






导出onnx模型
import torch
import numpy as np
import pointnet2_utils
class CustomModel(torch.nn.Module):
def __init__(self):
super(CustomModel, self).__init__()
def forward(self, xyz, npoint):
return pointnet2_utils.furthest_point_sample(xyz, npoint)
model = CustomModel().cuda()
xyz = torch.randn(1, 20000, 3).cuda()
np.savetxt("xyz.txt", xyz.reshape(20000, 3).detach().cpu().numpy())
npoint = 2048
torch.onnx.export(model, (xyz, npoint), "furthest_point_sample.onnx", opset_version=13)
其中pointnet2_utils来自https://github.com/erikwijmans/Pointnet2_PyTorch。
导出onnx模型结构如下:
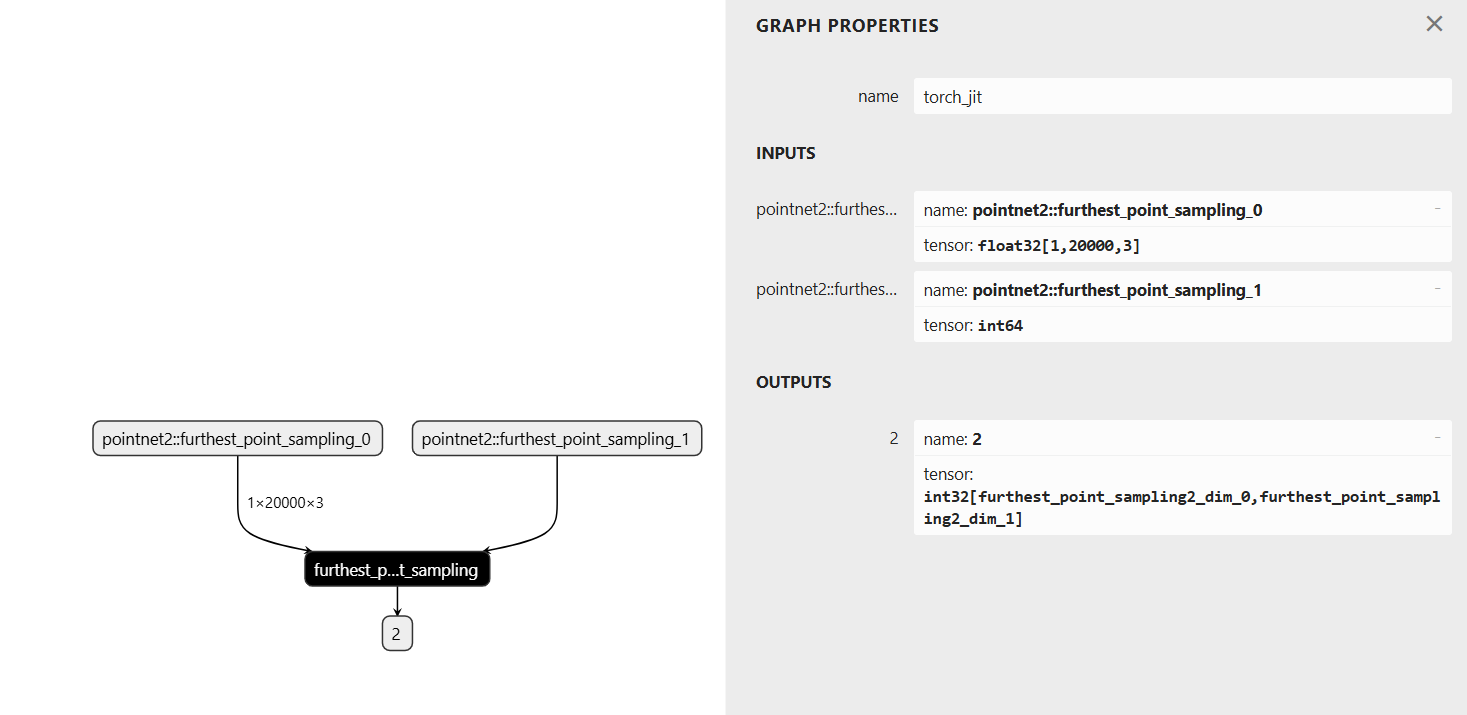
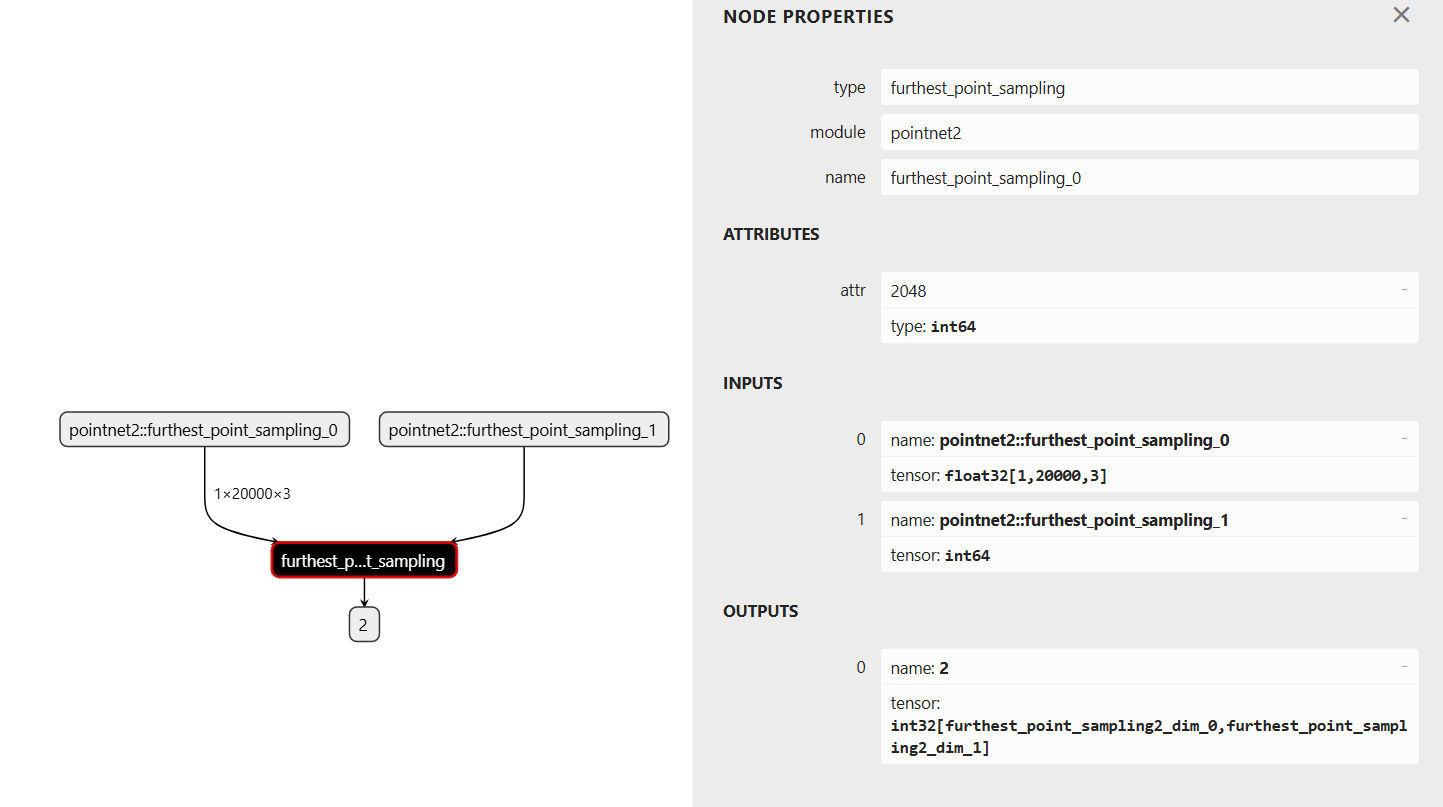
编写tensorrt插件
采用TensorRT-10.6.0.26。由于TensorRT是部分开源,首先在https://developer.nvidia.com/tensorrt/download/10x下载TensorRT-10.6.0.26的库,然后在https://github.com/NVIDIA/TensorRT/tree/v10.6.0下载源代码。
在TensorRT/plugin下新建furthestPointSampling文件夹,添加下面文件:
furthestPointSampling.h
#ifndef TRT_FURTHEST_POINT_SAMPLING_PLUGIN_H
#define TRT_FURTHEST_POINT_SAMPLING_PLUGIN_H
#include "NvInfer.h"
#include "NvInferPlugin.h"
#include "common/plugin.h"
#include "common/cuda_utils.h"
#include <vector>
#include <cstring>
namespace nvinfer1
{
namespace plugin
{
void furthest_point_sampling_kernel_wrapper(int b, int n, int m, const float *dataset, float *temp, int *idxs, cudaStream_t stream);
class FurthestPointSampling : public nvinfer1::IPluginV2DynamicExt
{
public:
FurthestPointSampling(int sample);
FurthestPointSampling(void const* data, size_t length);
~FurthestPointSampling() override;
// 插件基本信息
char const* getPluginType() const noexcept override;
char const* getPluginVersion() const noexcept override;
int getNbOutputs() const noexcept override;
// 输出维度计算
nvinfer1::DimsExprs getOutputDimensions(int outputIndex,
const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder) noexcept override;
// 初始化与销毁
int initialize() noexcept override;
void terminate() noexcept override;
// 执行相关
int enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept override;
size_t getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs,
int nbInputs, const nvinfer1::PluginTensorDesc* outputs,
int nbOutputs) const noexcept override;
// 数据类型与格式支持
DataType getOutputDataType(int index, DataType const* inputTypes, int nbInputs) const noexcept override;
bool supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs,int nbOutputs) noexcept override;
// 配置插件
void configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) noexcept override;
// 序列化
