




 ESIM模型结合BiLSTM和注意力机制,用于文本匹配任务,分析两个句子间的关系。通过编码、局部推理、推理组合及预测阶段,实现高效文本推理。使用预训练词向量,通过BiLSTM提取特征,利用注意力机制分析句子间联系,计算新旧序列差异,再经BiLSTM全局分析,最终多层感知器分类。
ESIM模型结合BiLSTM和注意力机制,用于文本匹配任务,分析两个句子间的关系。通过编码、局部推理、推理组合及预测阶段,实现高效文本推理。使用预训练词向量,通过BiLSTM提取特征,利用注意力机制分析句子间联系,计算新旧序列差异,再经BiLSTM全局分析,最终多层感知器分类。
ESIM是一个综合应用了BiLSTM和注意力机制的模型,在文本匹配中效果十分强大.
文本匹配说就是分析两个句子是否具有某种关系,比如有一个问题,现在给出一个答案,我们就需要分析这个答案是否匹配这个问题,所以也可以看成是一个二分类问题(输出是或者不是)。现在主要基于SNIL和MutilNLI这两个语料库,它们包含两个句子premise和hypothesis以及一个label,label就是判断这两个句子的关系,本文主要讲解的就是如何利用ESIM分析这个问题。
1. 简介
ESIM模型主要是用来做文本推理的,给定一个前提premise p p p 推导出假设hypothesis p p p,其损失函数的目标是判断 p p p与 h h h是否有关联,即是否可以由 p p p推导出 h h h,因此,该模型也可以做文本匹配,只是损失函数的目标是两个序列是否是同义句。
2. 模型结构
ESIM的论文中,作者提出了两种结构,如下图所示,左边是自然语言理解模型ESIM,右边是基于语法树结构的HIM,本文也主要讲解ESIM的结构,大家如果对HIM感兴趣的话可以阅读原论文。
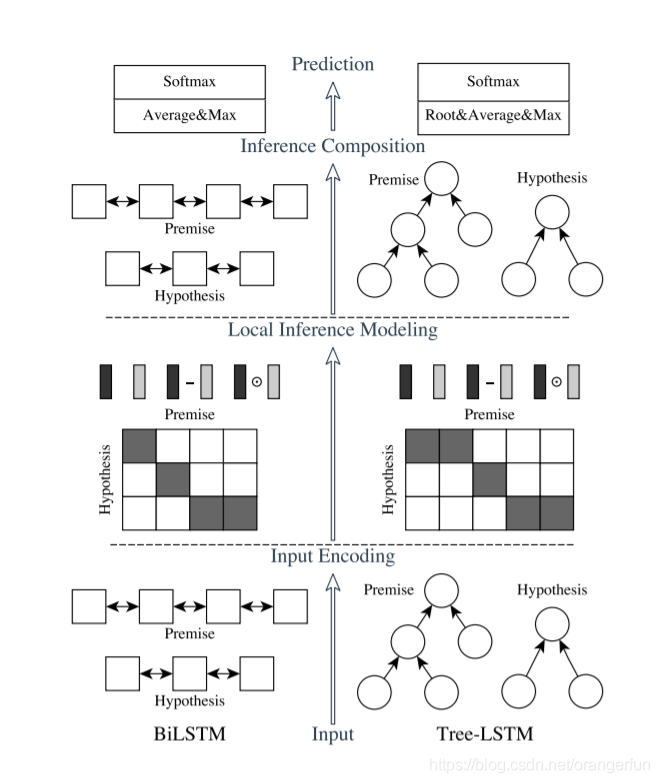
ESIM一共包含四部分,Input Encoding、Local Inference Modeling、 Inference Composition、Prediction
2.1 Input Encoding
这一层结构的输入内容,一般可以采用预训练好的词向量或者添加embedding层。接下来就是一个双向的LSTM,起作用主要在于对输入值做encoding,也可以理解为在做特征提取,最后把其隐藏状态的值保留下来,分别记为
a
ˉ
i
\bar{a}_i
aˉi和
b
ˉ
i
\bar{b}_i
bˉi,其中i与j分别表示的是不同的时刻,a与b表示的是上文提到的p与h。
a
ˉ
i
=
BiLSTM
(
a
,
i
)
b
ˉ
i
=
BiLSTM
(
b
,
i
)
\begin{array}{l} \bar{a}_{i}=\operatorname{BiLSTM}(a, i) \\ \bar{b}_{i}=\operatorname{BiLSTM}(b, i) \end{array}
aˉi=BiLSTM(a,i)bˉi=BiLSTM(b,i)
2.2 Local Inference Modeling
接下来就是需要分析这两个句子之间的联系了,具体怎么分析,首先要注意的是,我们现在得到的句子和单词的表示向量,是基于当前语境以及单词之间的意思综合分析得到的,那么如果两个单词之间联系越大,就意味着他们之间的距离和夹角就越少,比如(1,0)和(0,1)之间的联系就没有(0.5,0.5)和(0.5,0.5)之间的联系大。在理解了这一点之后,我们再来看看ESIM是怎么分析的。
首先,两个句子的词向量之间相乘
e
i
j
=
a
