



一、问题背景
现在基于RAG的大模型服务太火了。做RAG除了LLM以外,就离不开embedding和rerank模型,因此官方昇腾社区已经更新了相关镜像mis-tei,但是按照指示在服务启动过程中却遇到了一些坑,例如按照如下命令启动容器:
docker run -e ASCEND_VISIBLE_DEVICES=0 -itd --name=tei --net=host \
-v /home/data:/home/HwHiAiUser/model \
-e http_proxy=<ip:port> \
-e https_proxy=<ip:port> \
--entrypoint /home/HwHiAiUser/start.sh \
mis-tei:6.0.RC3-800I-A2-aarch64 BAAI/bge-reranker-large 127.0.0.1 8080
发现容器不能正常启动,docker ps -a显示容器exited,手动启动也没有办法成功。docker logs <container_id>查看显示:
Model 'bge-reranker-large' exists:
/home/HwHiAiUser/start.sh : line 74: npu-smi: commond not found
Available device not found
二、bug解决思路与方案:
1、从log来看,像是容器中没有把昇腾的NPU挂载成功,先更换启动容器脚本,进入容器手动启动.sh文件查看情况。
docker run -e ASCEND_VISIBLE_DEVICES=0 -itd --name=tei --net=host \
-v /home/data:/home/HwHiAiUser/model \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
--entrypoint /bin/bash \
mis-tei:6.0.RC3-800I-A2-aarch64
这时候发现容器可以正常启动,而不是exited了,docker exec -it <容器ID> bash 进入容器后,执行 npu-smi info,这个时候不会再报npu-smi: commond not found错误信息了。
然后手动执行bash /home/HwHiAiUser/start.sh。这时候发现服务log正常打印~~~说明问题就是由于之前的容器启动语句中没有把昇腾的NPU驱动挂载成功导致的。
因此最终简单修改下驱动语句即可:
docker run -u root -e ASCEND_VISIBLE_DEVICES=0 -itd --name=tei --net=host \
-e HOME=/home/HwHiAiUser \
--privileged=true \
-v /home/data:/home/HwHiAiUser/model \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-e http_proxy=<ip:port> \ #网络物理隔离的情况可以省略
-e https_proxy=<ip:port> \ #网络物理隔离的情况可以省略
--entrypoint /home/HwHiAiUser/start.sh \
mis-tei:6.0.RC3-800I-A2-aarch64 BAAI/bge-reranker-large 127.0.0.1 8080
至此,容器可以正常启动,进行测试:
curl 127.0.0.1:8080/rerank \
-X POST \
-d '{"query":"What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]}' \
-H 'Content-Type: application/json'
可正常返回结果。
tips:
(1)提前检查服务端口8080注意不要被别的端口占用,linux系统查看端口占用命令:netstat -tulpn。如果被8080被占用,就更换为其他port,例如2025。
(2)dify如果需要远程登录访问的话,注意IP不要填写127.0.0.1,而是要写embedding或rerank服务所在的服务器IP。否则不能正常访问。
2、dify配置mis-tei的embedding和rerank服务
embedding和rerank服务的设置路径都是:
账户-->设置-->模型供应商-->text embedding inference
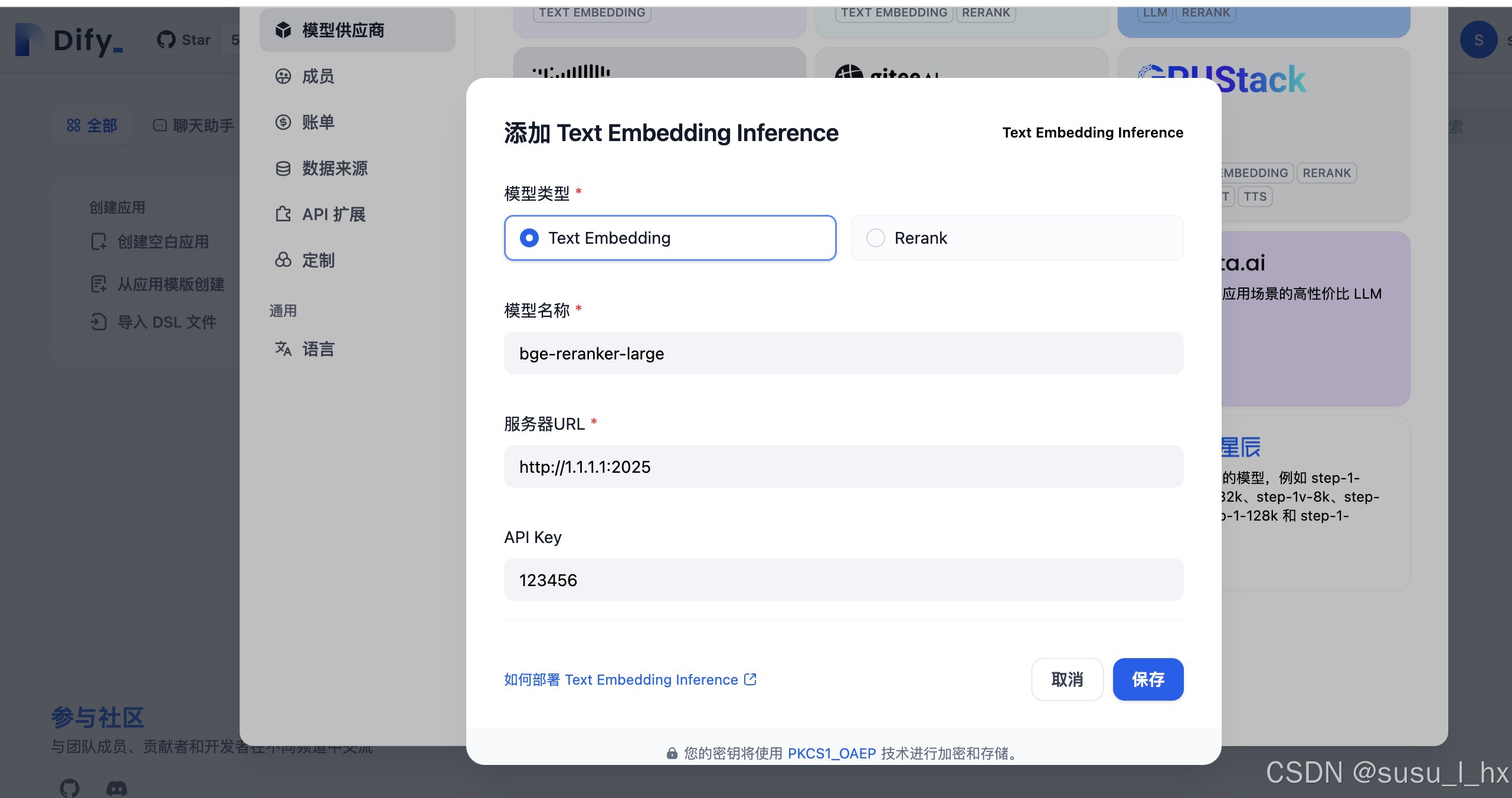
设置embedding服务的时候,如果不写API key会报错,不请是什么问题,这里随便填了一个123456,就设置成功了,很神奇



















 6511
6511







 到【灌水乐园】发言
到【灌水乐园】发言







