




随着生成式大模型(LLM)应用在各类场景中的广泛部署,如何在生产环境中优化大模型推理的效率,已经成为每位AI工程师和开发者面临的重要课题。优化推理不仅可以显著提升用户体验,还能降低运行成本。本文将介绍大模型推理的工作负载、关键性能指标、优化对象、最佳实践和常见问题,帮助普通开发者掌握如何有效提升LLM推理性能。
1. LLM推理的基础概念与优化方向
随着大语言模型(LLM)的广泛应用,开发者们需要理解LLM推理过程中的关键机制及其性能瓶颈。这不仅有助于提升模型的使用效果,还能为优化大模型推理提供有效的指导。为了更好地掌握这一过程,我们将从LLM的推理机制、工作负载、性能测量以及成本与性能优化等多个角度进行详细解读。
1.1 搞懂LLM推理过程
理解LLM推理过程的关键,是掌握模型如何处理输入并生成文本的机制。以下是LLM推理过程的关键环节:
Prompt处理:
当输入提示(prompt)被发送到LLM时,它会经过多个阶段的处理。在GPU上,首先会对输入文本进行token化,将文本转换为模型可以理解的数字表示。这些数字表示称为token,它们代表了文本中的词或子词,每个模型都有自己特定的tokenizer,它会将文本高效地转化为tokens。然后,tokens会被转换为嵌入向量(embedding vectors),这些高维向量承载了每个token的语义信息,为后续计算做好准备。
注意力机制(Attention Mechanism):
推理的关键之一是计算注意力机制。这个机制帮助模型理解各个token之间的关系,从而决定哪些token对生成下一个token最为重要。注意力机制会对输入的所有token进行计算,产生查询(query)、**键(key)和值(value)**矩阵。这个过程对于生成每个token都至关重要,因此计算量大,且对内存有较高的需求。
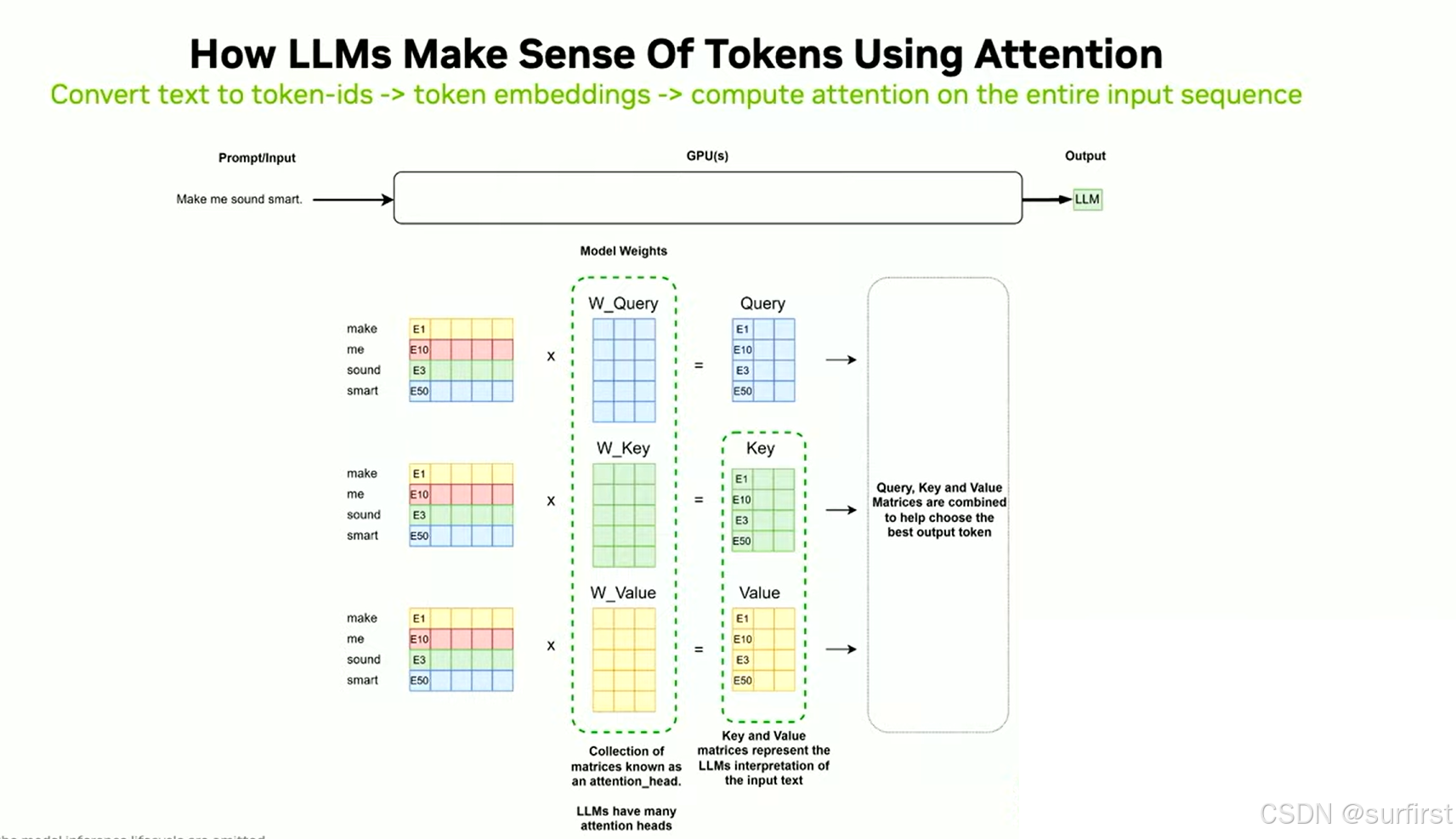
Token生成:
LLM生成文本的过程是逐个token地进行的。初始提示经过处理后,模型会生成下一个token。每个新生成的token不仅依赖当前输入,还会结合先前的生成结果。每生成一个token,模型都会计算一次新的注意力机制,并将生成的token存储到GPU内存中。这个过程会不断重复,直到生成完整的响应。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