size_t getSerializationSize() const noexcept override;
void serialize(void* buffer) const noexcept override;
// 其他接口
nvinfer1::IPluginV2DynamicExt* clone() const noexcept override;
void destroy() noexcept override;
void setPluginNamespace(char const* libNamespace) noexcept override;
char const* getPluginNamespace() const noexcept override;
private:
int mSample;
std::string mPluginNamespace;
Dims mInputDims;
Dims mSampleDims;
};
class FurthestPointSamplingCreator : public nvinfer1::IPluginCreator
{
public:
FurthestPointSamplingCreator();
~FurthestPointSamplingCreator() override = default;
char const* getPluginName() const noexcept override;
char const* getPluginVersion() const noexcept override;
PluginFieldCollection const* getFieldNames() noexcept override;
IPluginV2* createPlugin(char const* name, PluginFieldCollection const* fc) noexcept override;
IPluginV2* deserializePlugin(char const* name, void const* serialData, size_t serialLength) noexcept override;
void setPluginNamespace(nvinfer1::AsciiChar const* pluginNamespace) noexcept override;
const char* getPluginNamespace() const noexcept override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
};
} // namespace plugin
} // namespace nvinfer1
#endif // TRT_FURTHEST_POINT_SAMPLING_PLUGIN_H
furthestPointSampling.cpp
#include "furthestPointSampling.h"
#include "common/dimsHelpers.h"
using namespace nvinfer1;
using namespace nvinfer1::pluginInternal;
using nvinfer1::plugin::FurthestPointSampling;
using nvinfer1::plugin::FurthestPointSamplingCreator;
// 插件实现
FurthestPointSampling::FurthestPointSampling(int sample) : mSample(sample)
{
//std::cout<<"FurthestPointSampling"<<std::endl;
}
FurthestPointSampling::FurthestPointSampling(void const* data, size_t length)
{
mSample = *static_cast<int const*>(data);
}
FurthestPointSampling::~FurthestPointSampling() {}
// 插件基本信息
char const* FurthestPointSampling::getPluginType() const noexcept
{
//std::cout<<"getPluginType"<<std::endl;
return "furthest_point_sampling";
}
char const* FurthestPointSampling::getPluginVersion() const noexcept
{
//std::cout<<"getPluginVersion"<<std::endl;
return "1";
}
int FurthestPointSampling::getNbOutputs() const noexcept
{
//std::cout<<"getNbOutputs"<<std::endl;
return 1;
}
nvinfer1::DimsExprs FurthestPointSampling::getOutputDimensions(int outputIndex,
const nvinfer1::DimsExprs* inputs, int nbInputs, nvinfer1::IExprBuilder& exprBuilder) noexcept
{
//std::cout << "getOutputDimensions" << std::endl;
// 验证输出索引和输入数量
PLUGIN_ASSERT(outputIndex == 0 && nbInputs == 2);