ˉ
i
T
b
ˉ
J
e_{i j}=\bar{a}_{i}^{T} \bar{b}_{J}
eij=aˉiTbˉJ
正如之前所说的,如果两个词向量联系较大,那么乘积也会较大,然后进行softmax运算求出其权重:
a
~
i
=
∑
j
=
1
l
b
exp
(
e
i
j
)
∑
k
=
1
l
b
exp
(
e
i
k
)
b
ˉ
j
b
~
j
=
∑
i
=
1
l
a
exp
(
e
i
j
)
∑
k
=
1
l
a
exp
(
e
k
j
)
a
ˉ
i
\begin{array}{l} \tilde{a}_{i}=\sum_{j=1}^{l_{b}} \frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{l_{b}} \exp \left(e_{i k}\right)} \bar{b}_{j} \\\\ \widetilde{b}_{j}=\sum_{i=1}^{l_{a}} \frac{\exp \left(e_{i j}\right)}{\sum_{k=1}^{l_{a}} \exp \left(e_{k j}\right)} \bar{a}_{i} \end{array}
a~i=∑j=1lb∑k=1lbexp(eik)exp(eij)bˉjb
j=∑i=1la∑k=1laexp(ekj)exp(eij)aˉi
上述几条公式的目的,简单来说可以这样理解,比如premise中有一个单词"good",首先我分析这个词和另一句话中各个词之间的联系,计算得到的结果 e i j e_{ij} eij标准化后作为权重,用另一句话中的各个词向量按照权重去表示"good",这样一个个分析对比,得到新的序列。
以上操作就是一个attention机制, a ~ i \tilde{a}_{i} a~i 和 b ~ j \tilde{b}_{j} b~j 的前面分式部分就是 attention weight。这里要注意,计算 a ~ i \tilde{a}_{i} a~i 其计算方法是与 b ˉ j \bar{b}_{j} bˉj 做加权和。而不是 a ˉ j \bar{a}_{j} aˉj,对于 b ~ j \tilde{b}_{j} b~j 同理。
接下来就是分析差异,从而判断两个句子之间的联系是否足够大了,ESIM主要是计算新旧序列之间的差和积,并把所有信息合并起来储存在一个序列中:
m
a
=
[
a
ˉ
;
a
~
;
a
ˉ
−
a
~
;
a
ˉ
⊙
a
~
]
m
b
=
[
b
ˉ
;
b
~
;
b
ˉ
−
b
~
;
b
ˉ
⊙
b
~
]
\begin{array}{l} m_{a}=[\bar{a} ; \tilde{a} ; \bar{a}-\tilde{a} ; \bar{a} \odot \tilde{a}] \\\\ m_{b}=[\bar{b} ; \tilde{b} ; \bar{b}-\tilde{b} ; \bar{b} \odot \tilde{b}] \end{array}
ma=[aˉ;a~;aˉ−a~;aˉ⊙a~]mb=[bˉ;b~;bˉ−b~;bˉ⊙b~]
2.3 Inference Composition
上面之所以要把所有信息储存在一个序列中,因为ESIM最后还需要综合所有信息,做一个全局的分析,这个过程依然是通过BiLSTM处理这两个序列:
v
a
,
t
=
BiLSTM
(
F
(
m
a
,
t
)
,
t
)
v
b
,
t
=
BiLSTM
(
F
(
m
b
,
t
)
,
t
)
