







最近DeepSeek-R1又爆火了,今天来教大家把DeepSeek - R1装进本地电脑,不用花钱也能使用最火大模型,实现不联网就能随时和AI互动,写文案、聊天、做翻译都不在话下,学生党和上班族都很适用。
首先,我们本地电脑需要有ollama服务,如果没有安装的朋友们,可以参考我另一篇博文,亲测在Windows系统安装、使用、定制Ollama服务,里面有详细介绍怎么安装、配置和使用ollama服务。
有了Ollama服务,我们就可以开始正式配置DeepSeek-R1
一、下载DeepSeek R1模型
我们可以去Ollama官网 Ollama,查找DeepSeek R1,这里可以看到,我还没输入搜索名称,第一位已经列出了DeepSeek R1,可见其火爆程度
我们选择DeepSeek R1,deepseek-r1,进入模型详情页,可以看到各个参数的deepseek-r1模型,
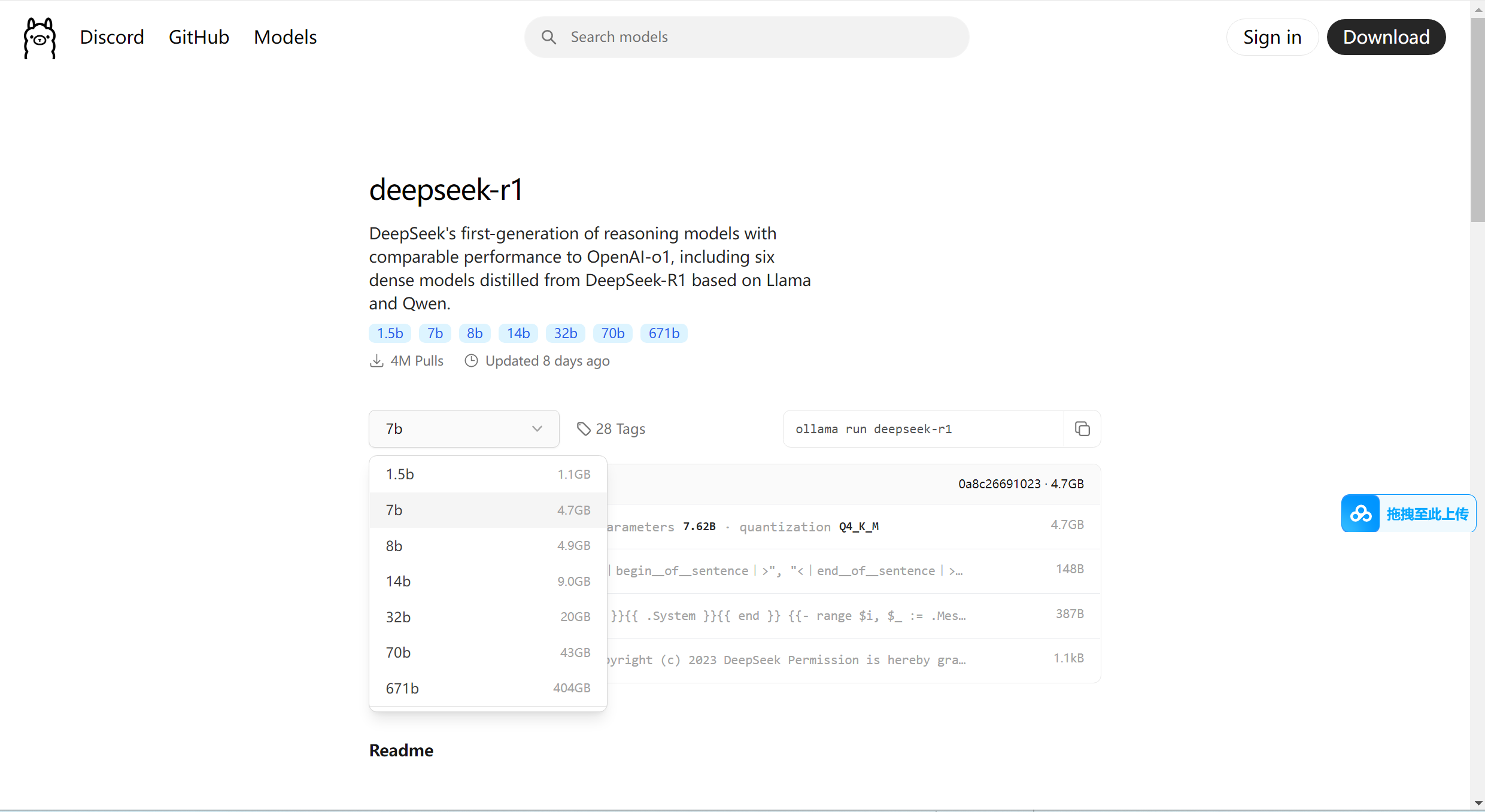
我们选择自己电脑配置合适的,我的电脑是32G内存,8G的4060移动端显卡,理论上是可以运行14B参数的模型的,但是我估计响应