// 构建输出维度: (B, M)
nvinfer1::DimsExprs outputDims;
outputDims.nbDims = 2;
// 第一个维度为批次大小 B (与输入保持一致)
outputDims.d[0] = exprBuilder.constant(static_cast<int>(inputs[0].d[0]->getConstantValue()));
outputDims.d[1] = exprBuilder.constant(mSample);
return outputDims;
}
// 初始化
int FurthestPointSampling::initialize() noexcept
{
return STATUS_SUCCESS;
}
// 销毁资源
void FurthestPointSampling::terminate() noexcept {}
// 执行核函数
int FurthestPointSampling::enqueue(const nvinfer1::PluginTensorDesc* inputDesc, const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs, void* const* outputs, void* workspace, cudaStream_t stream) noexcept
{
//std::cout << "enqueue" << std::endl;
try
{
// 校验输入维度数量(点云输入应为3维: [B, N, 3])
PLUGIN_ASSERT(inputDesc[0].dims.nbDims == 3);
// 校验输入数据类型(点云应为float类型)
PLUGIN_ASSERT(inputDesc[0].type == nvinfer1::DataType::kFLOAT);
// 校验采样点数输入类型(应为int64类型)
PLUGIN_ASSERT(inputDesc[1].type == nvinfer1::DataType::kINT32);
// 从输入描述符获取批次大小B和点数量N
int B = inputDesc[0].dims.d[0]; // 批次大小
int N = inputDesc[0].dims.d[1]; // 每个批次的点数量
// 校验点坐标维度是否为3(x, y, z)
PLUGIN_ASSERT(inputDesc[0].dims.d[2] == 3);
// 计算所需的内存大小N * B * sizeof(float)用于存储距离
if (workspace == nullptr)
return -1;
cudaError_t err = cudaMemset(workspace, 1e10, B * N * sizeof(float));
if (err != cudaSuccess)
return -1;
// 输入点云数据(B, N, 3),输出索引(B, M)
const float* points = static_cast<const float*>(inputs[0]);;
int* idxs = static_cast<int*>(outputs[0]);
float* temp = static_cast<float*>(workspace); // 临时距离缓存
// const int* inputs1 = static_cast<const int*>(inputs[1]);
// int* h_inputs1 = new int;
// cudaMemcpy(h_inputs1, inputs1, sizeof(int), cudaMemcpyDeviceToHost);
// mSample = h_inputs1[0];
// 调用CUDA核函数执行最远点采样
furthest_point_sampling_kernel_wrapper(B, N, mSample, points, temp, idxs, stream);
return STATUS_SUCCESS;
}
catch (std::exception const& e)
{
caughtError(e);
}
return -1;
}
// 工作空间大小
size_t FurthestPointSampling::getWorkspaceSize(const nvinfer1::PluginTensorDesc* inputs,
int nbInputs, const nvinfer1::PluginTensorDesc* outputs,
int nbOutputs) const noexcept
{
try
{
// 验证输入数量和点云输入维度
PLUGIN_ASSERT(nbInputs == 2);
PLUGIN_ASSERT(inputs[0].dims.nbDims == 3); // 点云输入格式为 (B, N, 3)
// 提取批次大小B和点数量N
int B = inputs[0].dims.d[0]; // 批次大小
int N = inputs[0].dims.d[1]; // 每个批次的点数量
// 工作空间用于存储每个点到已选点集的最小距离,每个批次需要N个float类型的缓存
// 总大小 = 批次大小 * 每个批次的点数量 * float类型字节数
return static_cast<size_t>(B * N * sizeof(float));
}
catch (std::exception const& e)
{
caughtError(e);
}
return 0;
}
// 输出数据类型:索引为INT32