\begin{array}{l} v_{a, t}=\operatorname{BiLSTM}\left(F\left(m_{a, t}\right), t\right) \\\\ v_{b, t}=\operatorname{BiLSTM}\left(F\left(m_{b, t}\right), t\right) \end{array}
va,t=BiLSTM(F(ma,t),t)vb,t=BiLSTM(F(mb,t),t)
值得注意的是,F是一个单层神经网络(ReLU作为激活函数),主要用来减少模型的参数避免过拟合,另外,上面的t表示BiLSTM在t时刻的输出。
因为对于不同的句子,得到的向量v长度是不同的,为了方便最后一步的分析,这里把BiLSTM得到的值进行了池化处理,把结果储存在一个固定长度的向量中。值得注意的是,因为考虑到求和运算对于序列长度是敏感的,因而降低了模型的鲁棒性,所以ESIM选择同时对两个序列进行average pooling和max pooling,再把结果放进一个向量中:
V
a
,
a
v
e
=
∑
i
=
1
l
a
V
a
,
i
l
a
,
V
a
,
max
=
max
i
=
1
l
a
V
a
,
i
V
b
,
a
v
e
=
∑
j
=
1
l
b
V
b
,
j
l
b
,
V
b
,
max
=
max
j
=
1
l
b
V
b
,
j
V
=
[
V
a
,
a
v
e
;
V
a
,
max
;
V
b
,
a
v
e
;
V
b
,
max
]
\begin{aligned} V_{a, a v e} &=\sum_{i=1}^{l_{a}} \frac{V_{a}, i}{l_{a}}, \quad V_{a, \max }=\max _{i=1}^{l_{a}} V_{a, i} \\ V_{b, a v e} &=\sum_{j=1}^{l_{b}} \frac{V_{b}, j}{l_{b}}, \quad V_{b, \max }=\max _{j=1}^{l_{b}} V_{b, j} \\ V &=\left[V_{a, a v e} ; V_{a, \max } ; V_{b, a v e} ; V_{b, \max }\right] \end{aligned}
Va,aveVb,aveV=i=1∑lalaVa,i,Va,max=i=1maxlaVa,i=j=1∑lblbVb,j,Vb,max=j=1maxlbVb,j=[Va,ave;Va,max;Vb,ave;Vb,max]
2.4 prediction
终于来到最后一步了,那就是把向量v扔到一个多层感知器分类器,在输出层使用softmax函数。
总结
ESIM首先是将输入句子进行word embedding 或者直接使用预训练好的词向量送入到BiLSTM网络中,将LSTM网络的输出进行Attention计算(将p句子中的每个单词向量用h中所有单词向量加权和表示,同理将h句子中的每个单词向量用p句子中所有单词向量加权和表示),然后计算差异性。将两个差异性矩阵再次送入到BiLSTM网络中,将LSTM网络输出做均值池化和最大池化(两者连接起来),最后将池化输出送入到多层感知机分类器中,使用softmax分类。
ESIM使用的损失函数就是来判断输入的两个句子是否语义相匹配,匹配为1, 不匹配为0;因此使用交叉熵损失函数。


















 9872
9872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









