







一、RAG基础了解
欢迎大家微信搜索“AIGCmagic”关注公众号,回复“大模型”,加入大模型&GPT技术交流群,一起交流学习。
1.1、什么是RAG?
RAG (Retrieval-Augmented Generation) 是一种结合了检索和生成两种方法的自然语言处理(NLP)技术。它通过先检索相关的文档或信息,再使用生成模型(如GPT-3)生成答案。这种方法在处理需要丰富背景信息的问题时特别有效。
RAG不仅仅面向文本,它还可以面向语音、视频和图像等多模态场景,只要可以embedding的内容就可以。
RAG的主要流程如下:
-
检索(Retrieval):首先从一个大型文本数据库中检索出与问题相关的文档。这一步通常使用一种检索模型,如BM25或DPR(Dense Passage Retrieval)。
-
生成(Generation):接下来,将检索到的文档与问题一起输入到生成模型中,生成最终的答案。生成模型会根据检索到的文档内容生成一个连贯且有意义的回答。
这种方法的优点是它结合了检索和生成的优势,使得生成的答案不仅有语言上的流畅性,还能够基于实际的文档内容提供更准确和具体的信息。这在处理复杂的问答任务时特别有用,例如需要引用具体事实或数据的情况。
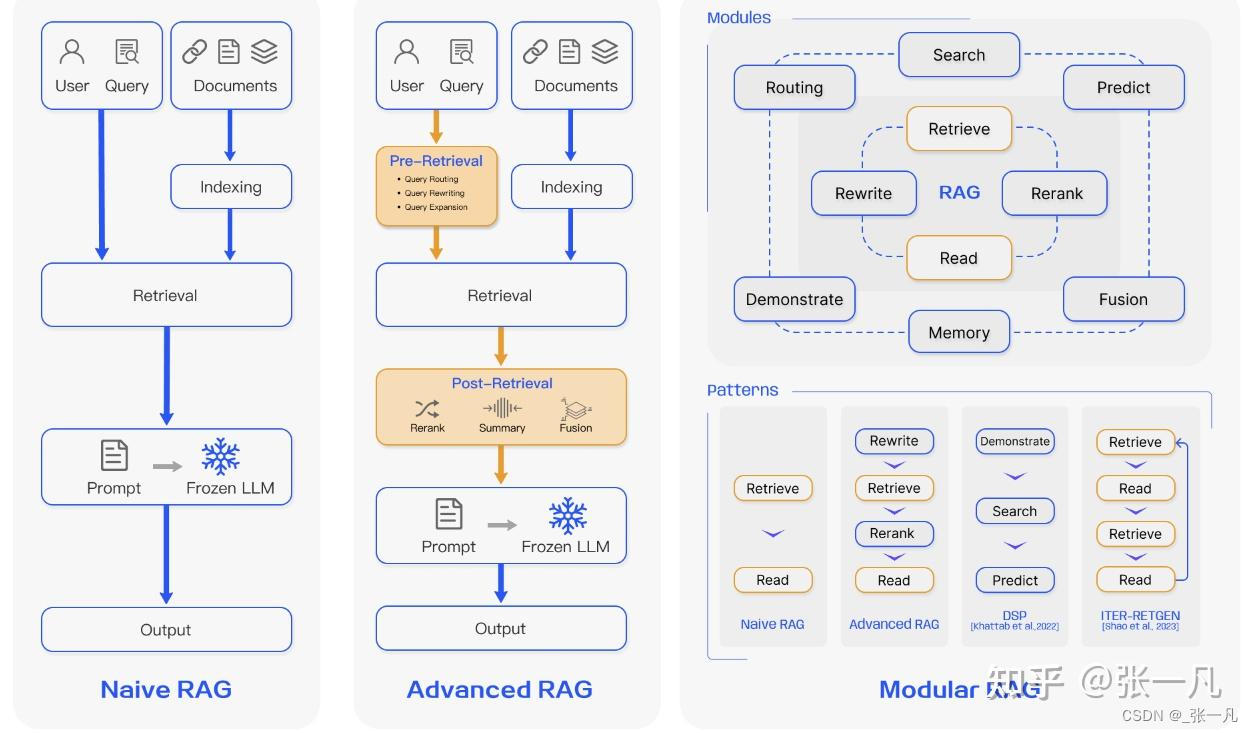
1.2、RAG文档召回率是什么?