DataType FurthestPointSampling::getOutputDataType(int index, DataType const* inputTypes, int nbInputs) const noexcept
{
//std::cout<<"getOutputDataType"<<std::endl;
PLUGIN_ASSERT(index == 0 && nbInputs == 2);
return DataType::kINT32;
}
// 支持的格式:输入float32,输出int32,均为线性格式
bool FurthestPointSampling::supportsFormatCombination(int pos, const nvinfer1::PluginTensorDesc* inOut, int nbInputs, int nbOutputs) noexcept
{
//std::cout << "supportsFormatCombination" << std::endl;
// 插件有2个输入和1个输出
PLUGIN_ASSERT(pos < nbInputs + nbOutputs);
if (pos == 0)
{
return (inOut[pos].type == nvinfer1::DataType::kFLOAT)
&& (inOut[pos].format == nvinfer1::PluginFormat::kLINEAR);
}
else if (pos == 1)
{
return (inOut[pos].type == nvinfer1::DataType::kINT32)
&& (inOut[pos].format == nvinfer1::PluginFormat::kLINEAR);
}
else if (pos == 2)
{
return (inOut[pos].type == nvinfer1::DataType::kINT32)
&& (inOut[pos].format == nvinfer1::PluginFormat::kLINEAR);
}
return false;
}
void FurthestPointSampling::configurePlugin(const nvinfer1::DynamicPluginTensorDesc* in, int nbInputs,
const nvinfer1::DynamicPluginTensorDesc* out, int nbOutputs) noexcept
{
//std::cout<<"configurePlugin"<<std::endl;
try
{
PLUGIN_ASSERT(nbInputs == 2 && nbOutputs == 1); // 确认2个输入和1个输出
}
catch (std::exception const& e)
{
caughtError(e);
}
}
// 序列化:仅需保存采样点数
size_t FurthestPointSampling::getSerializationSize() const noexcept
{
//std::cout<<"getSerializationSize"<<std::endl;
return sizeof(int);
}
void FurthestPointSampling::serialize(void* buffer) const noexcept
{
//std::cout<<"serialize"<<std::endl;
//memcpy(buffer, &mNumSamples, sizeof(int));
*static_cast<int*>(buffer) = mSample;
}
// 克隆插件
nvinfer1::IPluginV2DynamicExt* FurthestPointSampling::clone() const noexcept
{
//std::cout<<"clone"<<std::endl;
try
{
return new FurthestPointSampling(mSample);
}
catch (std::exception const& e)
{
caughtError(e);
}
return nullptr;
}
void FurthestPointSampling::destroy() noexcept
{
delete this;
}
// 命名空间管理
void FurthestPointSampling::setPluginNamespace(char const* pluginNamespace) noexcept
{
//std::cout<<"setPluginNamespace"<<std::endl;
try
{
mPluginNamespace = pluginNamespace;
}
catch (std::exception const& e)
{
caughtError(e);
}
}
char const* FurthestPointSampling::getPluginNamespace() const noexcept
{
//std::cout<<"getPluginNamespace"<<std::endl;
return mPluginNamespace.c_str();
}
// 插件创建器实现
PluginFieldCollection FurthestPointSamplingCreator::mFC{};
std::vector<PluginField> FurthestPointSamplingCreator::mPluginAttributes;
