




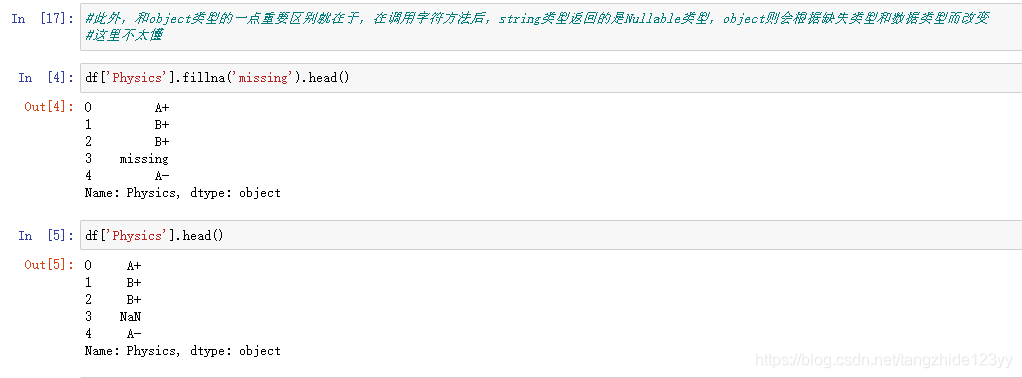
 这篇博客探讨了Pandas中缺失数据的处理,包括如何删除缺失值超过25%的列,Nullable类型的含义及其引入原因,以及面对有缺失值的数据时的分析策略。同时,提供了练习题和相关代码,帮助读者深化对Pandas处理缺失数据的理解。
这篇博客探讨了Pandas中缺失数据的处理,包括如何删除缺失值超过25%的列,Nullable类型的含义及其引入原因,以及面对有缺失值的数据时的分析策略。同时,提供了练习题和相关代码,帮助读者深化对Pandas处理缺失数据的理解。
学习资源链接:pandas缺失数据
一、总览

二、疑问
1.NaT是对时序版本的缺失值
2.
3.

三、思考题
【问题一】 如何删除缺失值占比超过25%的列?
这个倒是不知道
【问题二】 什么是Nullable类型?请谈谈为什么要引入这个设计?
这是Pandas在1.0新版本中引入的重大改变,其目的就是为了(在若干版本后)解决之前出现的混乱局面,统一缺失值处理方法
【问题三】 对于一份有缺失值的数据,可以采取哪些策略或方法深化对它的了解?
四、练习题
【练习一】现有一份虚拟数据集,列类型分别为string/浮点/整型,请解决如下问题:¶
(a)请以列类型读入数据,并选出C为缺失值的行。
(b)现需要将A中的部分单元转为缺失值,单元格中的最小转换概率为25%,且概率大小与所在行B列单元的值成正比。
【练习二】 现有一份缺失的数据集,记录了36个人来自的地区、身高、体重、年龄和工资,请解决如下问题:
(a)统计各列缺失的比例并选出在后三列中至少有两个非缺失值的行。
(b)请结合身高列和地区列中的数据,对体重进行合理插值。
五、程序代码以及相关注释
学习部分
import pandas as pd
import numpy as np
df = pd.read_csv('F:/program study/python/joyful-pandas-master/data/table_missing.csv')
df.head(10)
#复习一下读入操作
pd.Series([1,np.nan,3],dtype='bool')
s = pd.Series([True,False],dtype='bool')
s[1]=np.nan
s
#在所有的表格读取后,无论列是存放什么类型的数据,默认的缺失值全为np.nan类型
#因此整型列转为浮点;而字符由于无法转化为浮点,因此只能归并为object类型('O'),原来是浮点型的则类型不变
#None在传入数值类型后,会自动变为np.nan 只有当传入object类型是保持不动,几乎可以 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









