 7B和13B 使用与 LLaMA 相同的架构,34B和70B模型采用分组查询注意力(GQA)。For speed up decoding! 自回归解码的标准做法(past key-value 机制)是缓存序列中先前标记的k,v矩阵,从而加快注意力计算速度。但上下文长度、批量大小、模型大小较大时,多头注意力(MHA)中的kv缓存无疑巨大。所以采用分组查询注意力机制(GQA)可以提高大模型的推理可扩展性。它的工作原理是将键和值投影在多个头之间共享,而不会大幅降低性能。可以使用具有单个KV投影的原始多查询格式(MQA)或具有8KV投影的分组查询注意力变体(GQA)
Llama3相比LLama2的改进
- 全面采用GQA机制(覆盖8B/70B所有版本),推理速度提升30%
- 128K超大规模词汇表(LLama1/2为32K),压缩率提升15%,支持30+语言
- 引入动态掩码技术,确保8K上下文窗口的跨文档处理安全性
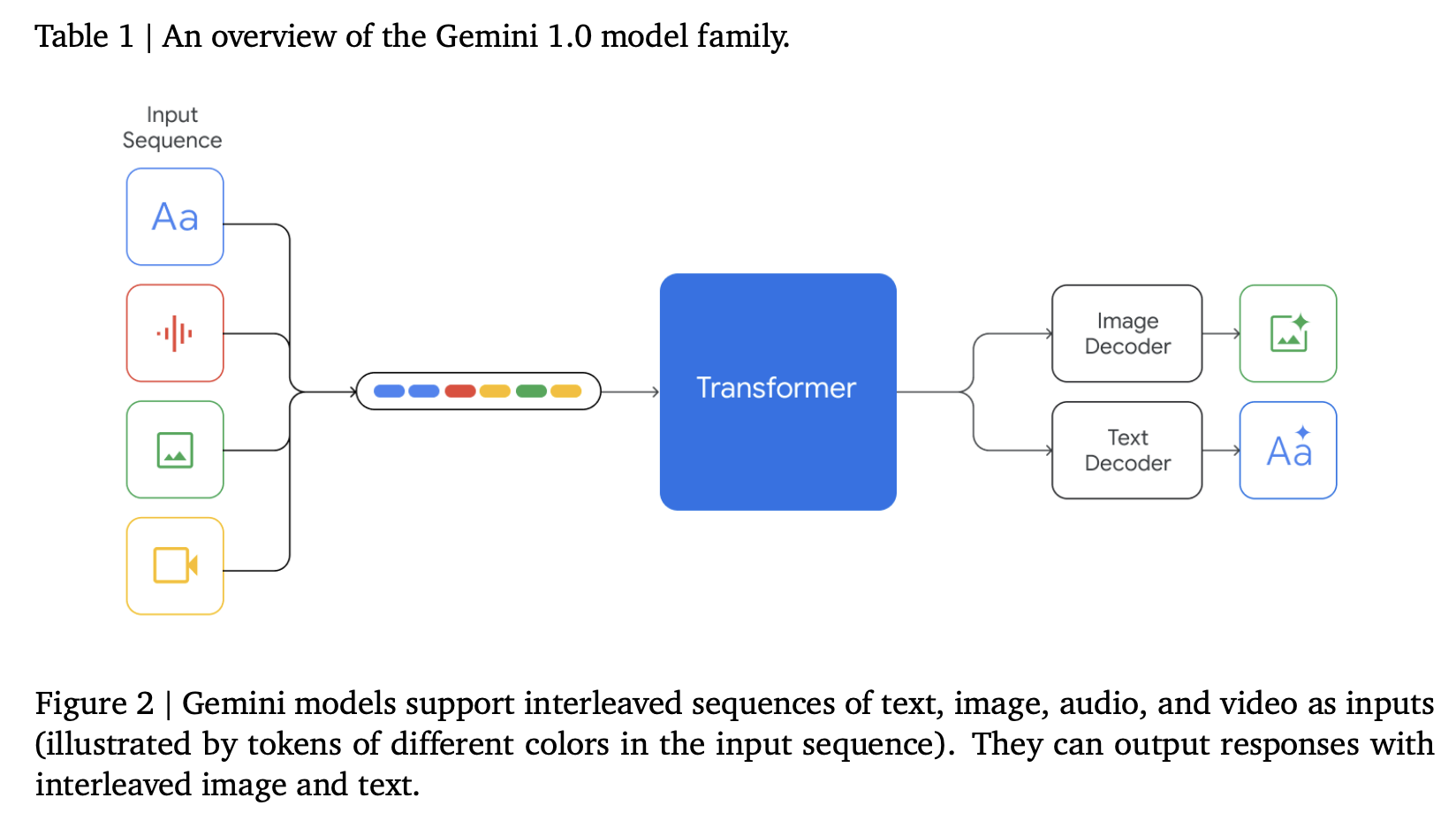
Gemini
实际上就是把text、audio、vision全部tokenizer,再过transformer的思路,以下来自于Gemini: A Family of Highly Capable Multimodal Models,
Qwen2.5的改进
- RoPE面临“外推问题”,Qwen2.5使用ABF(Adjustable Base Frequency)技术调整RoPE中的基频(base frequency),即旋转角度的底数,来增强模型在长上下文中的表现。具体来说,将基频从10000增加到500000,可以缩小RoPE对远端token信息的衰减效应。
- 另外,Qwen2.5使用两个关键策略:YARN和DCA(Dual Chunk Attention)解决长序列在推理时遇到的困难。在处理长上下文问题时,YARN(Yet Another RoPE eXtension)和DCA(Dynamic Context Adjustment)是两种重要的技术,它们各自采用不同的方法来提高大型语言模型(LLM)在长文本处理中的性能。
- YARN采用“按部分”插值策略,在嵌入空间的不同维度上进行操作,并引入温度因子来调整长输入的注意力分布。这种方法使得模型在处理长文本时能够保持较高的性能。DCA(Dynamic Context Adjustment)是一种动态调整上下文的方法,旨在进一步优化模型在处理长文本时的表现。DCA结合了自回归技术和位置信息,通过动态生成上下文表示来增强模型对长文本的理解能力。这使得模型在面对复杂任务时能够保持较高的性能。

















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