FurthestPointSamplingCreator::FurthestPointSamplingCreator()
{
//std::cout<<"FurthestPointSamplingCreator"<<std::endl;
mPluginAttributes.clear();
mPluginAttributes.emplace_back(nvinfer1::PluginField("attr", nullptr, nvinfer1::PluginFieldType::kINT32));
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
char const* FurthestPointSamplingCreator::getPluginName() const noexcept
{
//std::cout<<"getPluginName"<<std::endl;
return "furthest_point_sampling";
}
char const* FurthestPointSamplingCreator::getPluginVersion() const noexcept
{
//std::cout<<"getPluginVersion"<<std::endl;
return "1";
}
PluginFieldCollection const* FurthestPointSamplingCreator::getFieldNames() noexcept
{
//std::cout<<"getFieldNames"<<std::endl;
return &mFC;
}
IPluginV2* FurthestPointSamplingCreator::createPlugin(char const* name, PluginFieldCollection const* fc) noexcept
{
//std::cout<<"createPlugin"<<std::endl;
try
{
int sample = 0; // 默认值
// 遍历字段集合,查找名为 "num_samples" 的参
for (int i = 0; i < fc->nbFields; ++i) {
const PluginField& field = fc->fields[i];
if (strcmp(field.name, "attr") == 0) {
// 验证参数类型和维度(确保是 int32 标量)
if (field.type == PluginFieldType::kINT32) {
sample = *static_cast<const int*>(field.data);
}
}
}
// std::cout<<"numSamples: "<<numSamples<<std::endl;
return new FurthestPointSampling(sample);
}
catch (std::exception const& e)
{
caughtError(e);
}
return nullptr;
}
IPluginV2* FurthestPointSamplingCreator::deserializePlugin(char const* name, void const* serialData, size_t serialLength) noexcept
{
//std::cout<<"deserializePlugin"<<std::endl;
try
{
// This object will be deleted when the network is destroyed, which will
// call Concat::destroy()
IPluginV2Ext* plugin = new FurthestPointSampling(serialData, serialLength);
plugin->setPluginNamespace(mNamespace.c_str());
return plugin;
}
catch (std::exception const& e)
{
caughtError(e);
}
return nullptr;
}
void FurthestPointSamplingCreator::setPluginNamespace(char const* libNamespace) noexcept
{
//std::cout<<"setPluginNamespace"<<std::endl;
mNamespace = libNamespace;
}
char const* FurthestPointSamplingCreator::getPluginNamespace() const noexcept
{
//std::cout<<"getPluginNamespace"<<std::endl;
return mNamespace.c_str();
}
furthestPointSampling.cu
#include <stdio.h>
#include <stdlib.h>
#include "NvInfer.h"
#include "furthestPointSampling.h"
#include <cuda_runtime.h>
namespace nvinfer1
{
namespace plugin
{
__device__ void __update(float *__restrict__ dists, int *__restrict__ dists_i,
int idx1, int idx2) {