RAG(Retrieval-Augmented Generation)中的文档召回率(Document Recall)是指在检索阶段,模型能够成功找到与用户查询相关的所有文档的比例。具体来说,它衡量的是在所有相关文档中,有多少被成功检索到了。
文档召回率是评估检索系统性能的重要指标。它可以用以下公式计算:

在RAG中,文档召回率的高低直接影响生成模型的表现。如果召回率低,生成模型可能会缺乏足够的背景信息,从而影响答案的准确性和相关性。
要提高文档召回率,可以采取以下措施:
-
改进检索模型:使用更先进的检索模型,如Dense Passage Retrieval (DPR) 或改进BM25算法,来提高相关文档的检索效果。
-
扩展检索范围:增加知识库的规模和多样性,以确保包含更多潜在相关文档。
-
优化检索策略:调整检索策略,使用多轮检索或结合多个检索模型的结果,来提高召回率。
高召回率可以确保生成模型有更丰富的信息源,从而提高最终生成答案的准确性和可靠性。
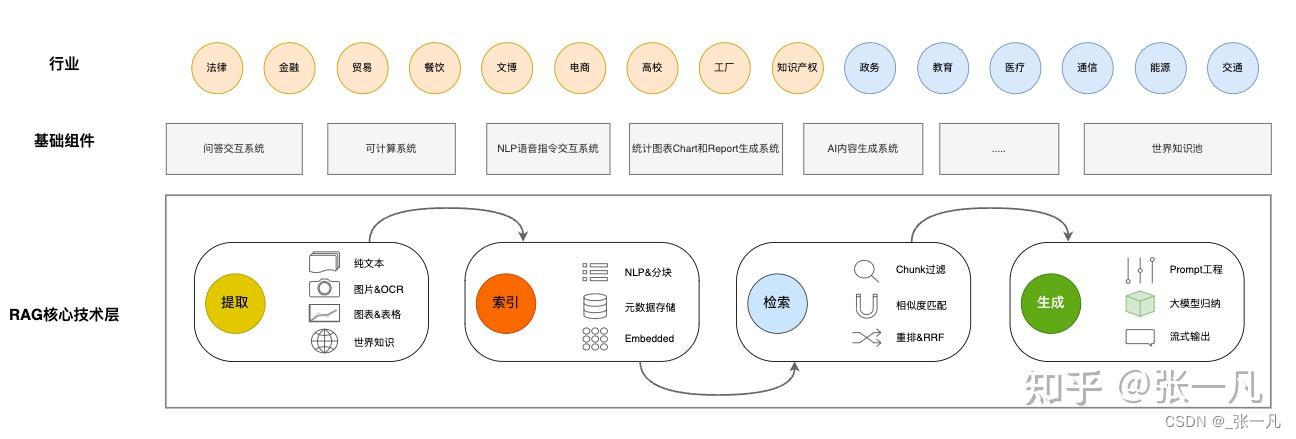
1.3、RAG在各行业业务场景中的需求分析
目前能涉及到RAG的行业有:金融、法律、生产型工厂、贸易公司、电商、餐饮、知识产权和文旅政务、医疗、通信、能源、教育(非义务教育)和交通等行业。
初期大部分还是根据已有文档,建立知识对话系统。也有一些企业让大模型参与到决策系统中来。
1.4、RAG技术的难点
(1)数据处理
目前的数据文档种类多,包括doc、ppt、excel、pdf扫描版和文字版。ppt和pdf中包含大量架构图、流程图、展示图片等都比较难提取。而且抽取出来的文字信息,不完整,碎片化程度比较严重。
而且在很多时候流程图,架构图多以形状元素在PPT中呈现,光提取文字,大量潜藏的信息就完全丢失了。
(2)数据切片方式
不同文档结构影响,需要不同的切片方式,切片太大,查询精准度会降低,切片太小一段话可能被切成好几块,每一段文本包含的语义信息是不完整的。
(3)内部知识专有名词不好查询