体验不会太好,而且我本地还有其他服务在运行,所以就选择7B参数了,默认也是下载7B参数的模型的,我们复制页面上给出的ollama执行命令,即可安装运行模型了
ollama run deepseek-r1其它参数模型可参考下面14B参数模型的命令
ollama run deepseek - r1:14b复制好命令,我们在本地Windows环境电脑打开一个powershell命令窗口,把刚才复制命令粘贴进去执行
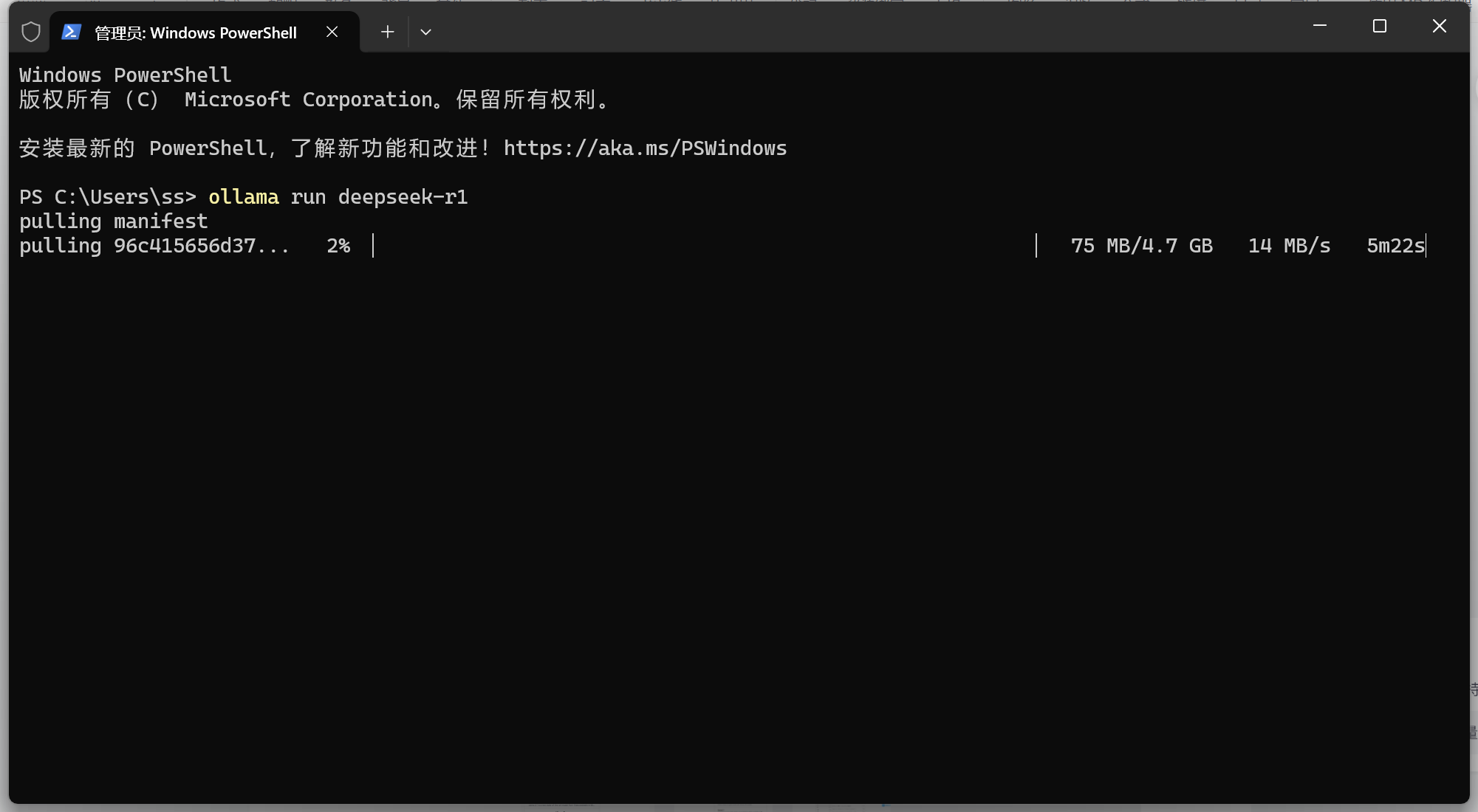