const float v1 = dists[idx1], v2 = dists[idx2];
const int i1 = dists_i[idx1], i2 = dists_i[idx2];
dists[idx1] = max(v1, v2);
dists_i[idx1] = v2 > v1 ? i2 : i1;
}
// Input dataset: (b, n, 3), tmp: (b, n)
// Ouput idxs (b, m)
template <unsigned int block_size>
__global__ void furthest_point_sampling_kernel(
int b, int n, int m, const float *__restrict__ dataset,
float *__restrict__ temp, int *__restrict__ idxs) {
if (m <= 0) return;
__shared__ float dists[block_size];
__shared__ int dists_i[block_size];
int batch_index = blockIdx.x;
dataset += batch_index * n * 3;
temp += batch_index * n;
idxs += batch_index * m;
int tid = threadIdx.x;
const int stride = block_size;
int old = 0;
if (threadIdx.x == 0) idxs[0] = old;
__syncthreads();
for (int j = 1; j < m; j++) {
int besti = 0;
float best = -1;
float x1 = dataset[old * 3 + 0];
float y1 = dataset[old * 3 + 1];
float z1 = dataset[old * 3 + 2];
for (int k = tid; k < n; k += stride) {
float x2, y2, z2;
x2 = dataset[k * 3 + 0];
y2 = dataset[k * 3 + 1];
z2 = dataset[k * 3 + 2];
float mag = (x2 * x2) + (y2 * y2) + (z2 * z2);
if (mag <= 1e-3) continue;
float d =
(x2 - x1) * (x2 - x1) + (y2 - y1) * (y2 - y1) + (z2 - z1) * (z2 - z1);
float d2 = min(d, temp[k]);
temp[k] = d2;
besti = d2 > best ? k : besti;
best = d2 > best ? d2 : best;
}
dists[tid] = best;
dists_i[tid] = besti;
__syncthreads();
if (block_size >= 512) {
if (tid < 256) {
__update(dists, dists_i, tid, tid + 256);
}
__syncthreads();
}
if (block_size >= 256) {
if (tid < 128) {
__update(dists, dists_i, tid, tid + 128);
}
__syncthreads();
}
if (block_size >= 128) {
if (tid < 64) {
__update(dists, dists_i, tid, tid + 64);
}
__syncthreads();
}
if (block_size >= 64) {
if (tid < 32) {
__update(dists, dists_i, tid, tid + 32);
}
__syncthreads();
}
if (block_size >= 32) {
if (tid < 16) {
__update(dists, dists_i, tid, tid + 16);
}
__syncthreads();
}
if (block_size >= 16) {
if (tid < 8) {
__update(dists, dists_i, tid, tid + 8);
}
__syncthreads();
}
if (block_size >= 8) {
if (tid < 4) {
__update(dists, dists_i, tid, tid + 4);
}
__syncthreads();
}
if (block_size >= 4) {
if (tid < 2) {
__update(dists, dists_i, tid, tid + 2);
}
__syncthreads();
}
if (block_size >= 2) {
if (tid < 1) {
__update(dists, dists_i, tid, tid + 1);
}
__syncthreads();
}
old = dists_i[0];
if (tid == 0) idxs[j] = old;
}
}
void furthest_point_sampling_kernel_wrapper(int b, int n, int m,
const float *dataset, float *temp,
int *idxs, cudaStream_t stream) {
unsigned int n_threads = opt_n_threads(n);
switch (n_threads) {
