




题目
题目描述
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
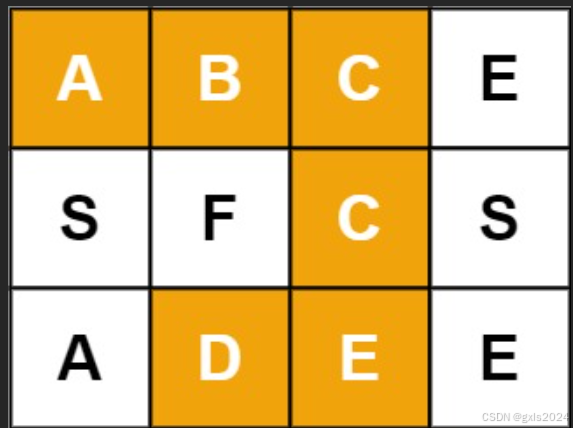
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCCED”
输出:true
示例 2:
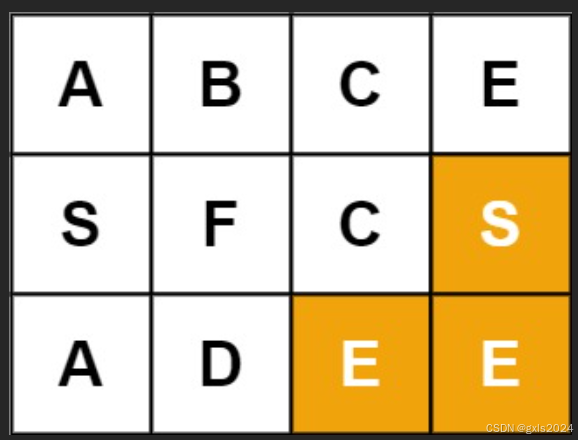
输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “SEE”
输出:true
示例 3:

输入:board = [[“A”,“B”,“C”,“E”],[“S”,“F”,“C”,“S”],[“A”,“D”,“E”,“E”]], word = “ABCB”
输出:false
提示:
m == board.length
n = board[i].length
1 <= m, n <= 6
1 <= word.length <= 15
board 和 word 仅由大小写英文字母组成
进阶:你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
题解
这个问题可以通过深度优先搜索(DFS)来解决。对于每个起始点,我们尝试沿着四个方向(上、下、左、右)进行递归搜索,检查是否可以找到匹配的单词路径。为了避免重复使用同一个单元格,我们需要在进入递归时标记当前单元格为已访问,并在退出递归时恢复其状态。
以下是 Python 实现:
def exist(board, word):
if not board or not board[0]:
return False
rows, cols = len(board), len(board[0])
def dfs(r, c, index):
# 如果索引达到了单词的长度,说明已经找到了完整的单词
if index == len(word):
return True
# 检查边界条件和字符匹配
if r < 0 or r >= rows or c < 0 or c >= cols or board[r][c] != word[index]:
return False
# 标记当前单元格为已访问
temp, board[r][c] = board[r][c], '#'
# 尝试向四个方向递归搜索
found = (dfs(r + 1, c, index + 1) or
dfs(r - 1, c, index + 1) or
dfs(r, c + 1, index + 1) or
dfs(r, c - 1, index + 1))
# 恢复当前单元格的状态
board[r][c] = temp
return found
# 尝试从每个单元格开始搜索
for r in range(rows):
for c in range(cols):
if dfs(r, c, 0):
return True
return False
进阶优化:搜索剪枝
为了提高效率,可以在搜索过程中加入一些剪枝策略:
- 提前终止:如果在任何时刻发现当前路径不可能形成目标单词,则立即返回
False。 - 预处理:检查网格中是否包含所有需要的字符,以及每个字符的数量是否足够。如果缺少任何一个字符或某个字符的数量不足,则直接返回
False。 - 反向搜索:如果单词的前缀比后缀更频繁出现于网格中,考虑反转单词进行搜索。
- 优化起点选择:优先从那些唯一性较高的字符作为起点开始搜索,减少不必要的遍历。
通过这些优化措施,我们可以显著减少不必要的计算,使算法在更大的输入规模下表现更好。例如,在实际应用中,可以根据具体的数据分布情况调整搜索策略,以获得最佳性能。
提交结果


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