快慢取决于自己电脑的网速,等待模型下载完成,我只用了大概10分钟左右就下载完了
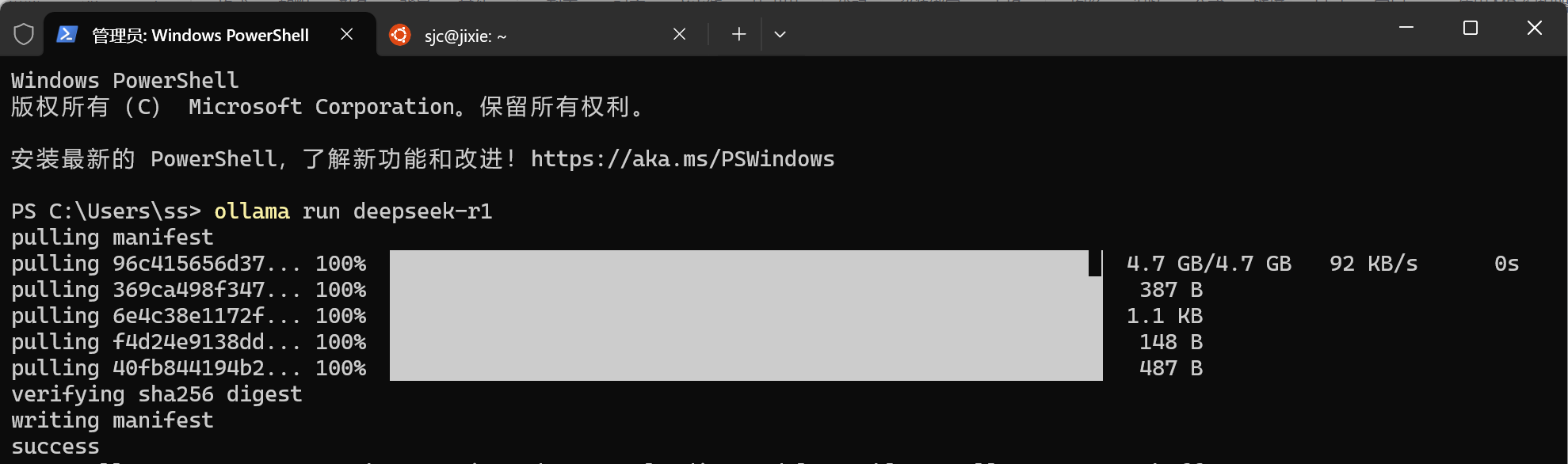
看到成功就说明模型下载好了
二、使用DeepSeek R1模型
下载好了模型,接下来开始使用模型,我们照例使用Dify平台来调用DeepSeek R1,关于Dify平台的介绍和安装也可以参考我的博文 亲测:windows系统本地Docker部署LLM应用开发平台dify+实战详细教程
我们打开Dify平台地址,打开右上角的设置