case 512:
furthest_point_sampling_kernel<512>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 256:
furthest_point_sampling_kernel<256>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 128:
furthest_point_sampling_kernel<128>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 64:
furthest_point_sampling_kernel<64>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 32:
furthest_point_sampling_kernel<32>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 16:
furthest_point_sampling_kernel<16>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 8:
furthest_point_sampling_kernel<8>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 4:
furthest_point_sampling_kernel<4>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 2:
furthest_point_sampling_kernel<2>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
case 1:
furthest_point_sampling_kernel<1>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
break;
default:
furthest_point_sampling_kernel<512>
<<<b, n_threads, 0, stream>>>(b, n, m, dataset, temp, idxs);
}
CUDA_CHECK_ERRORS();
}
}
}
CMakeLists.txt
file(GLOB SRCS *.cpp)
set(PLUGIN_SOURCES ${PLUGIN_SOURCES} ${SRCS})
set(PLUGIN_SOURCES ${PLUGIN_SOURCES} PARENT_SCOPE)
file(GLOB CU_SRCS *.cu)
set(PLUGIN_CU_SOURCES ${PLUGIN_CU_SOURCES} ${CU_SRCS})
set(PLUGIN_CU_SOURCES ${PLUGIN_CU_SOURCES} PARENT_SCOPE)
在TensorRT/plugin/inferPlugin.cpp的开头添加
#include "furthestPointSampling/furthestPointSampling.h"
并在initLibNvInferPlugins函数中添加
initializePlugin<nvinfer1::plugin::FurthestPointSamplingCreator>(logger, libNamespace);
在TensorRT/plugin/CMakeLists.txt的set(PLUGIN_LISTS添加
furthestPointSampling
在TensorRT/CMakeLists.txt中设置TRT_LIB_DIR、TRT_OUT_DIR,再重新编译tensorrt。
tensorrt推理测试
运行下面的命令把onnx 转为engine模型:
TensorRT-10.6.0.26/bin/trtexec --onnx=furthest_point_sample.onnx --saveEngine=furthest_point_sample.engine
编写python推理脚本:
import numpy as np
import tensorrt as trt
import common
logger = trt.Logger(trt.Logger.WARNING)
trt.init_libnvinfer_plugins(logger, "")
with open("furthest_point_sample.engine", "rb") as f, trt.Runtime(logger) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
xyz = np.loadtxt("xyz.txt")
xyz = xyz.reshape(1, 20000, 3).astype(np.float32)
npoint = 2048
np.copyto(inputs[0].host, xyz.ravel())
np.copyto(inputs[1].host, npoint)
output = common.do_inference(context,engine=engine, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
print(output)



















 1090
1090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











