 7种Chunking方法优化RAG系统
7种Chunking方法优化RAG系统





在构建 Retrieval-Augmented Generation(RAG)系统时,如何高效地处理外部知识,是实现强大问答能力的关键。Chunking 是 RAG 技术栈中不可忽视的一环,不仅能提升检索效率,还能增强生成答案的准确性。本文将从 RAG 技术栈的整体架构出发,探讨 Chunking 的重要性,并深入解析 7 种实用的 Chunking 方法,帮助开发者打造更智能的 RAG 应用。
1. RAG 的典型技术栈:Chunking 的核心作用
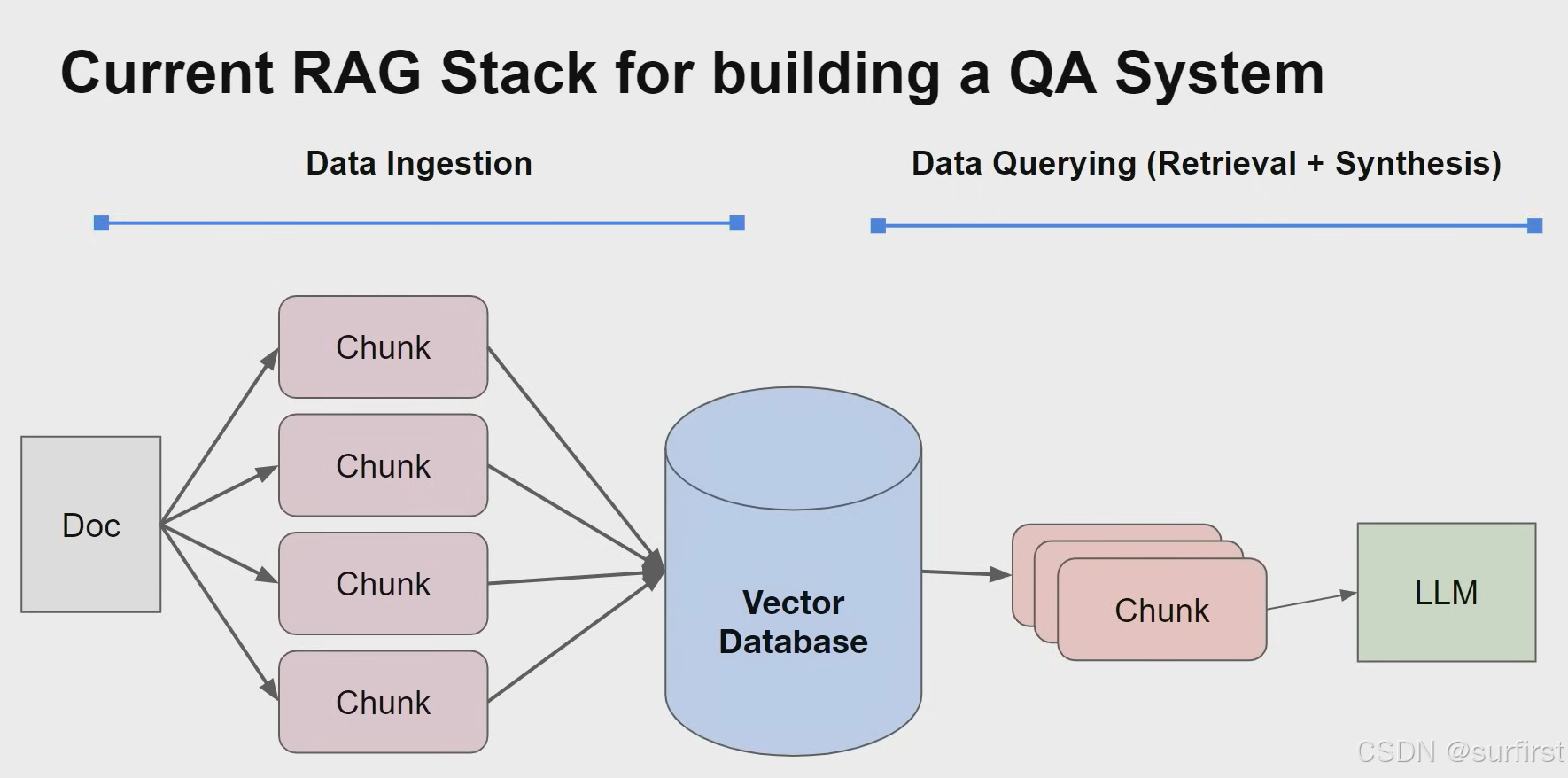
RAG 系统的技术架构通常由两个主要阶段组成:
-
数据摄取(Data Ingestion)
这一阶段处理结构化或非结构化数据,将数据转化为适合存储在向量数据库中的形式。数据的准备工作包括清洗、分词、嵌入等步骤。 -
数据查询(Data Querying)
- 检索(Retrieval):根据用户查询,从向量数据库中提取相关内容,通常采用基于嵌入向量的相似性搜索。
- 合成(Synthesis):将检索到的信息与用户查询结合,传递给 LLM,以生成综合性回答。
在这一过程中,Chunking 是不可或缺的核心步骤。它主要负责将文档拆分成易于处理的小块,每个小块都能单独嵌入向量数据库。这种分块不仅能降低检索复杂度,还能提升与查询的匹配精度。
例如,划分过粗的文档块可能会因信息冗余导致检索无效;而划分过细则可能失去语义上下文。因此,选择合适的 Chunking 策略,是 RAG 系统性能优化的关键。
2. 为什么 Chunking 很重要?
Chunking 是一种优化 RAG 系统文档处理效率的核心技术。它的重要性体现在以下几个方面:
-
控制上下文窗口的长度
LLM 的上下文窗口有限,处理长文档时往往需要裁剪数据。通过合理的分块策略,文档可以在保持语义完整性的同时适配 LLM 的限制。 -
提升检索的精准度
文档分块后,向量数据库可以高效地对比用户查询的嵌入向量与分块后的嵌入向量,确保更高的匹配相关性。 -
平衡语义完整性与信息粒度
Chunking 的核心挑战是平衡语义完整性与信息粒度。块太大可能包含无关信息,块太小则容易丢失上下文。一个成功的 Chunking 策略,必须适配特定的使用场景。 -
元数据的结合使用
Chunking 还能与元数据结合,通过文档标记、分类等方式进一步提高检索效率。例如,在处理分块后的内容时,可以使用元数据过滤搜索空间,缩小结果范围。
正如 Pinecone 的开发者倡导者 Roie Schwaber-Cohen 所言:“Chunking 的质量直接决定了检索结果的相关性与生成内容的可靠性。” Pinecone 是全球领先的向量数据库提供商之一
3. 7 种高效 Chunking 方法详解
3.1 基于句子的分割
-
描述:
这是最简单的 Chunking 方法之一,通过分析句子的边界(如标点符号)将文档按句子划分为独立块。由于句子是语义上的基本单位
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