可以看到我已经配置的一些本地模型,我们点击添加模型按钮,填入ollama对应的模型名称deepseek-r1,和ollama本地运行的URL地址
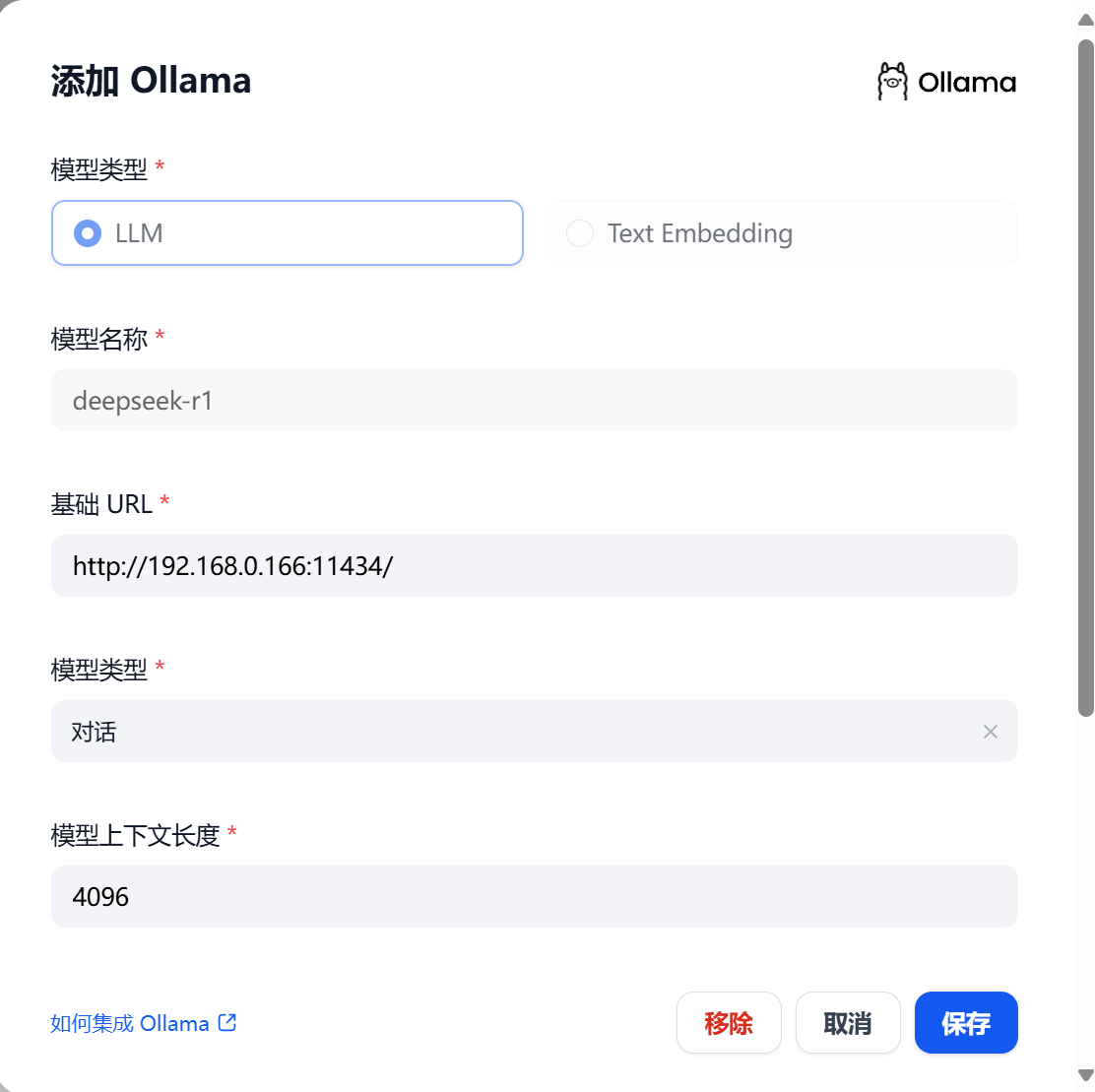
如果保存成功,说明可以访问到本地的deepseek-r1模型了。
开始测试Dify平台调用deepseek-r1模型的整个流程,我们创建一个简单的聊天会话空白应用
进入应用编排界面,我们点击红框的位置,选择我们刚下载和在Dify设置中配好的deepseek-r1模型
