






 DSSM(Deep Structured Semantic Model)是一种基于深度网络的语义模型,通过将query和doc映射到共同的语义空间,最大化它们之间的余弦相似度,解决搜索引擎检索、广告相关性等问题。它克服了LSA、LDA等方法的字典爆炸问题,使用wordhashing技术降低向量空间,并通过有监督学习优化语义embedding。
DSSM(Deep Structured Semantic Model)是一种基于深度网络的语义模型,通过将query和doc映射到共同的语义空间,最大化它们之间的余弦相似度,解决搜索引擎检索、广告相关性等问题。它克服了LSA、LDA等方法的字典爆炸问题,使用wordhashing技术降低向量空间,并通过有监督学习优化语义embedding。
论文的地址:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/cikm2013_DSSM_fullversion.pdf
1.背景
DSSM是Deep Structured Semantic Model的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。DSSM有很广泛的应用,比如:搜索引擎检索,广告相关性,问答系统,机器翻译等。
2.DSSM
2.1简介
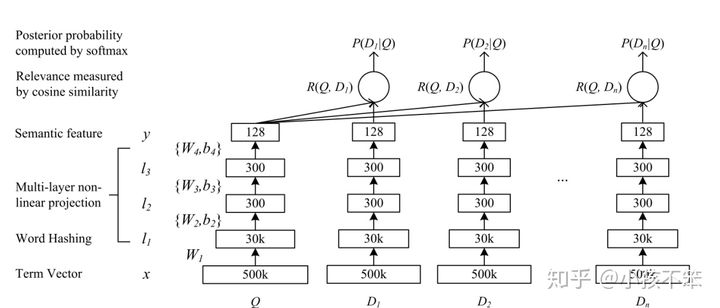
典型的DNN结构是将原始的文本特征映射为在语义空间上表示的特征。DNN在搜索引擎排序中主要是有下面2个作用:
- 将query中term的高维向量映射为低维语义向量
- 根据语义向量计算query与doc之间的相关性分数

2.2 word hashing

2.3 DSSM的学习
点击日志里通常包含了用户搜索的query和用户点击的doc,可以假定如果用户在当前query下对doc进行了点击,则该query与doc是相关的。通过该规则,可以通过点击日志构造训练集与测试集。

3.总结
DSSM的提出主要有下面的优点:
- 解决了LSA、LDA、Autoencoder等方法存在的一个最大的问题:字典爆炸(导致计算复杂度非常高),因为在英文单词中,词的数量可能是没有限制的,但是字母 n-gram的数量通常是有限的
- 基于词的特征表示比较难处理新词,字母的 n-gram可以有效表示,鲁棒性较强
- 使用有监督方法,优化语义embedding的映射问题
- 省去了人工的特征工程
缺点:
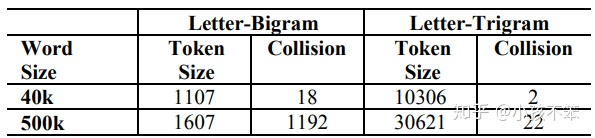
- word hashing可能造成冲突
- DSSM采用了词袋模型,损失了上下文信息
- 在排序中,搜索引擎的排序由多种因素决定,由于用户点击时doc的排名越靠前,点击的概率就越大,如果仅仅用点击来判断是否为正负样本,噪声比较大,难以收敛
对于中文而言,处理方式与英文有很多不一样的地方。中文往往需要进行分词,但是我们可以仿照英文的处理方式,将中文的最小粒度看作是单字(在某些文献里看到过用偏旁部首,笔画,拼音等方法)。因此,通过这种word hashing方式,可以将向量空间大大降低。
对DSSM的优化出现了很多的变种,有CNN-DSSM,LSTM-DSSM,MV-DSSM等。大多对隐藏层做了一些修改,原论文如下:
CNN-DSSM:http://www.iro.umontreal.ca/~lisa/pointeurs/ir0895-he-2.pdf
LSTM-DSSM:https://arxiv.org/pdf/1412.6629.pdf
MV-DSSM:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/frp1159-songA.pdf
水平有限,本文如有错误的地方,请私信或者留言指出,谢谢。

















 3216
3216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