目前较多的方式是向量查询,对于专有名词非常不友好;影响了生成向量的精准度,以及大模型输出的效果。
(4)新旧版本文档同时存在
一些技术报告可能是周期更新的,召回的文档如下就会出现前后版本。
(5)复杂逻辑推理
对于无法在某一段落中直接找到答案的,需要深层次推理的问题难度较大。
(6)金融行业公式计算
如果需要计算行业内一些专业的数据,套用公式,对RAG有很大的难度。
(7)向量检索的局限性
向量检索是基于词向量的相似度计算,如果查询语句太短词向量可能无法反映出它们的真实含义,也无法和其他相关的文档进行有效的匹配。这样就会导致向量检索的结果不准确,甚至出现一些完全不相关的内容。
(8)长文本
(9)多轮问答
1.5、RAG的架构
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6?gi=0eea544f219a
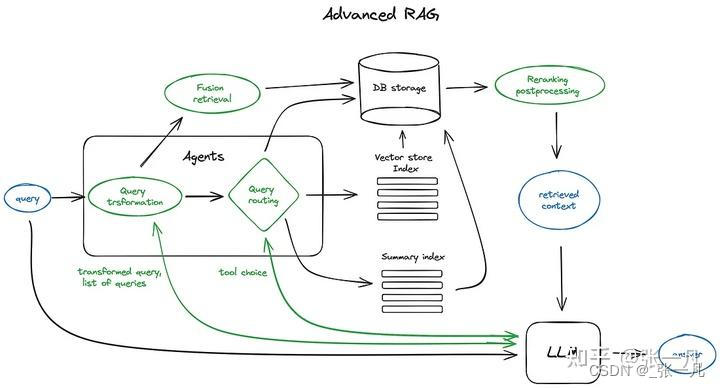
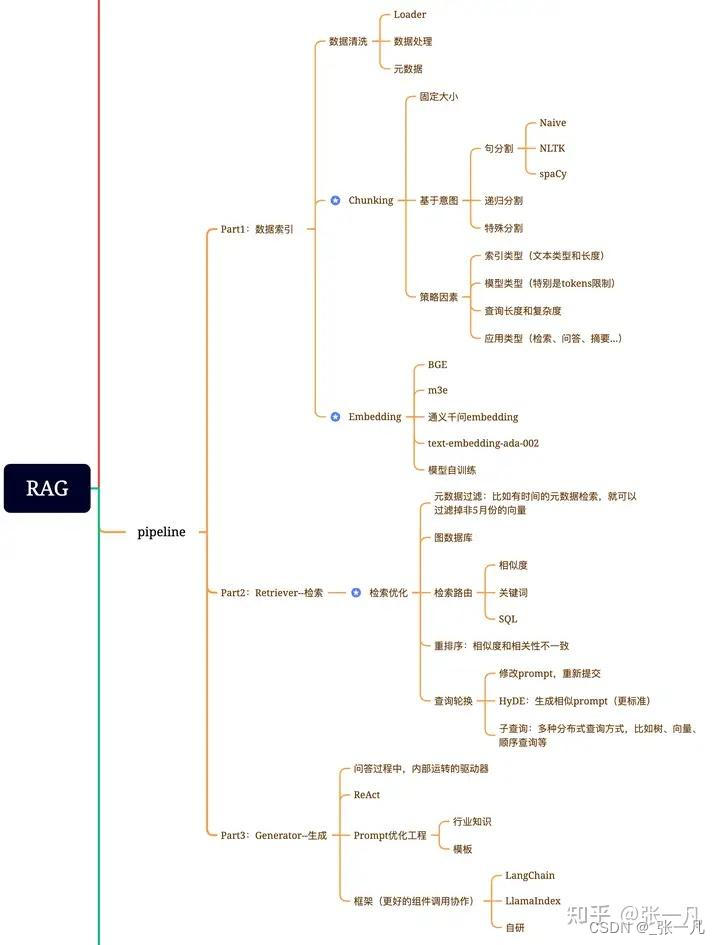
1.6、RAG存在的一些问题和避免方式
(1)分块(Chunking)策略以及Top-k算法
一个成熟的RAG应该支持灵活的分块,并且可以添加一点重叠以防止信息丢失。用固定的、不适合的分块策略会造成相关度下降。最好是根据文本情况去适应。或者是在定位到关键语句以后进行上下文进行扩充,然后进行重排序。
在大多数设计中,top_k是一个固定的数字。因此,如果块大小太小或块中的信息不够密集,我们可能无法从向量数据库中提取所有必要的信息。
(2)世界知识缺失
比如我们正在构建一个《西游记》的问答系统。我们已经把所有的《西游记》的故事导入到一个向量数据库中。现在,我们问它:人有几个头?
最有可能的是,系统会回答3个,因为里面提到了哪吒有“三头六臂”,也有可能会说很多个,因为孙悟空在车迟国的时候砍了很多次头。而问题的关键是小说里面不会正儿八经地去描述人有多少
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