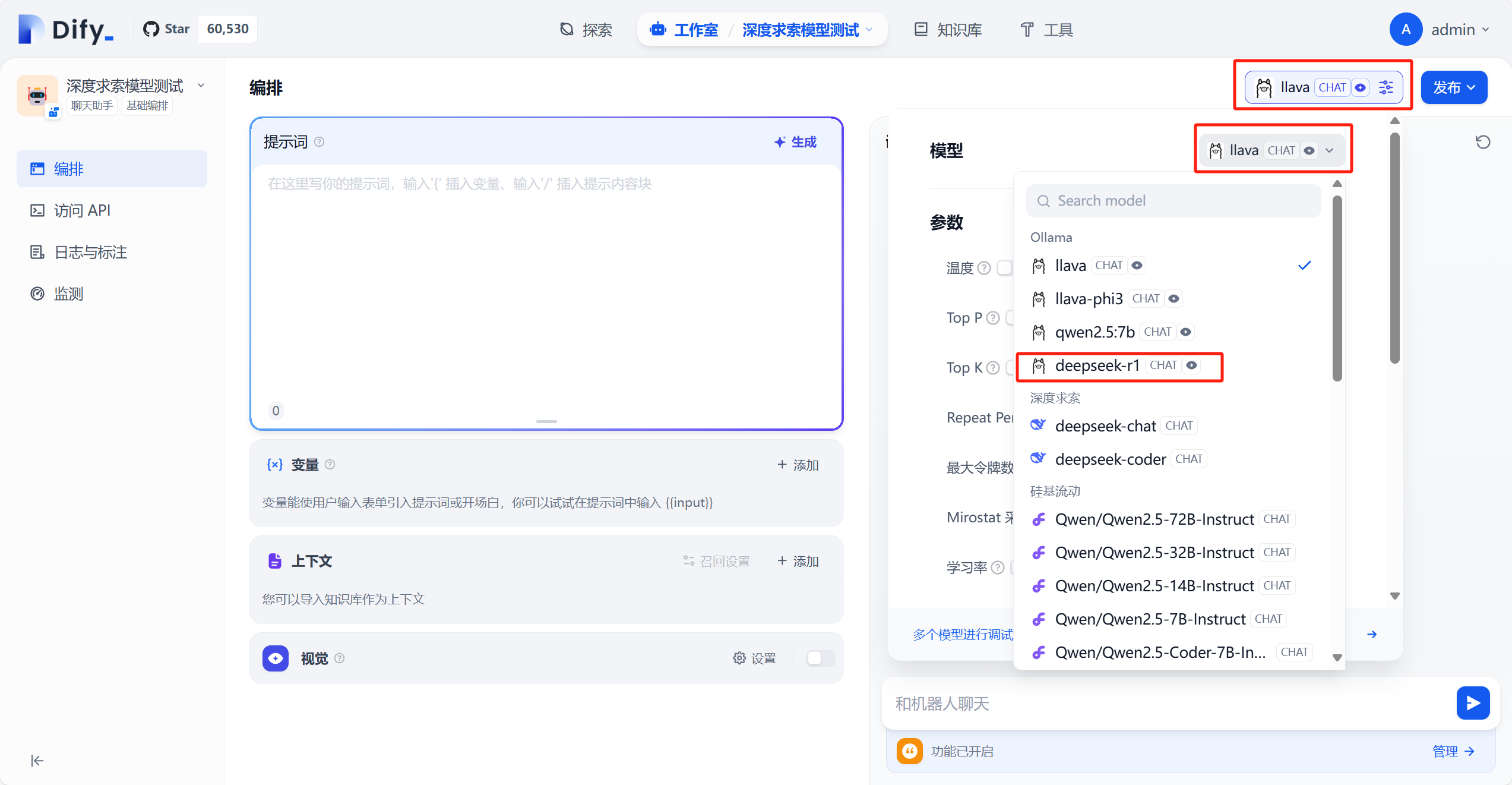
接下来,可以在编排界面的右侧调试应用
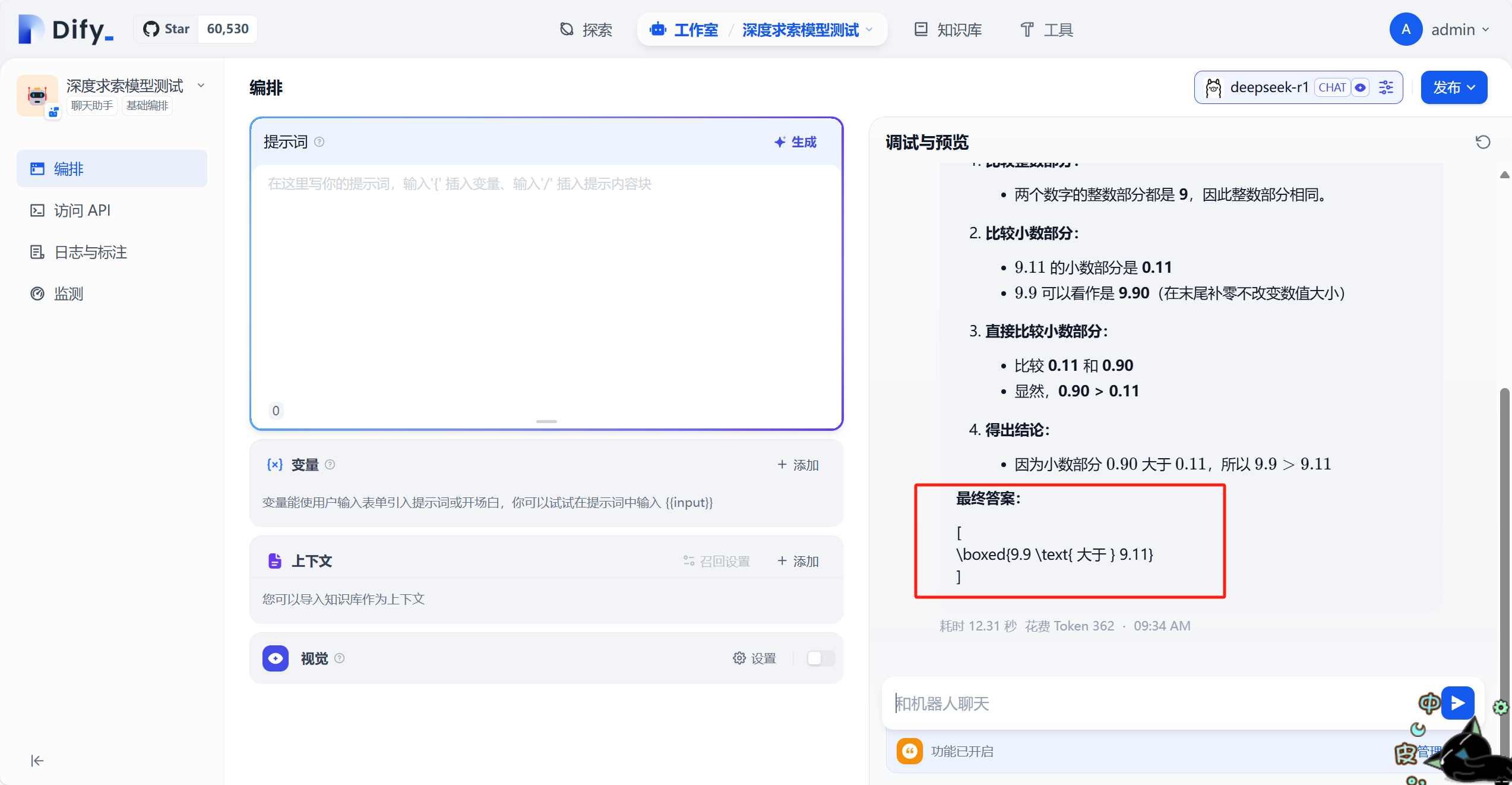
看来r1没犯糊涂,我们发布应用再测试一下
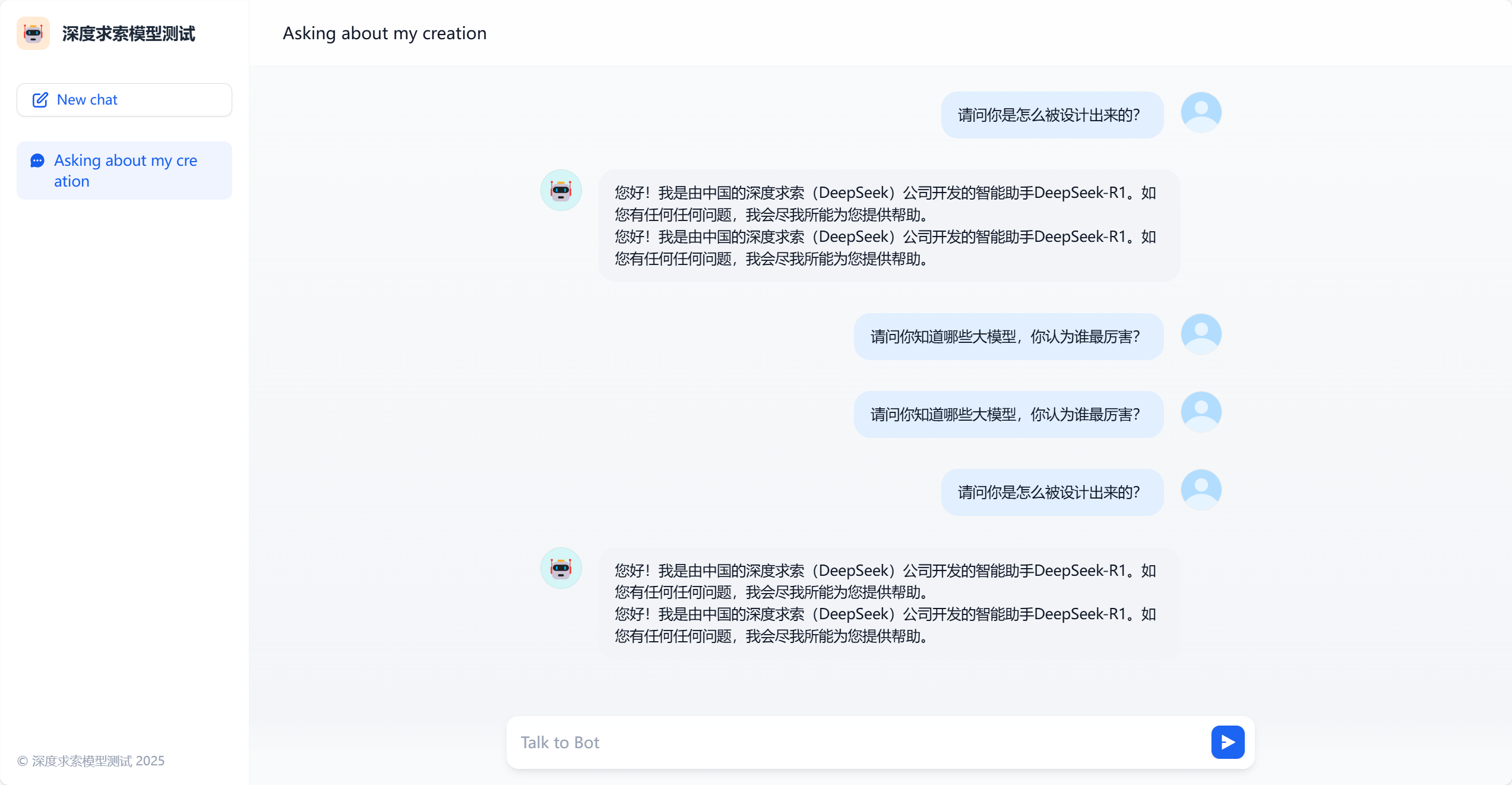
不知道为什么在dify创建的应用回答了2遍,我在powershell交互提问就回答了一次,不过包含部分英文内容

接下来就可以愉快的使用最火爆的deepseek-r1模型,继续AI之旅啦!!!
今天的大模型介绍就到这里了,感谢能看到这里的朋友😉
本次的分享就到这里,【终极量化数据】致力于为大家分享技术干货😎
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正😅
受益的朋友或对技术感兴趣的伙伴记得点赞关注支持一波🙏
也可以搜索关注我的微信公众号【终极量化数据】,留言交流🙏



















 5804
5804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











